计算机视觉中的深度学习8: 卷积神经网络的结构
Posted SuPhoebe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉中的深度学习8: 卷积神经网络的结构相关的知识,希望对你有一定的参考价值。
Slides:百度云 提取码: gs3n
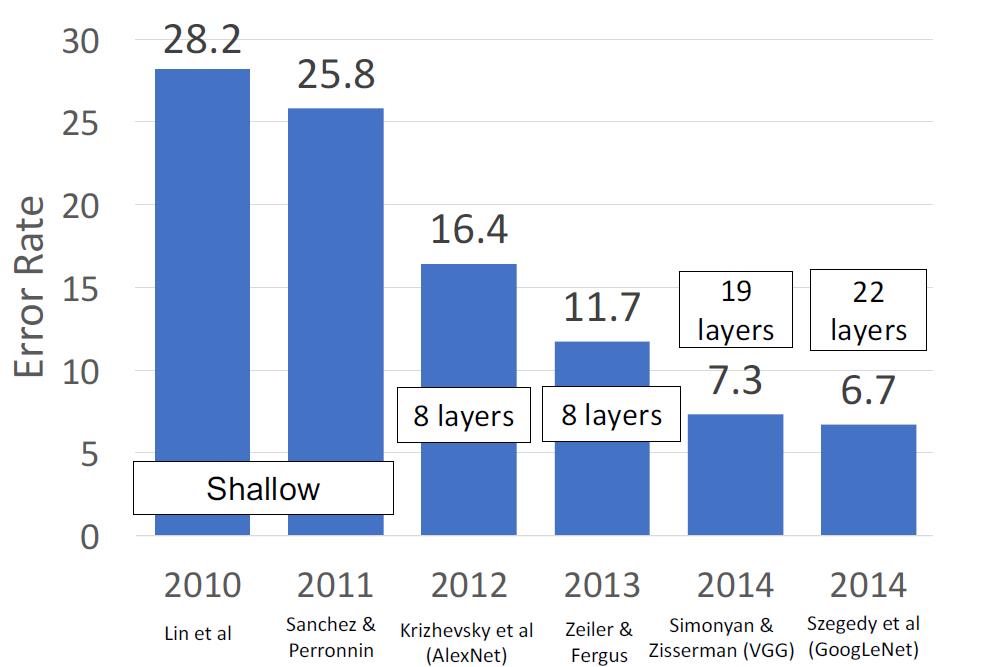
今天这一讲,我们以ImageNet Classification Challenge中使用的CNN的发展来进行介绍。
AlexNet
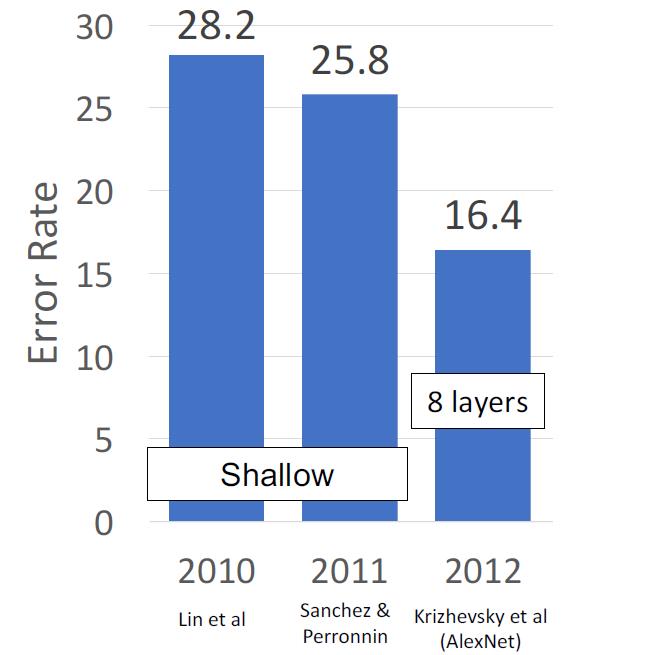
在2012年以前,ImageNet Classification Challenge的获胜者都是人工进行特征提取的线性分类模型。在2012年,AlexNet成功登顶。
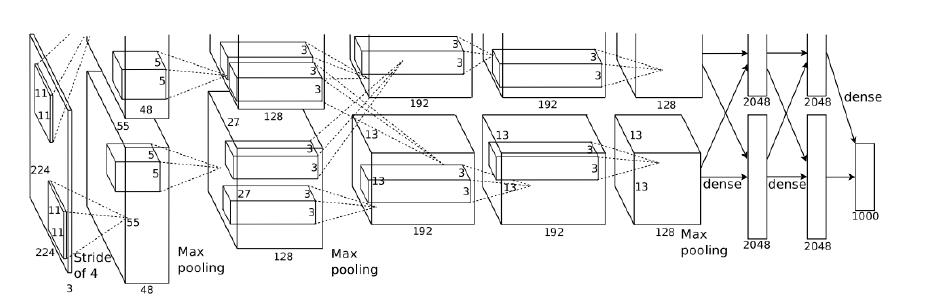
AlexNet的结构
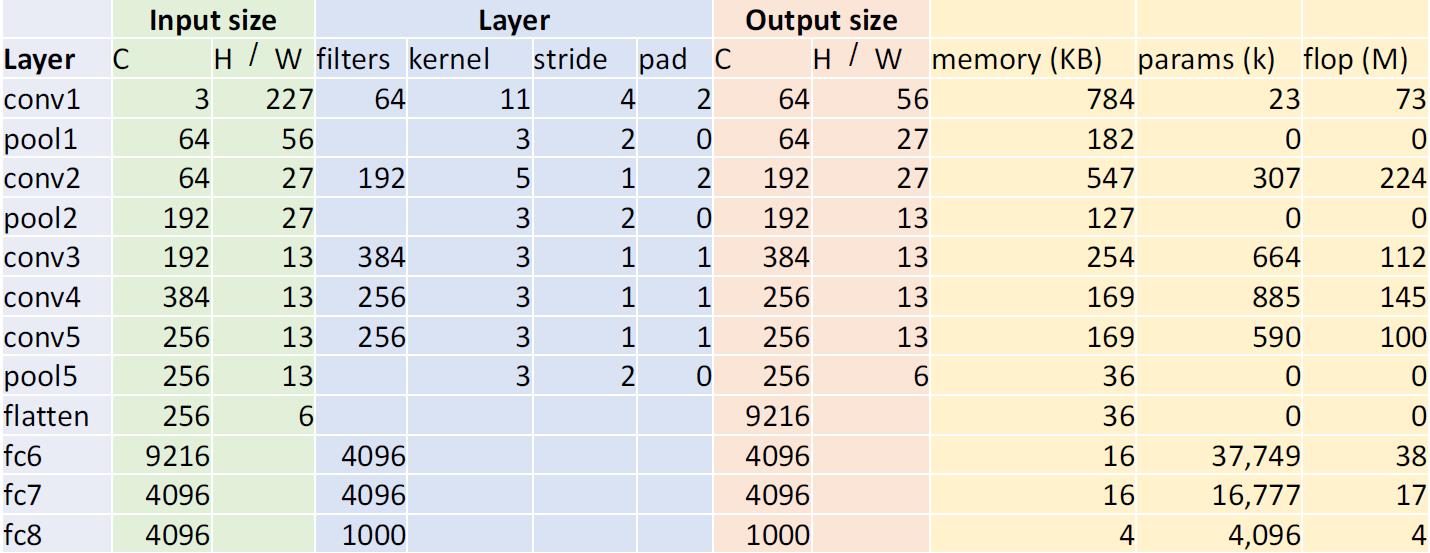
