sql server 分区(上)
Posted lonelyxmas
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql server 分区(上)相关的知识,希望对你有一定的参考价值。
原文:sql server 分区(上)分区发展历程
基于表的分区功能为简化分区表的创建和维护过程提供了灵活性和更好的性能。追溯到逻辑分区表和手动分区表的功能.
二.为什么要进行分区
为了改善大型表以及具有各种访问模式的表的可伸缩性和可管理性。
大型表除了大小以数百 GB 计算,甚至以 TB 计算的指标外,还可以是无法按照预期方式运行的数据表,运行成本或维护成本超出预定要求。例如发生性能问题、阻塞问题、备份。
三. 分区的概念
分区范围
分区范围是指在要分区的表中,根据业务选择表中的关键字段做为分区边界条件,
分区后,数据所在的具体位置至关重要,这样才能在需要时只访问相应的分区。
注意分区是指数据的逻辑分离,不是数据在磁盘上的物理位置, 数据的位置由文件组来决定,所以一般建议一个分区对应一个文件组。
分区键
在我下面的演示中,有一个库存表,我选择了UpByMemberID(会员ID) 作为分区键。 对表和索引进行分区的第一步就是定义分区的关键数据。
索引分区
除了对表的数据集进行分区之外,还可以对索引进行分区, 使用相同的函数对表及其索引进行分区通常可以优化性能
在下面的第六步中有创建分区索引。
三.创建分区实现
在test库 添加四个文件组, 用于存储每个分区的数据,这里有四个文件组对应四个分区
多个文件组是为了有助于优化性能和维护,应使用文件组分离数据。文件组的数目一定程度上由硬件资源决定:一般情况下,文件组数最好与分区数相同,
并且这些文件组通常位于不同的磁盘上(演示有条有限,只在一个磁盘上做逻辑盘存放)。
1 --第一步:创建四个文件组 2 alter database test add filegroup ByIdGroup1 3 alter database test add filegroup ByIdGroup2 4 alter database test add filegroup ByIdGroup3 5 alter database test add filegroup ByIdGroup4
