008 数据处理-MapReduce实例
Posted 玩转Hadoop
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了008 数据处理-MapReduce实例相关的知识,希望对你有一定的参考价值。
1. 问题的提出
在大数据的分析应用中,词频的统计是一个基本的应用,例如在搜索引擎中,存储大量的用户搜索的关键词,我们可以统计各个关键词的词频而形成一个搜索榜,看大家最近关心的问题、事件等。这种词频的统计在Hadoop中怎么用MapReduce实现呢?下面我们将通过统计萨松的著名诗词《于我,过去,现在以及未来》中的词频来说明这个问题。
2. 问题的解决思路
我们先来看这篇诗词的原文
In me
past
present
future meet
To hold long chiding conference
My lusts usurp the present tense
And strangle Reason in his seat
My loves leap through the future's fence
To dance with dream-enfranchised feet
In me the cave-man clasps the seer
And garlanded Apollo goes
Chanting to Abraham's deaf ear
In me the tiger sniffs the rose
Look in my heart
kind friends
and tremble
Since there your elements assemble
我们将这篇诗词存储到Hadoop的HDFS中,接下来我们按照前面所介绍的MapReduce思路统计这篇诗词的词频:
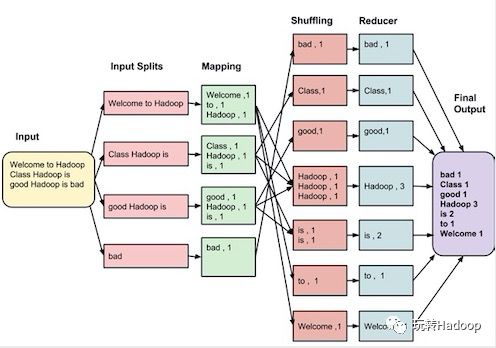
首先是Mapping过程: 把HDFS里面文本的每一个分片做一个处理,形成key/value的结果,比如图中的:(Welcome,1)(Hadoop,1)等等;
其次是Shuffling过程: 将Mapping产生的结果做一个处理,即把相同key值的放在一起;
最后是Reducer过程 :将Shuffling产生的结果做一个统计,最后输出结果。
存储文件到我们第一节搭建的Hadoop集群中:
查看四个容器是否运行
docker ps--all;没有运行则启动容器
docker start containerID;进入大数据集群edgenode节点容器
dockerexec-it containerID/bin/bash;建立input.txt文件,将诗词写入到input.txt中;
将input.txt写入到HDFS中
hadoop fs-put input.txt/input.txt.
3. MapReduce程序
有了解决问题的思路,下面我们将用python来实现MapReduce的处理流程(Java的在edgenode里面已经自带,可以参照第一节运行这个程序)。
3.1 Mapper代码
#-*- encoding=UTF-8 -*-
import sys
import re
##standard input
for line in sys.stdin:
line = line.strip()
words = re.split(' ',line)
for word in words:
print("{0} {1}".format(word,1))
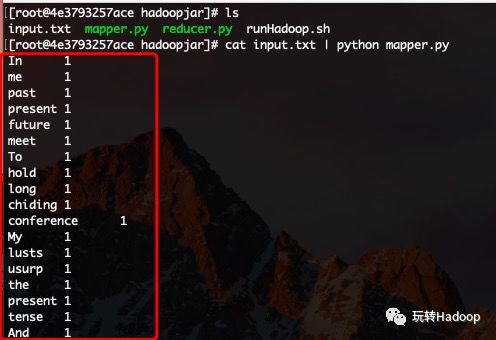
这段代码比较简单,不过多的去介绍。现在我们用input.txt来测试一个这段代码(篇幅限制只截取一部分):
3.2 Reducer代码
# -*- encoding=UTF-8 -*-
import sys
cur_word = None
cur_count = 0
word = None
for line in sys.stdin:
word,count = line.split(' ',1)
count = int(count)
if cur_word == word:
cur_count += count
else:
if cur_word:
print("{0} {1}".format(cur_word,cur_count))
cur_word = word
cur_count = count
if word:
print("{0} {1}".format(cur_word, cur_count))
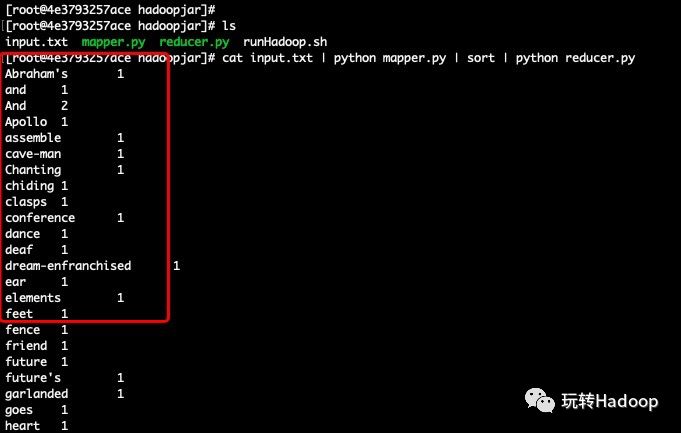
这段python代码也比较好理解,就不过多介绍了。我们也利用mapper.py的结果去测试它:
3.3 MapReduce运行
我们以shell程序的形式运行这个MapReduce程序:
#!/bin/bash
hadoop fs -rm -r -f /wordcount
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming-2.6.0-cdh5.14.0.jar
-libjars /usr/lib/hadoop-mapreduce/
-file /hadoopjar/ mapper.py
-file /hadoopjar/reducer.py
-mapper "python mapper.py"
-reducer "python reducer.py"
-input /input.txt
-output /wordcount
第一句是删除hadoop中以前可能存在的/wordcount目录,下面一句是指定python用的jar包,后面指定相应的文件, 运行这个shell脚本: sh runhadoop.sh
运行结果是:
我们可以查看相应的词频统计信息:
4.小结
这一节我们介绍了统计文本词频的MapReduce实例,当然对于MapReduce的开发还只是开始,这仅仅是一个helloword,但是对于我们理解MapReduce有很大的帮助,后续我们开始介绍hive。
以上是关于008 数据处理-MapReduce实例的主要内容,如果未能解决你的问题,请参考以下文章