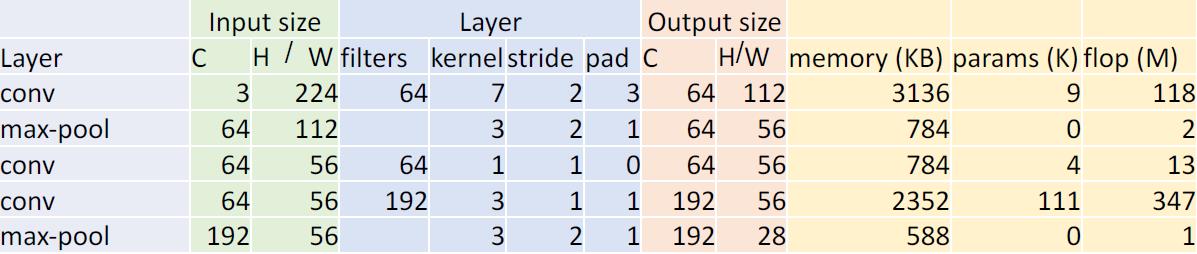
蓝色部分是神经网络的结构,从这我们能够看得出来,这个神经网络的各项长宽大小都是没有明显规律的。这花费了研究人员很长时间进行调整。
黄色的部分是计算的资源
- 内存占有
- 训练参数的个数
- 浮点计算的次数
仔细地观察一下变化的趋势
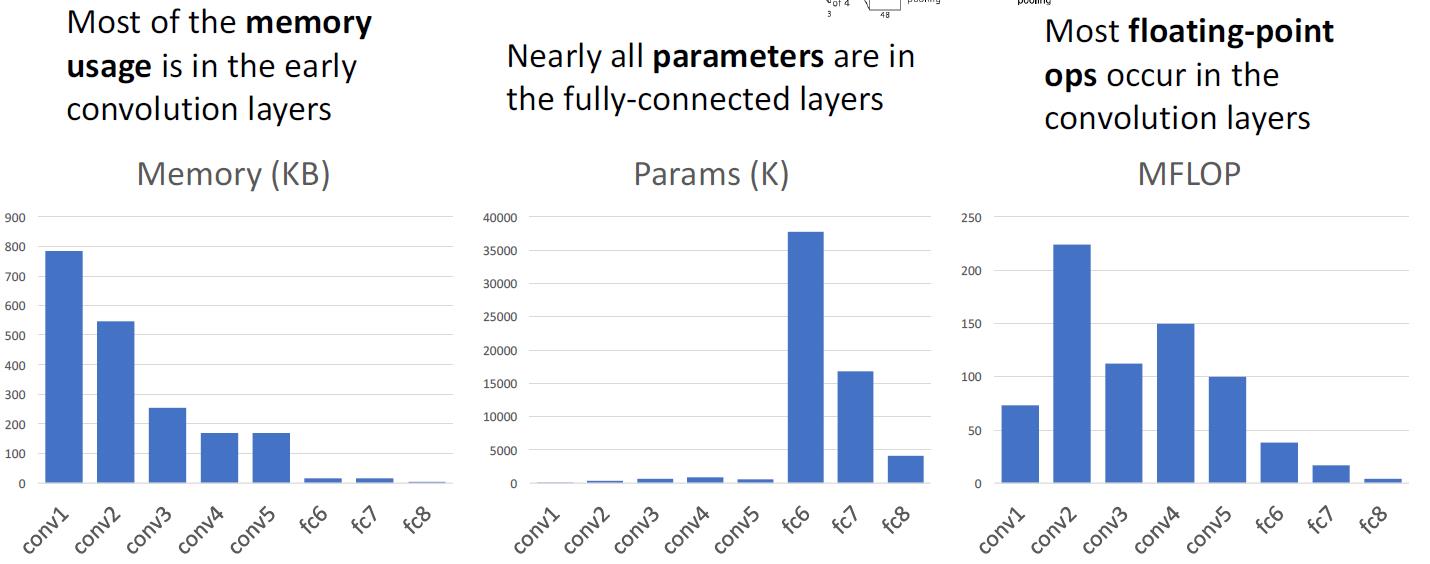
- 内存都集中在前几个卷积层,因为卷积层是输入和输出都非常大,而且filter的个数越多,输出也越大
- 因为全连接层的连接方式是类似笛卡尔乘积的,所以W的个数非常大,从而产生了更多的可训练参数
- filter个数对计算次数影响很大,这因为是卷积,每一次卷积都会产生大量的计算。
ZFNet
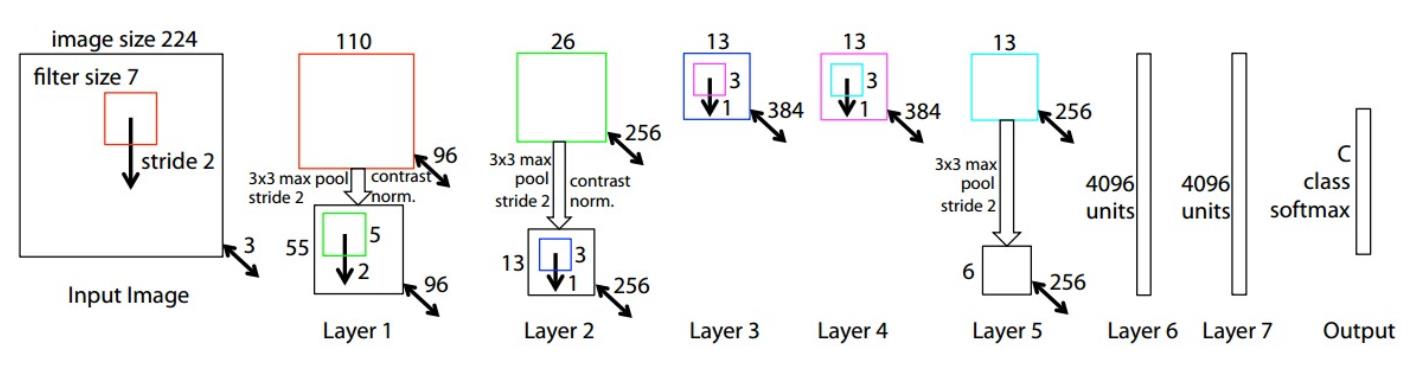
这本质上的设计思路和AlexNet一模一样,但是这儿使用了更大的神经网络
- Conv1:使用了 (7x7 步长 2)的filter,而AlexNet使用的是(11x11 步长 4)的filter