--第二步: 创建四个ndf文件,对应到各文件组中,FILENAME文件存储路径 ALTER DATABASE test ADD FILE( NAME=‘File1‘, FILENAME=‘C:\\Program Files\\Microsoft SQL Server\\MSSQL10.MSSQLSERVER\\MSSQL\\DATA\\testFile1.ndf‘, SIZE=5MB, FILEGROWTH=5MB) TO FILEGROUP ByIdGroup1 ALTER DATABASE test ADD FILE( NAME=‘File2‘, FILENAME=‘E:\\testFile2.ndf‘, SIZE=5MB, FILEGROWTH=5MB) TO FILEGROUP ByIdGroup2 ALTER DATABASE test ADD FILE( NAME=‘File3‘, FILENAME=‘E:\\testFile3.ndf‘, SIZE=5MB, FILEGROWTH=5MB) TO FILEGROUP ByIdGroup3 ALTER DATABASE test ADD FILE( NAME=‘File4‘, FILENAME=‘E:\\testFile4.ndf‘, SIZE=5MB, FILEGROWTH=5MB) TO FILEGROUP ByIdGroup4
执行完成后,查看如下图所示:
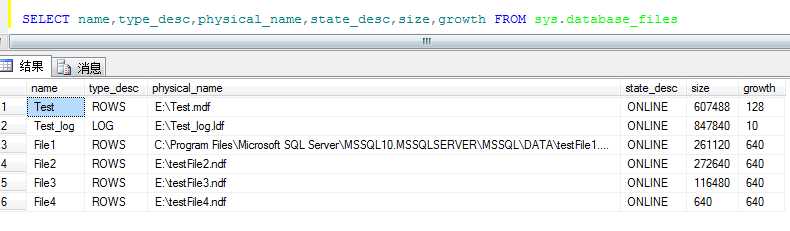
--第三步:创建分区函数(每个分区的边界值)
每个会员统计的产品数
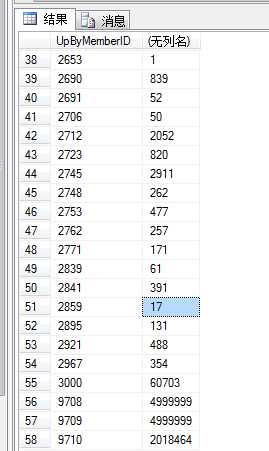
--record: 126797 Partition1 --PRIMARY SELECT COUNT(1) FROM dbo.Product WHERE UpByMemberID<=1740 --record: 90882 Partition2 SELECT COUNT(1) FROM dbo.Product WHERE UpByMemberID>1740 AND UpByMemberID<=3000 --record: 4999999 Partition3 SELECT COUNT(1) FROM dbo.Product WHERE UpByMemberID>3000 AND UpByMemberID<=9708 --record: 4999999 Partition4 SELECT COUNT(1) FROM dbo.Product WHERE UpByMemberID>9708 AND UpByMemberID<=9709 --record: 2018464 Partition5 ---ByIdGroup4 SELECT COUNT(1) FROM dbo.Product WHERE UpByMemberID>9709 CREATE PARTITION FUNCTION pf_UpByMemberID(int) AS RANGE LEFT FOR VALUES (1740,3000,9708,9709)
