CNN卷积的计算以AlexNet为例
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CNN卷积的计算以AlexNet为例相关的知识,希望对你有一定的参考价值。
参考技术A output_size=( input_size + pad * 2 - conv_size ) / stride + 1第一层:
输入为224*224*3的RGB图像,会通过预处理变为227*227*3的图像,这个图像被96个kernel采样,每个kernel的大小为11*11*3。stride为4;所以output的大小为(227-11)/4+1=55。.这样得到了96个55 * 55大小的特征图了,并且是RGB通道的。96个卷积核分成2组(因为采用了2个GPU 服务器 进行处理),每组48个卷积核;所以就有了图中的第一步卷积后的结果为55*55*48.
3.使用RELU激励函数,来确保特征图的值范围在合理范围之内,比如0,1,0,255,这些像素层经过relu1单元的处理,生成激活像素层,尺寸仍为2组55 * 55 * 48的像素层数据。
4.这些像素层经过pool运算(最大池化)的处理,池化运算的尺度为3 * 3,stride移动的步长为2,则池化后图像的尺寸为(55-3)/2+1=27。 即池化后像素的规模为27 * 27 * 96;
5.然后经过归一化处理,归一化运算的尺度为5 * 5;第一卷积层运算结束后形成的像素层的规模为27 *2 7 * 96。分别对应96个卷积核所运算形成。这96层像素层分为2组,每组48个像素层,每组在一个独立的GPU上进行运算。
第二层:
1、第一层输出为两组27*27*48特征图,第二层采用256个5*5*48卷积核,padding=2,所以采样结束后得到的特征图大小为(27+2*2-5)+1=27.256个卷积核分成两组得到27*27*128的特征图
2.这些像素层经过relu2单元的处理,生成激活像素层,尺寸仍为两组27 * 27 * 128的像素层。
3.这些像素层经过pool运算(最大池化)的处理,池化运算的尺度为3 * 3,运算的步长为2,则池化后图像的尺寸为(27-3)/2+1=13。 即池化后像素的规模为2组13 * 13 * 128的像素层。
4.最后经过归一化处理,归一化运算的尺度为5 * 5;第二卷积层运算结束后形成的像素层的规模为2组13 * 13 * 128的像素层。分别对应2组128个卷积核所运算形成。每组在一个GPU上进行运算。即共256个卷积核,共2个GPU进行运算。
第三层:
第三层没有pooling层没有归一化层
1、第三层采用384个大小为3*3*256的卷积核。stride=1.每个GPU中都有192个卷积核,每个卷积核的尺寸是3 * 3 * 256。因此,每个GPU中的卷积核都能对2组13 * 13 * 128的像素层的所有数据进行卷积运算。因此,运算后的卷积核的尺寸为(13-3+1 * 2)/1+1=13。每个GPU中共13 * 13 * 192个卷积核。2个GPU中共13 * 13 * 384个卷积后的像素层。
2、.这些像素层经过激活函数relu3,尺寸仍为2组13 * 13 * 192像素层,共13 * 13 * 384个像素层。
第四层:
第四层采用384个kernels,size is 3*3*192 padding=1计算和第三层一样。
第五层:
1、256 kernels of size 3*3*192。padding=1.计算和第三层一样卷积的结果为:每个GPU中共13*13*128个卷积核。2个GPU中共13 * 13 * 256个卷积后的像素层。
2.这些像素层经过激活函数relu5单元处理,尺寸仍为2组13 * 13 * 128像素层,共13 * 13 * 256个像素层。
3.2组13 * 13 * 128像素层分别在2个不同GPU中进行池化(最大池化)处理。池化运算的尺度为3 * 3,运算的步长为2,则池化后图像的尺寸为(13-3)/2+1=6。 即池化后像素的规模为两组6 * 6 * 128的像素层数据,共6 * 6 * 256规模的像素层数据。
第六层:
1、输入数据的尺寸是6 * 6 * 256,采用6 * 6 * 256尺寸的滤波器对输入数据进行卷积运算;每个6 * 6* 256尺寸的滤波器对第六层的输入数据进行卷积运算生成一个运算结果,通过一个神经元输出这个运算结果;共有4096个6 * 6 * 256尺寸的滤波器对输入数据进行卷积运算,通过4096个神经元输出运算结果;
2、这4096个运算结果通过relu激活函数生成4096个值;
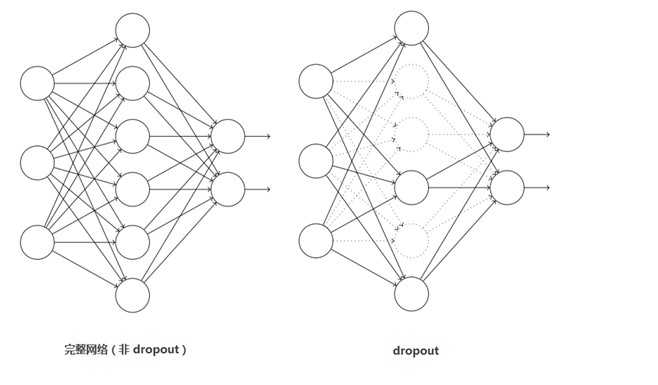
3、在dropout中是说在训练的以1/2概率使得隐藏层的某些neuron的输出为0,这样就丢到了一半节点的输出,BP的时候也不更新这些节点。通过drop运算后输出4096个本层的输出结果值。
第七层:
1.输入的4096个数据与第七层的4096个神经元进行全连接;
2.操作如同然后上一层一样经由relu7进行处理后生成4096个数据;
3.再经过dropout7(同样是以0.5的概率)处理后输出4096个数据。
第八层:
1.第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出被训练的数值。
另:
论文中采用了几种方法:
ReLU和多个GPU
为了提高训练速度,AlexNet使用ReLU代替了Sigmoid,其能更快的训练,同时解决sigmoid在训练较深的网络中出现的梯度消失,或者说梯度弥散的问题.