- Conv3, 4, 5:使用了512, 1024, 512个filter,而AlexNet使用了384,384,256个filter。
一般来说,更大的网络会有更好的效果。因为你能处理更大的更多的数据了,也能从数据中提取和保留更多的信息。
缺点是,收敛慢,downsample慢。
VGG
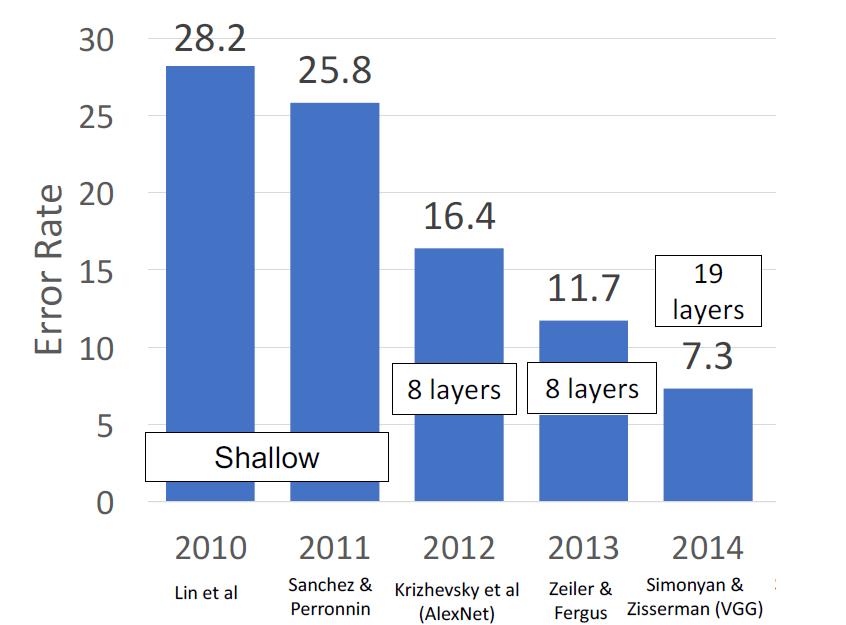
最重要的一点,VGG已经不需要再用人工进行一点一点调试神经网络的结构了,他通过有规律的组合,达成了非同一般的效果,这样我们能够更快地扩展神经网络,让它变得更深更大。
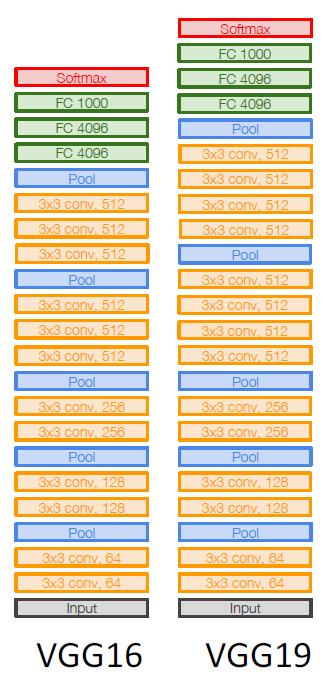
VGG设计规则
- 所有卷积层都是3x3 步长1 pad 1的结构
- 所有最大池均为2x2 步长 2
- 在池层之后,将通道的数据通过复制扩展为2倍
在VGG中,卷积层有5个阶段
- Stage 1: conv-conv-pool
- Stage 2: conv-conv-pool
- Stage 3: conv-conv-pool
- Stage 4: conv-conv-conv-[conv]-pool
- Stage 5: conv-conv-conv-[conv]-pool (VGG-19 has 4 conv in stages 4 and 5)
卷积层设计
我们有两种选择
Option 1:
- Conv(5x5, C -> C)
- Params: 25C2
- FLOPs: 25C2HW
Option 2:
- Conv(3x3, C -> C), Conv(3x3, C -> C)
- Params: 18C2
- FLOPs: 18C2HW
两个3x3转换与单个5x5转换具有相同的接收域,也就说,一个相同大小的input,经过选择1和选择2,他们的输出大小是一样的。
但是选择2的优点在于
- 参数较少且计算量较小,需要更少的计算资源
- 两个卷积层的结合,使得非线性计算更多,也让特征之间的组合更多
池层设计
为什么要将通道复制一遍?
因为我们希望每个卷积层都需要有相同的计算量!

第一层的输入是Cx2Hx2W,输出则是Cx2Hx2W.