执行完后如下图所示:
--第四步:创建分区方案
CREATE PARTITION SCHEME ps_UpByMemberID AS PARTITION pf_UpByMemberID TO ([PRIMARY], [ByIdGroup1],[ByIdGroup2],[ByIdGroup3],[ByIdGroup4])
执行完后如下图所示:
--第五步:创建分区表
右击要分区的表-->存储-->创建分区-->选择分区列(这里UpByMemberID)-->选择分区函数
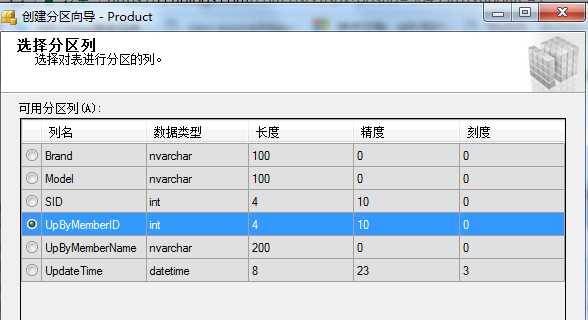
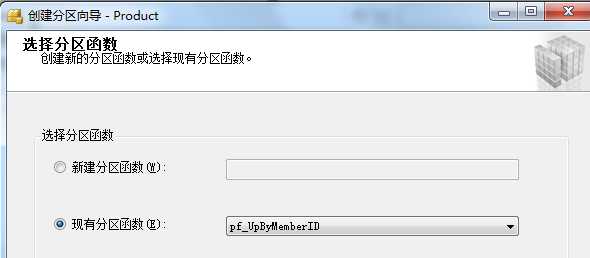
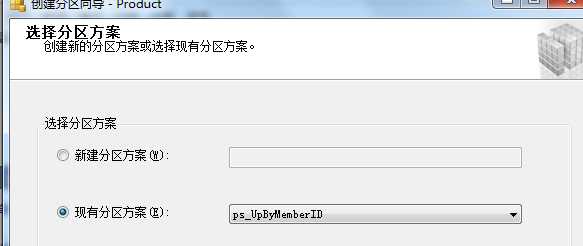
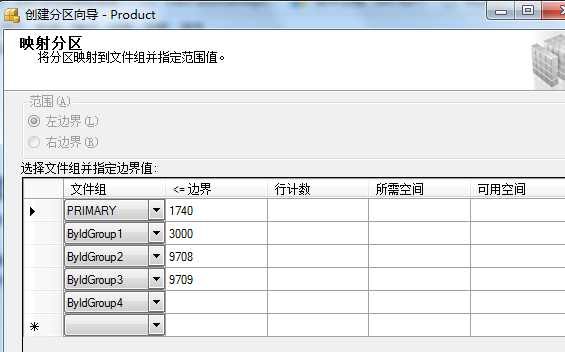
--第六步创建分区索引
CREATE NONCLUSTERED INDEX [ixUpByMemberID] ON [dbo].[Product] ( [UpByMemberID] ASC ) INCLUDE ( [Model]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO
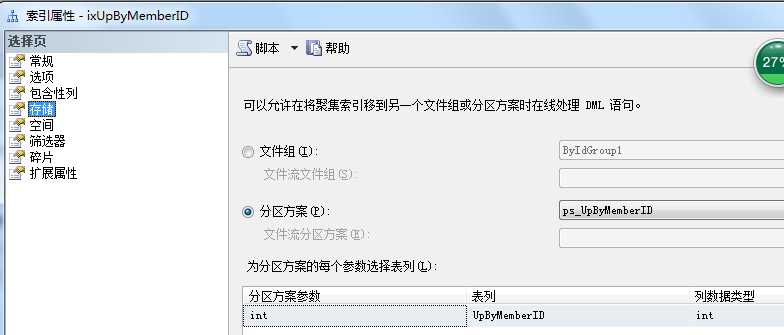
-- 最后 查看各分区有多少行数据 select $PARTITION.pf_UpByMemberID([UpByMemberID]) as Patition,COUNT(*) countRow from dbo.product group by $partition.pf_UpByMemberID([UpByMemberID])
查出有五个分区(带主分区),以及各分区的数量
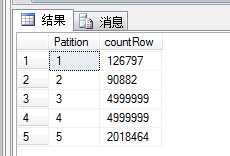
最后看下是否用了分区索引
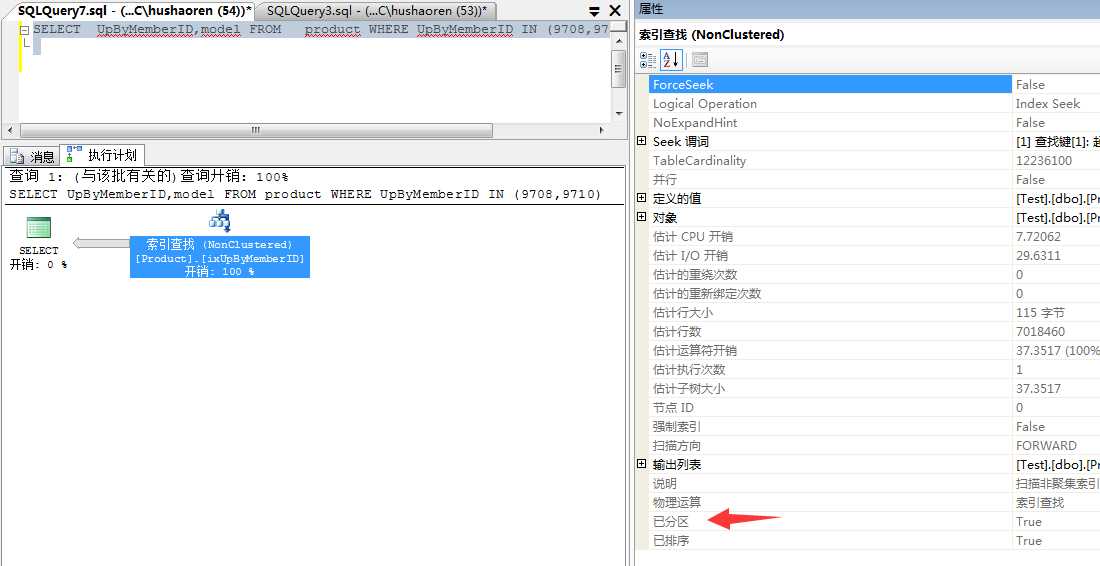
sql server 分区的优势:
- 当表和索引变得非常大时,分区可以将数据分为更小、更容易管理的部分。
- 减少索引维护时间。
- 常用的where条件字段做分区依据是较佳的。
- 并行操作获得更好的性能, 可以改善在极大型数据集(例如数百万行)中执行大规模操作的性能。
- 一般情况下,文件组数最好与分区数相同。文件组允许您将各个表放置到不同的物理磁盘上
以上是关于sql server 分区(上)的主要内容,如果未能解决你的问题,请参考以下文章
使用实体框架迁移时 SQL Server 连接抛出异常 - 添加代码片段