重叠的pool池化
提高精度, 不容易产生过拟合,在以前的CNN中普遍使用平均池化层,AlexNet全部使用最大池化层,避免了平均池化层的模糊化的效果,并且步长比池化的核的尺寸小,这样池化层的输出之间有重叠,提升了特征的丰富性.
局部响应归一化
提高精度,局部响应归一化,对局部神经元创建了竞争的机制,使得其中响应小打的值变得更大,并抑制反馈较小的.
数据增益 Dropout
减少过拟合,使用数据增强的方法缓解过拟合现象
参考文章:
https://blog.csdn.net/Rasin_Wu/article/details/80017920
CNN-2: AlexNet 卷积神经网络模型
1、AlexNet 模型简介
由于受到计算机性能的影响,虽然LeNet在图像分类中取得了较好的成绩,但是并没有引起很多的关注。 知道2012年,Alex等人提出的AlexNet网络在ImageNet大赛上以远超第二名的成绩夺冠,卷积神经网络乃至深度学习重新引起了广泛的关注。
2、AlexNet 模型特点
AlexNet是在LeNet的基础上加深了网络的结构,学习更丰富更高维的图像特征。AlexNet的特点:
1)更深的网络结构
2)使用层叠的卷积层,即卷积层+卷积层+池化层来提取图像的特征
3)使用Dropout抑制过拟合
4)使用数据增强Data Augmentation抑制过拟合
5)使用Relu替换之前的sigmoid的作为激活函数
6)多GPU训练
ReLu作为激活函数
在最初的感知机模型中,输入和输出的关系如下:
$y = \\sum\\limits_i w_ix_i + b$
只是单纯的线性关系,这样的网络结构有很大的局限性:即使用很多这样结构的网络层叠加,其输出和输入仍然是线性关系,无法处理有非线性关系的输入输出。因此,对每个神经元的输出做个非线性的转换也就是,将上面就加权求和$\\sum\\nolimits_i w_ix_i + b$的结果输入到一个非线性函数,也就是激活函数中。 这样,由于激活函数的引入,多个网络层的叠加就不再是单纯的线性变换,而是具有更强的表现能力。
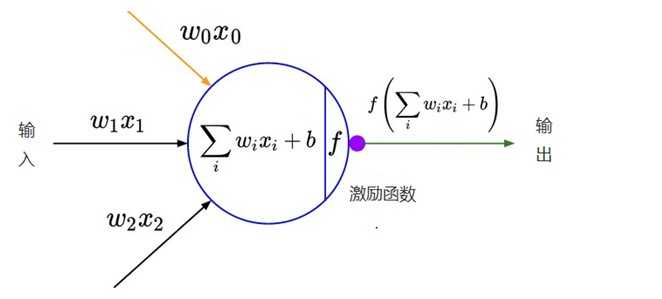
在最初,sigmoid和tanh函数最常用的激活函数。
1) sigmoid
$\\sigma \\left( x \\right) = \\frac11 + e^ - x$
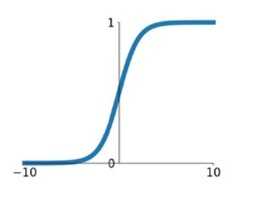
在网络层数较少时,sigmoid函数的特性能够很好的满足激活函数的作用:它把一个实数压缩至0到1之间,当输入的数字非常大的时候,结果会接近1;当输入非常大的负数时,则会得到接近0的结果。这种特性,能够很好的模拟神经元在受刺激后,是否被激活向后传递信息(输出为0,几乎不被激活;输出为1,完全被激活)。
sigmoid一个很大的问题就是梯度饱和。 观察sigmoid函数的曲线,当输入的数字较大(或较小)时,其函数值趋于不变,其导数变的非常的小。这样,在层数很多的的网络结构中,进行反向传播时,由于很多个很小的sigmoid导数累成,导致其结果趋于0,权值更新较慢。
2) ReLu
$ReLU\\left( x \\right) = max\\left( 0\\user1,x \\right)$
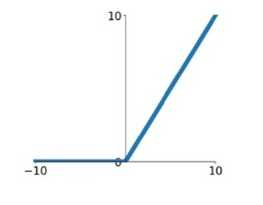
针对sigmoid梯度饱和导致训练收敛慢的问题,在AlexNet中引入了ReLU。ReLU是一个分段线性函数,小于等于0则输出为0;大于0的则恒等输出。相比于sigmoid,ReLU有以下有点:
1)计算开销下。sigmoid的正向传播有指数运算,倒数运算,而ReLu是线性输出;反向传播中,sigmoid有指数运算,而ReLU有输出的部分,导数始终为1.