经过2x2 步长为2的max pooling之后,输出则变成了CxHxW
为了达成每个卷积层都需要有相同的计算量的目标,我们只需要将C×2。
第二层的输入就变成了2CxHxW。
如上图所示,则两个卷积层的浮点计算量是相同的。
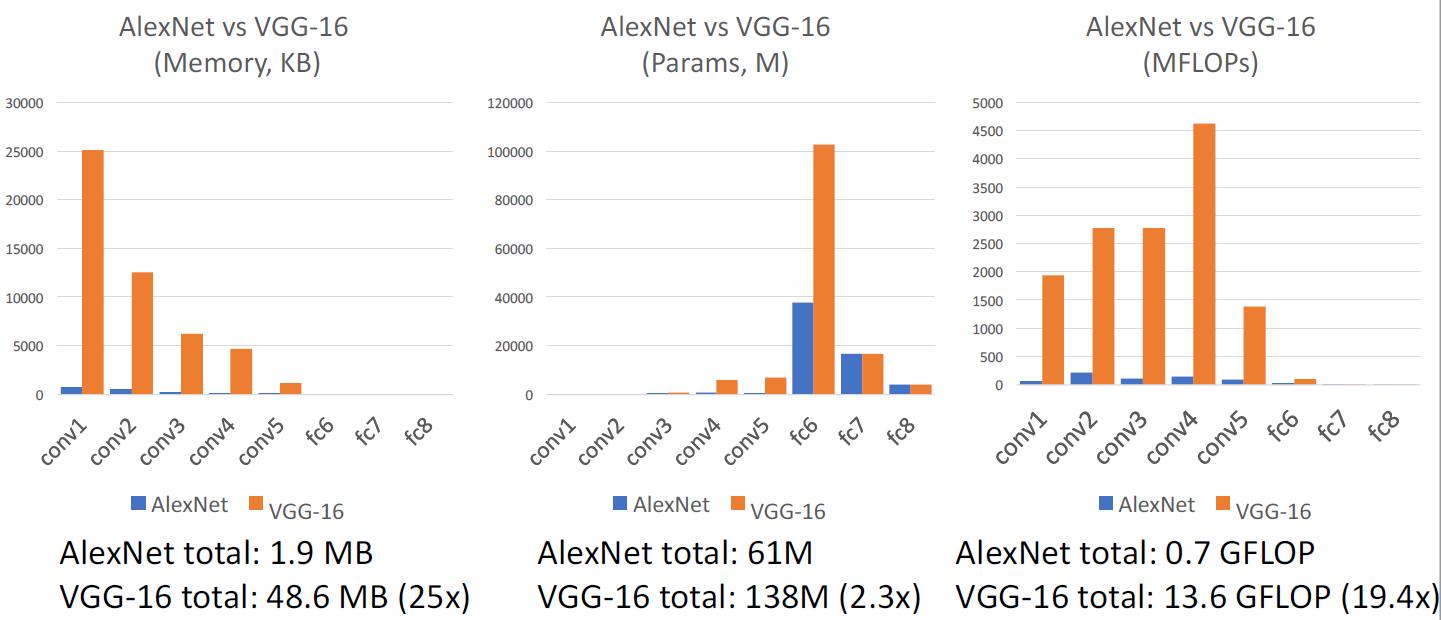
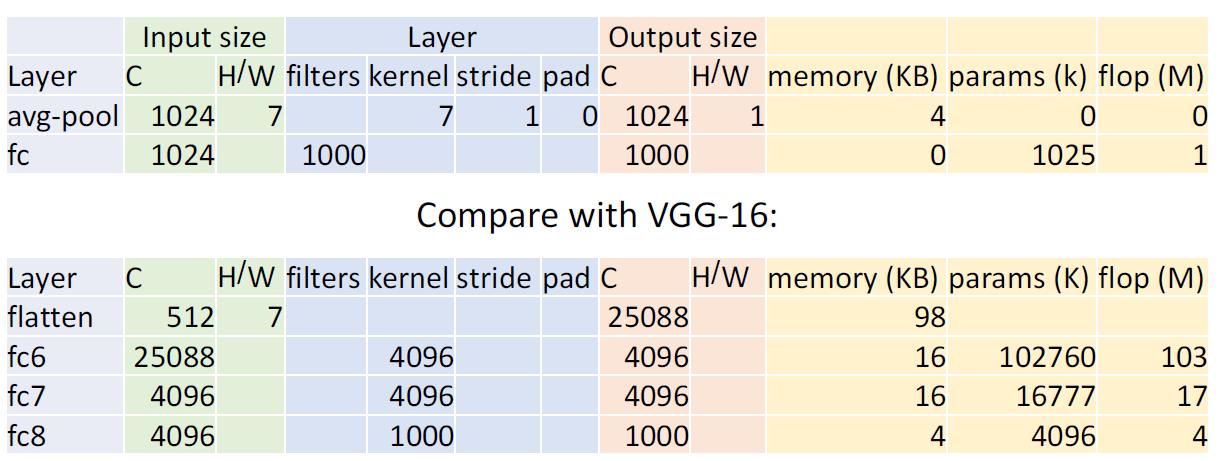
AlexNet vs VGG-16
VGG是一个比AlexNet大得多的网络,这得益于GPU技术的快速发展。
在AlexNet时代,一个GPU的显存才3G,需要将AlexNet拆解成两部分放到两个GPU里面进行。
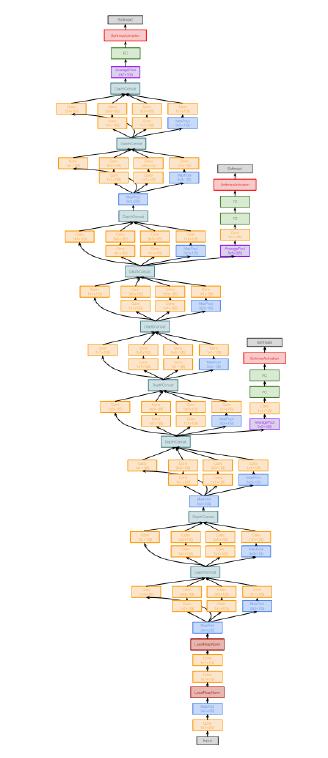
GoogLeNet
一个工业界和学术界结合的产品,google作为世界上最强的互联网公司,他们在这个网络上有着效率方面的许多创新:减少参数数量,内存使用量和计算量。
网络的结构如下,我们将在下面详细讲解每一个部分
Stem network
在神经网络最初的一部分
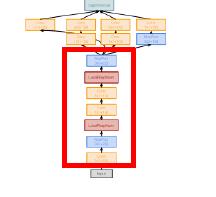
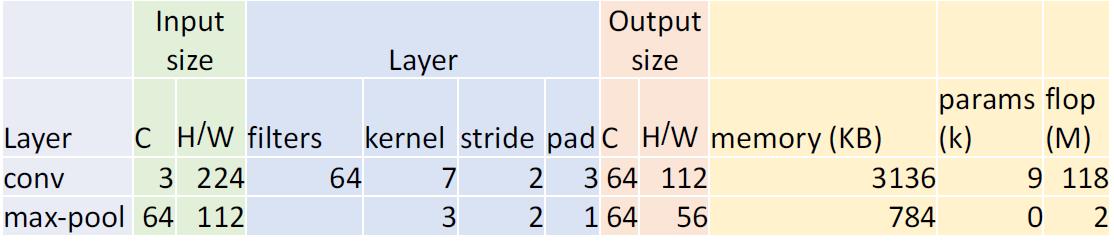
他通过非常激进的downsample,将输入迅速压缩。反观前几个神经网络,如VGG,最主要的计算都发生在神经网络的开端。
