SQL Server 2008 分区函数和分区表
Posted Avatarx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL Server 2008 分区函数和分区表相关的知识,希望对你有一定的参考价值。
当我们数据量比较大的时候,我们需要将大型表拆分为多个较小的表,则只访问部门数据的查询就可以更快的运行,基本原理就是,因为要扫描的数据变的更小。维护任务(例如,重新生成索引或备份表)也可以更快的运行。
我们可以再不通过将表物理放置在多个磁盘驱动器上来拆分表的情况下获取分区。如果将某个表放置在一个物理驱动器上,将相关表放置在另一个驱动器上,则可以提高查询性能,因为当运行涉及表间连接的查询时,多个磁盘头同时读取数据。可以使用SQL Server文件组来指定放置表的磁盘。
对于分区的方式,基本就三种方式:硬件分区、水平分区、垂直分区。相关方案可以参考SQL联机丛书
这里我们介绍分区表的具体实战方法:
第一步,首先建立我们要使用的数据库,最重要的是建立多个文件组。
我们先新建立四个目录,来组成文件组,一个用来存放主文件的目录:Primary
三个数据文件目录:FG1、FG2、FG3
建立库:

create database Sales on primary ( name=N\'Sales\', filename=N\'G:\\data\\Primary\\Sales.mdf\', size=3MB, maxsize=100MB, filegrowth=10% ), filegroup FG1 ( NAME = N\'File1\', FILENAME = N\'G:\\data\\FG1\\File1.ndf\', SIZE = 1MB, MAXSIZE = 100MB, FILEGROWTH = 10% ), FILEGROUP FG2 ( NAME = N\'File2\', FILENAME = N\'G:\\data\\FG2\\File2.ndf\', SIZE = 1MB, MAXSIZE = 100MB, FILEGROWTH = 10% ), FILEGROUP FG3 ( NAME = N\'File3\', FILENAME = N\'G:\\data\\FG3\\File3.ndf\', SIZE = 1MB, MAXSIZE = 100MB, FILEGROWTH = 10% ) LOG ON ( NAME = N\'Sales_Log\', FILENAME = N\'G:\\data\\Primary\\Sales_Log.ldf\', SIZE = 1MB, MAXSIZE = 100MB, FILEGROWTH = 10% ) GO
第二步:建立分区函数,目的是用来规范不同数据存放到不同目录的标准,简单讲就是如何分区。
USE Sales GO CREATE PARTITION FUNCTION pf_OrderDate (datetime) AS RANGE RIGHT FOR VALUES (\'2003/01/01\', \'2004/01/01\') GO
我们创建了一个用于数据类型为datetime的分区函数,按照时间段来划分
文件组 分区 取值范围
FG1 1 (过去某年, 2003/01/01)
FG2 2 [2003/01/01, 2004/01/01)
FG3 3 [2004/01/01,未来某年)
第三步:创建分区方案,关联到分区函数。目的就是我们将已经建立好的分区函数组织成一套方案,简单点将就是我们在哪里对数据进行分区。
Use Sales go create partition scheme ps_OrderDate as partition pf_OrderDate to(FG2,FG2,FG3) go
很简单,就是将第二步建立的分区函数应用已经建立的分区组中。
第四步:创建分区表。创建表并将其绑定到分区方案上。我们首先建立两个表,一张原始表另一张用来归档数据,保存归档数据。
Use Sales go create table Orders ( OrderID int identity(10000,1), OrderDate datetime not null, CustomerID int not null, constraint PK_Orders primary key(OrderID,OrderDate) ) on ps_OrderDate(OrderDate) go create table OrdersHistory ( OrderID int identity(10000,1), OrderDate datetime not null, CustomerID int not null, constraint PK_OrdersHistory primary key(OrderID,OrderDate) ) on ps_OrderDate(OrderDate) go