2)梯度饱和问题
3)稀疏性。Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
这里有个问题,前面提到,激活函数要用非线性的,是为了使网络结构有更强的表达的能力。那这里使用ReLU本质上却是个线性的分段函数,是怎么进行非线性变换的。 这里把神经网络看着一个巨大的变换矩阵M,其输入为所有训练样本组成的矩阵A,输出为矩阵B。
$B = M \\cdot A$
这里的M是一个线性变换的话,则所有的训练样本A进行了线性变换输出为B。 那么对于ReLU来说,由于其是分段的,0的部分可以看着神经元没有激活,不同的神经元激活或者不激活,其神经玩过组成的变换矩阵是不一样的。也就是说,每个训练样本使用的线性变换矩阵是不一样的,在整个训练样本空间来说,其经历的是非线性变换。
简单来说,不同训练样本中的同样的特征,在经过神经网络学习时,流经的神经元是不一样的(激活函数值为0的神经元不会被激活)。这样,最终的输出实际上是输入样本的非线性变换。单个训练样本是线性变换,但是每个训练样本的线性变换是不一样的,这样整个训练样本集来说,就是非线性的变换。
数据增强
神经网络由于训练的参数多,表能能力强,所以需要比较多的数据量,不然很容易过拟合。当训练数据有限时,可以通过一些变换从已有的训练数据集中生成一些新的数据,以快速地扩充训练数据。对于图像数据集来说,可以对图像进行一些形变操作:
1) 翻转
2) 随机裁剪
3)平移,颜色光照的变换
...
AlexNet中对数据做了以下操作:
1)随机裁剪,对256×256的图片进行随机裁剪到227×227,然后进行水平翻转。
2)测试的时候,对左上、右上、左下、右下、中间分别做了5次裁剪,然后翻转,共10个裁剪,之后对结果求平均。
3)对RGB空间做PCA(主成分分析),然后对主成分做一个(0, 0.1)的高斯扰动,也就是对颜色、光照作变换,结果使错误率又下降了1%。
层叠池化
在LeNet中池化是不重叠的,即池化的窗口的大小和步长是相等的,如下:
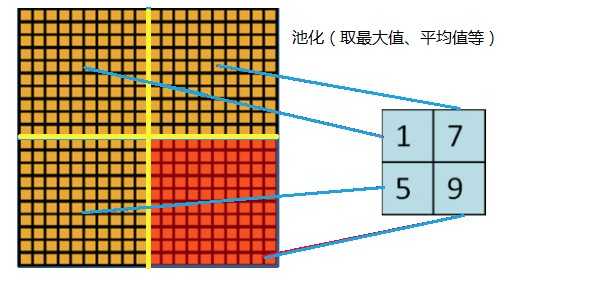
在AlexNet中使用的池化(Pooling)却是可重叠的,也就是说,在池化的时候,每次移动的步长小于池化的窗口长度。AlexNet池化的大小为3×3的正方形,每次池化移动步长为2,这样就会出现重叠。重叠池化可以避免过拟合,这个策略贡献了0.3%的Top-5错误率。与非重叠方案s=2,z=2相比,输出的维度是相等的,并且能在一定程度上抑制过拟合。
局部相应归一化
ReLU具有让人满意的特性,它不需要通过输入归一化来防止饱和。如果至少一些训练样本对ReLU产生了正输入,那么那个神经元上将发生学习。然而,我们仍然发现接下来的局部响应归一化有助于泛化。$a_x,y^i$表示神经元激活,通过在(x,y)(位置应用核$i$然后应用ReLU非线性来计算,响应归一化激活$b_x,y^i$通过下式给定:
$b_x,y^i = \\fraca_x,y^i\\left( k + \\alpha \\sum\\limits_j = max\\left( 0,i - n \\mathord\\left/
\\vphantom i - n 2 \\right.