输入的大小从224降低为28,花费了
- Memory: 7.5 MB
- Params: 124K
- MFLOP: 418(其实这个我没看明白它是怎么算出来的)
对比VGG-16,达到同样的大小,花费了
- Memory: 42.9 MB (5.7x)
- Params: 1.1M (8.9x)
- MFLOP: 7485 (17.8x)
Inception module
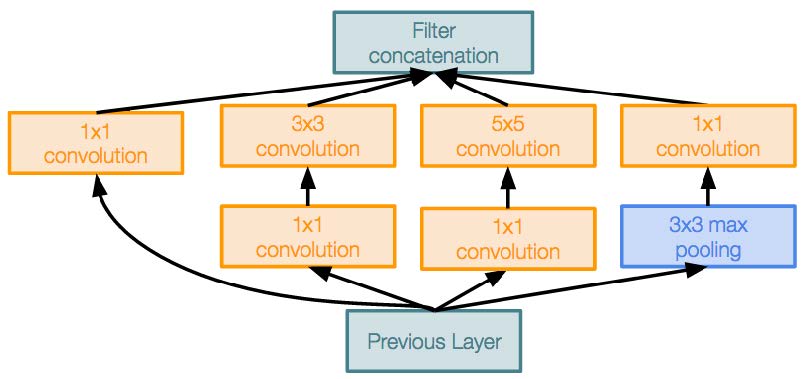
- 具有多个并行分支的本地单元
- 与VGG相比,google用不同的方式来避免设置超参数造成的人工损耗
- 他们把所有可能性的组合都在放在一个并行的层面上,由机器来自行组合
- 类似的本地结构在整个网络中重复了很多次
- 在计算代价很大的卷积层之前,使用1x1 "Bottleneck"卷积层来减小通道尺寸(我们将通过ResNet在下面更详细地讨论这个问题)
Global Average Pooling
最后没有非常庞大的全连接层! 取而代之的是使用全局平均池来折叠维度的方式,最后也是使用一个线性层来产生类的分数。相比于VGG和前面其他的神经网络,大部分的训练参数都是在全连接层。
Auxiliary Classifiers
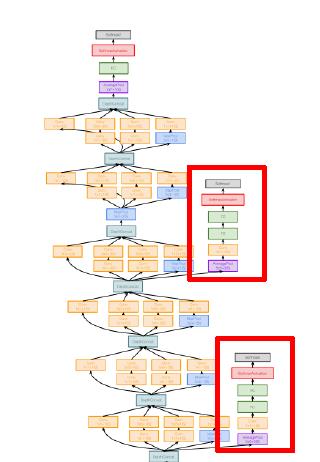