到这里,通过上面的四步我们已经完整的搭建好了一个带有分区表的库,我们来插入一些数据,来测试下我们建立是否好用。
首先,因为是用2003年1月1号作为区分点的,我们先向数据表中写入2002年的规范数据
USE Sales GO INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES (\'2002/6/25\', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES (\'2002/8/13\', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES (\'2002/8/25\', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES (\'2002/9/23\', 1000) GO
同样我们写入2003年四条数据
USE Sales GO INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES (\'2003/6/25\', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES (\'2003/8/13\', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES (\'2003/8/25\', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES (\'2003/9/23\', 1000) GO
我们来查看这些数据是否完整录入:
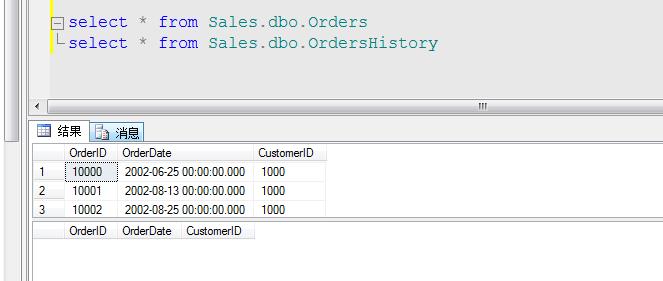
因为OrdersHistory表我们还没有归档数据,所以为空。
我们来分条件查询下:
1、查询某个分区
这里我们要用到$partition函数。这个函数在联机丛书中是这样解释的:
用法: 为任何指定的分区函数返回分区号,一组分区列值将映射到该分区号中。 语法: [ database_name. ] $PARTITION.partition_function_name(expression) 参数: database_name 包含分区函数的数据库的名称。 partition_function_name 对其应用一组分区列值的任何现有分区函数的名称。 expression 其数据类型必须匹配或可隐式转换为其对应分区列数据类型的表达式。expression 也可以是当前参与 partition_function_name 的分区列的名称。 返回类型: int 备注: $PARTITION 返回从 1 到分区函数的分区数之间的 int 值。 $PARTITION 将针对任何有效值返回分区号,无论此值当前是否存在于使用分区函数的分区表或索引中。
我们来查询分区表Order的第一个分区,代码如下: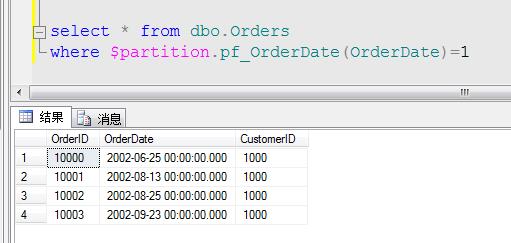
可以看到我们查询出来的数据全部为2002年的,也就是说在第一分区中我们存入的数据都是小于2003年,按照此推断2003年的数据,就应该存在第二分区中:
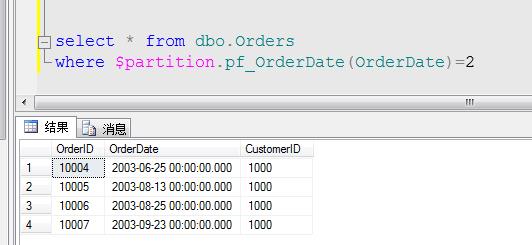
结果如我们所料,我们可以按照这个分区进行分组来查看各个分区的数据行多少,代码如下:
select $partition.pf_OrderDate(OrderDate) as Patition,COUNT(*) countRow from dbo.Orders group by $partition.pf_OrderDate(OrderDate)
还可以通过$Partition函数获得一组分区标识列值的分区号,例如获得2002属于哪个分区,代码如下:
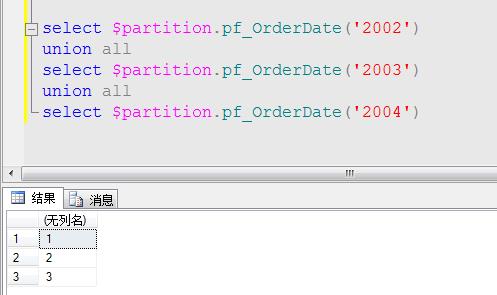
2、归档数据
假如现在是2003年年初,那么我们就可以把2002您所有的交易记录归档到我们刚才建立的历史订单表HistroryOrder中。代码如下:
Use Sales go alter table orders switch partition 1 to ordersHistory partition 1 go
现在我们再重新查看这两张表的数据:
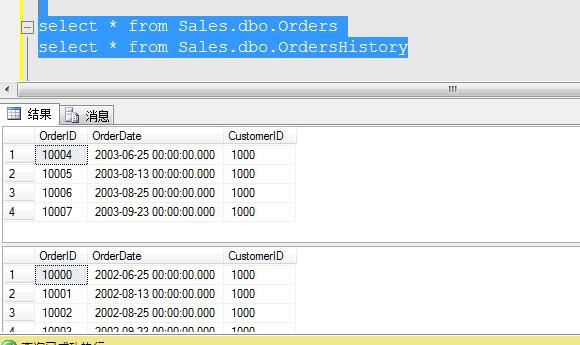
这时候Orders表只剩下2003年的数据,而OdersHistory表中包含了2002年的数据。
简单点讲就是把第一区的数据导入到另一张分区表的第一区中
当然如果到了2004年年初,我们就可以归档2003年的所有交易数据。
