怎样用Excel做关键词的词频统计
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎样用Excel做关键词的词频统计相关的知识,希望对你有一定的参考价值。
有大量关键词需要分析,要做到二项集
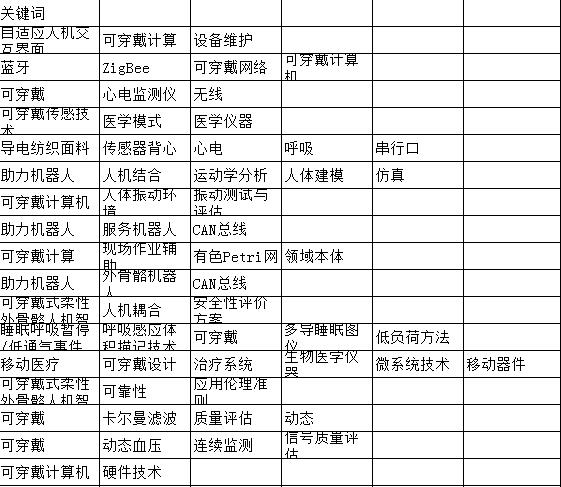
1.先说中文词频统计,网上有不少半成品的软件或工具,如ROST系列ROSTCM6,ROST WordParser等,还有MyZiCiFreq及Excel版本的“词频分析工具@Excel大全”,除此之外其他免费的词频统计软件基本就是花瓶。
2.这些软件都可以在网上下载下来。
3.其中,Rostcm6功能强大,但可惜已经不再更新。excel版本的词频统计功能简洁明了,容易上手。
4.由于目前这些免费的中文词频统计软件大都只能统计TXT文本文档,所以如果手头是PDF之类文件的话,需要先PDF转TXT,这时候需要一些工具或技巧,可以到百度经验中搜索具体办法。
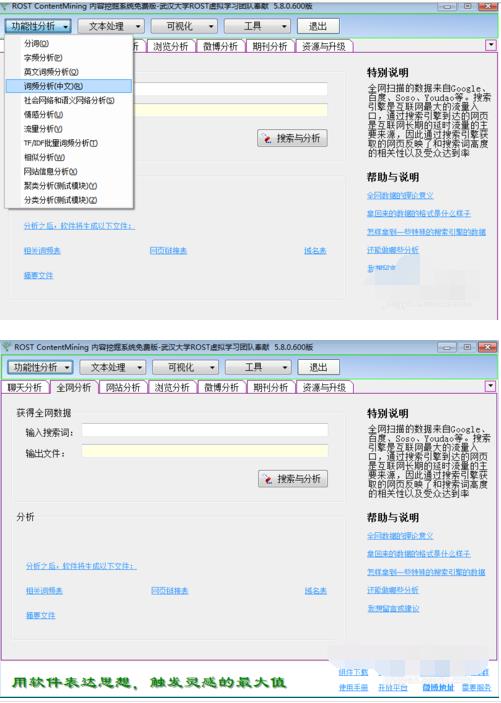

用excel做词频统计的方法如下:
把你要统计的每条内容放在一列下,上面起名词频,然后直接做透视或者合并计算 不过我认为透视简单 合并对格式要求高。
这要VBa了吧?追问
就是用Excel构建共词矩阵,大神可以帮忙吗?
追答逐一比较的话,VBA也会很慢啊。
奇怪,采纳的公式只查找一个关键字,并没有查找两个关键字啊。更何况是每两个,这又涉及到组合了吧?
统计每个关键词出现的次数,统计两两关键词出现的次数。这只是一小部分数据,有大量的数据要统计
每个关键词出现的次数
假设数据区域为A1:F100,G1为关键字
=SUMPRODUCT(LEN(A1:F100)-LEN(SUBSTITUTE(A1:F100,G1,)))/LEN(A1)
方便留下邮箱,我把数据给你,你帮我操作吗?
追答397525753
本回答被提问者和网友采纳 参考技术D 具体一点吧,给个简单的例子和你想要的结果追问就是利用Excel构建共词矩阵,数据如下
Python3 利用openpyxl 以及jieba 对帖子进行关键词抽取——对抽取的关键词进行词频统计
Python3 利用openpyxl 以及jieba 对帖子进行关键词抽取 ——对抽取的关键词进行词频统计
20180413学习笔记
一、工作
前天在对帖子的关键词抽取存储后,发现一个问题。我似乎将每个关键词都存到分离的cell中,这样在最后统计总词频的时候,比较不好处理。于是,上回的那种样式:
是不行的,应该把它们放到同一列(行)中,组装成一个list或tuple再进行词频统计。
1.读取输出文件“t1.xlsx”
wr2=load_workbook(‘t1.xlsx‘)
cursheet=wr2.active #当前表单
2.将表格中的所有数据读到L[]中
已将前面的只有十个数据的"biao.xlsx"换成有300多条帖子的"biao2.xlsx"
L=[]
for row in cursheet.rows:
for cell in row:
L.append(cell.value)
输出看看:

未完
这样看整体效果不错。
3.词频统计
利用Counter函数对L进行词频统计。
需要导入Counter from collections import Counter
#新开一个xlsx文件,将词频统计结果写入
ww2=Workbook()
sheet3 =ww2.active
sheet3.title="statis"
#Counter返回的的是一个dict
LC=Counter(L)
输出看看:

#但是这样存储起来无法使用,所以需要排一下序,sorted返回的是一个二维list
LC2=sorted(LC.items(),key=lambda d:d[1],reverse=True)
输出看看:

为了将二维数组中的每个元素,分别存储在excel表格中的两列,需要将的元素拆开。于是我找到了Python3的相关文档:
https://docs.python.org/2/tutorial/datastructures.html#list-comprehensions
将其一层层分离:
#用n来计数,奇数存储(str,num)中的前面字符串,偶数存储后面的出现次数,感觉这样做很蠢。。。但是暂时还不能像c那样熟练地使用
c1=1
for k in LC2:
n=1
for v in k:
if n%2==1:
sheet3["A%d" % c1].value=v
n=n+1
else:
sheet3["B%d" % c1].value=v
c1=c1+1
ww2.save(‘sta.xlsx‘)
我们来看看效果吧:
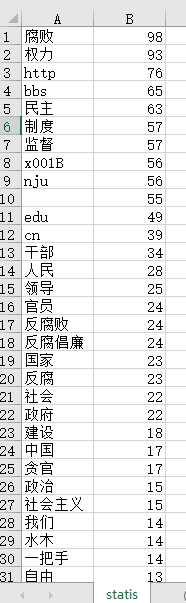
那么总体是完成了。
二、总结反思
很明显,虽然统计词频是完成了,但是感觉效果一般。尤其是在记录词汇的时候,将一些无干的词一起统计进来了。比如莫名其妙的“http”,还有其他英文,可能是爬下来的网友的名字之类的,在标注的时候过多的引用与其相关的帖子,导致出现频率过高。另外还有一些空白的符号,jieba为什么会把这种空白符当成词,奇怪。。。
三、接下来的任务
接下来的工作是对统计的词,进行处理分析。利用正则表达式,过滤出我们所需要的中文词汇,再统计一次,应该就可以了。
剩下的就是机器学习的内容了。
以上是关于怎样用Excel做关键词的词频统计的主要内容,如果未能解决你的问题,请参考以下文章