我们可以看到这是一个非常深的神经网络,在没有Batch Normalization之前,类似的神经网络非常难以训练。因为网络太深,gradient无法清晰传播到前面的网络之中。
用了一种非常hacky的方式,在网络中的多个中间点附加“辅助分类器”,这些中间点还会尝试对图像进行分类并接收损失,进行更加即时的反馈。
GoogLeNet的这项技术在Batch Norm出来后,就被放弃了。
Residual Networks
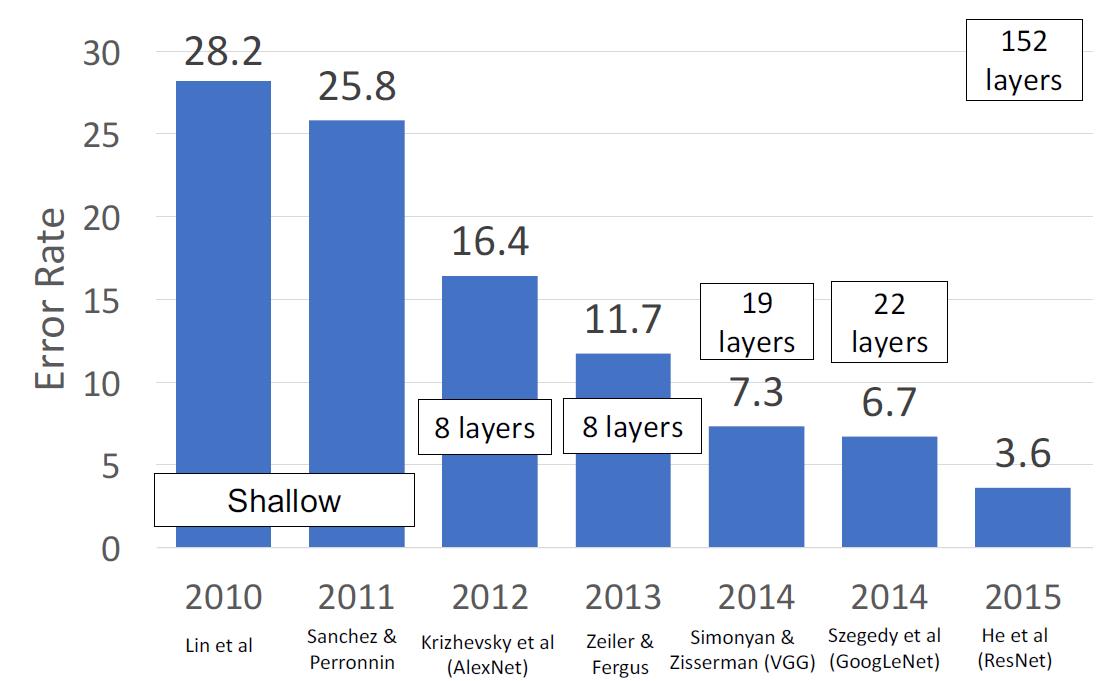
我们可以看到ResNet是一个非常非常深的神经网络,这也得益于Batch Norm的发展。但是让我们先来看看一个数据
在论文He et al, “Deep Residual Learning for Image Recognition”, CVPR 2016中,我们可以看到,更大更深的神经网络居然在测试集上面有着更糟糕的表现。
这与我们之前的猜想,更深的神经网络有着更好的表现是不符合的。
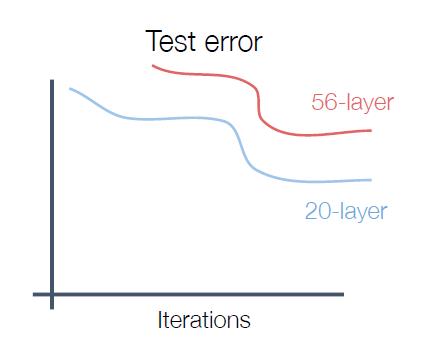
对于原因的初步猜想,我们会认为是更深层的神经网络overfitting了。但是我们看看他们在训练集上的表现
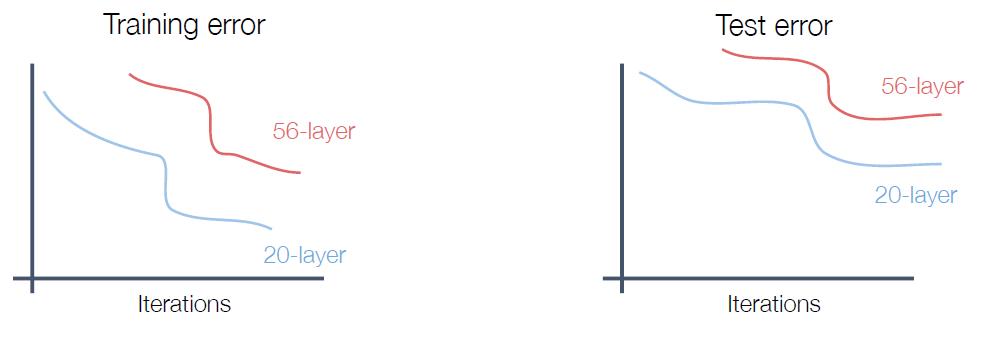