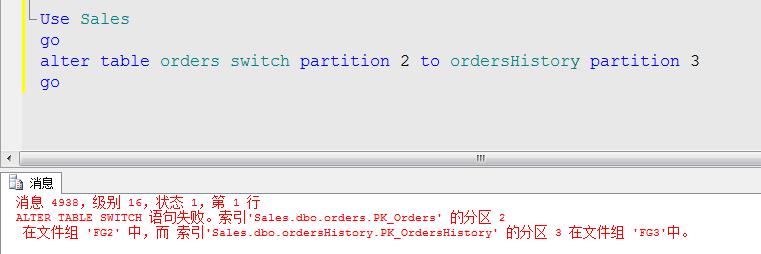
Use Sales go alter table orders switch partition 2 to ordersHistory partition 2 go
这里需要注意的是我们按照区进行数据修改的时候,必须是同一种分区函数下的分区表进行操作,并且分区结构相对应,如果不这样会报错,例如:
3、添加分区
当我们需要新添加分区的时候,我们需要修改分区方案,比如现在我们到了2005年年初,我们需要为2005年的交易记录准备分区,就需要添加分区:
USE [master] GO ALTER DATABASE [Sales] ADD FILEGROUP [FG4] GO ALTER DATABASE [Sales] ADD FILE ( NAME = N\'File4\', FILENAME = N\'G:\\data\\FG4\\File4.ndf\' , SIZE = 3072KB , FILEGROWTH = 1024KB ) TO FILEGROUP [FG4] GO
我们新建立了一个文件组,然我们同样按照上面的方法,进行修改分区函数和方案:
use Sales go alter partition scheme ps_OrderDate next used [FG4] alter partition function pf_OrderDate() split range(\'2005/01/01\') go
我们这里用alter partition Scheme ps_OrderDate Next Used FG4用来指定新分区的数据在那个文件。这里Next Used FG4指定的就是我们刚才新建立的第四个文件组。当然我们可以放在原来已经建立的文件组,为了防治数据混乱存放我们大部分是新建立文件组。
alter partition function pf_OrderDate() split range(\'2005/01/01\')代表我么创建一个新分区,而这里split range是创建新分区的关键语法。
至此,我们就有了四个分区,此时的区间如下:
文件组 分区 取值范围
FG1 1 (过去某年, 2003/01/01)
FG2 2 [2003/01/01, 2004/01/01)
FG3 3 [2004/01/01,2005/01/01]
FG4 4 [2004/01/01,未来某年)
4、删除分区
删除分区又称合并分区,简单讲就是两个分区的数据进行合并,比如我们想合并2002年的分区和2003年的分区到一个分区,我们可以用如下的代码:
use Sales go alter partition function pf_OrderDate() merge range(\'2003/01/01\') go
也就是将2003年这个分区点去掉,里面分区里面的数据会自动合并到一起。
执行完上面的代码,此时分区区间如下:
文件组 分区 取值范围
Fg2 1 [过去某年, 2004/01/01)
Fg3 2 [2004/01/01, 2005/01/01)
Fg2 3 [2005/01/01, 未来某年)
合并2002和2003年的数据到2003年之后,我们执行如下代码:
SELECT Sales.$PARTITION.pf_OrderDate(\'2003\')
你会发现返回的结果是1。而原来返回的是2,原因是2002年以前数据所在的那个分区合并到了2003年这个分区中了。
此时我们执行下面代码:
SELECT * FROM dbo.OrdersHistory WHERE $PARTITION.pf_OrderDate(OrderDate) = 2
结果一行数据都没返回,事实就这样,因为OrderHistroy表中只存储了2002和2003年的历史数据,在没有合并分区之前,执行上面的代码肯定会查询出2003年的数据,但是合并了分区之后,上面代码实际查询的是第二个分区中2004年的数据。
不过我们改成如下代码:
SELECT * FROM dbo.OrdersHistory WHERE $PARTITION.pf_OrderDate(OrderDate) = 1
便会查询出8行数据,包括2002年和2003年的数据,因为合并分区后2002年和2003年的数据都成了第1分区的数据了。
5、查看元数据
我们可以通过三个系统视图来查看我们的分区函数,分区方案,边界值点等。
select * from sys.partition_functions select * from sys.partition_range_values select * from sys.partition_schemes
以上是关于SQL Server 2008 分区函数和分区表的主要内容,如果未能解决你的问题,请参考以下文章
SQL Server 2008如何创建分区表,并压缩数据库空间