\\kern-\\nulldelimiterspace 2 \\right)^min(N - 1,i + n \\mathord\\left/
\\vphantom i + n 2 \\right.
\\kern-\\nulldelimiterspace 2) \\left( a_x,y^j \\right)^2 \\right)^\\beta $
其中,N是卷积核的个数,也就是生成的FeatureMap的个数;$k,\\alpha ,\\beta ,n$是超参数,论文中使用的值是$k = 2,\\alpha = 10^ - 4,\\beta = 0.75,n = 5$。输出$b_x,y^i$和输入$a_x,y^i$的上标表示的是当前值所在的通道,也即是叠加的方向是沿着通道进行。将要归一化的值$a_x,y^i$所在附近通道相同位置的值的平方累加起来$\\sum\\nolimits_j = max\\left( 0,i - n \\mathord\\left/
\\vphantom i - n 2 \\right.
\\kern-\\nulldelimiterspace 2 \\right)^min(N - 1,i + n \\mathord\\left/
\\vphantom i + n 2 \\right.
\\kern-\\nulldelimiterspace 2) \\left( a_x,y^j \\right)^2 $
Dropout
这个是比较常用的抑制过拟合的方法了。 引入Dropout主要是为了防止过拟合。在神经网络中Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。 Dropout应该算是AlexNet中一个很大的创新,现在神经网络中的必备结构之一。Dropout也可以看成是一种模型组合,每次生成的网络结构都不一样,通过组合多个模型的方式能够有效地减少过拟合,Dropout只需要两倍的训练时间即可实现模型组合(类似取平均)的效果,非常高效。 如下图:
3、Alex网络结构
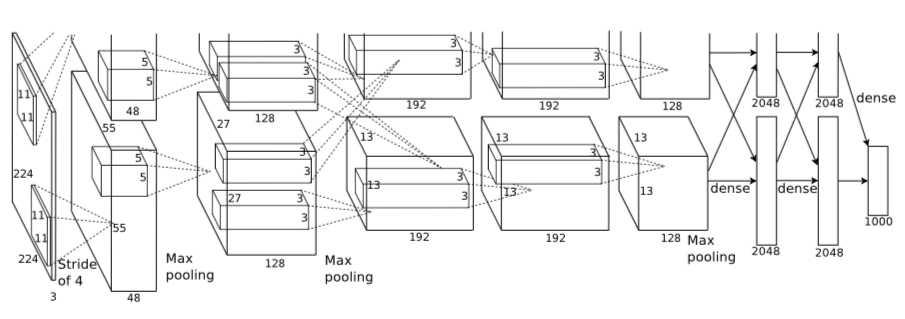
注:上图中的输入是224×224,不过经过计算(224−11)/4=54.75并不是论文中的55×55,而使用227×227作为输入,则(227−11)/4=55。
网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布。
- 卷积层C1
该层的处理流程是: 卷积-->ReLU-->池化-->归一化。
1)卷积,输入是227×227,使用96个11×11×3的卷积核,得到的FeatureMap为55×55×96。
2)ReLU,将卷积层输出的FeatureMap输入到ReLU函数中。
3)池化,使用3×3步长为2的池化单元(重叠池化,步长小于池化单元的宽度),输出为27×27×96((55−3)/2+1=27)。
4)局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为27×27×96,输出分为两组,每组的大小为27×27×48。
- 卷积层C2
该层的处理流程是:卷积-->ReLU-->池化-->归一化。
1)卷积,输入是2组27×27×48。使用2组,每组128个尺寸为5×5×48的卷积核,并作了边缘填充padding=2,卷积的步长为1. 则输出的FeatureMap为2组,每组的大小为 27×27 times128. ((27+2∗2−5)/1+1=27)。
2)ReLU,将卷积层输出的FeatureMap输入到ReLU函数中。
3)池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为(27−3)/2+1=13,输出为13×13×256。
4)局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为13×13×256,输出分为2组,每组的大小为13×13×128。
- 卷积层C3
该层的处理流程是: 卷积-->ReLU。
1)卷积,输入是13×13×256,使用2组共384尺寸为3×3×256的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times384。
2)ReLU,将卷积层输出的FeatureMap输入到ReLU函数中。
- 卷积层C4
该层的处理流程是: 卷积-->ReLU
该层和C3类似。
1)卷积,输入是13×13×384,分为两组,每组为13×13×192.使用2组,每组192个尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times384,分为两组,每组为13×13×192。
2)ReLU,将卷积层输出的FeatureMap输入到ReLU函数中。
以上是关于CNN卷积的计算以AlexNet为例的主要内容,如果未能解决你的问题,请参考以下文章