令人惊奇的是,我们发现更深的神经网络在训练集上的表现就不如浅层神经网络。那么实际上更深的神经网络是underfitting。
理论上,较深的模型可以模拟较浅的模型:从较浅的模型复制图层(输入),直接往深层的模型进行输入(绕过卷积层或者池层),设置额外的图层以进行identity。那实际上更深的模型在表现上至少不能低于浅层的模型。
假设:这是一个优化问题。
较深的模型更难优化,因为到达一定深度后,网络就很难再收敛了,尤其是不能学习identity函数来模拟较浅的模型;尽管用了batch norm,网络都难以让初始的信息更多地传递到深层。
Residual Block
解决方案:更改网络,以便让底层网络能够更加轻松学习带有额外层的identity函数!
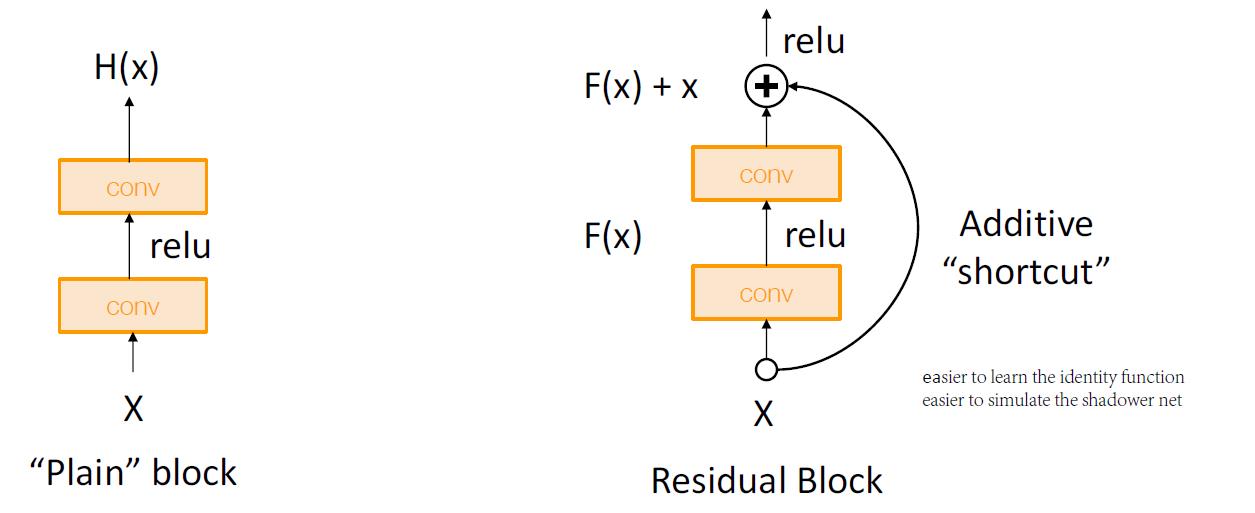
就算将其中两个conv的权重全设置为0,那么对于输出,也能体现出X本身的作用。在BP的gradient上面,也能完美地体现X对两个conv的影响。
网络结构
- residual network是许多residual blocks的堆砌。
- 结合了VGG这样的常规设计:每个residual blocks都有两个3x3转换
- 网络分为多个阶段:每个阶段的第一个块将分辨率减半(使用步长为2的卷积层),并使通道数增加一倍
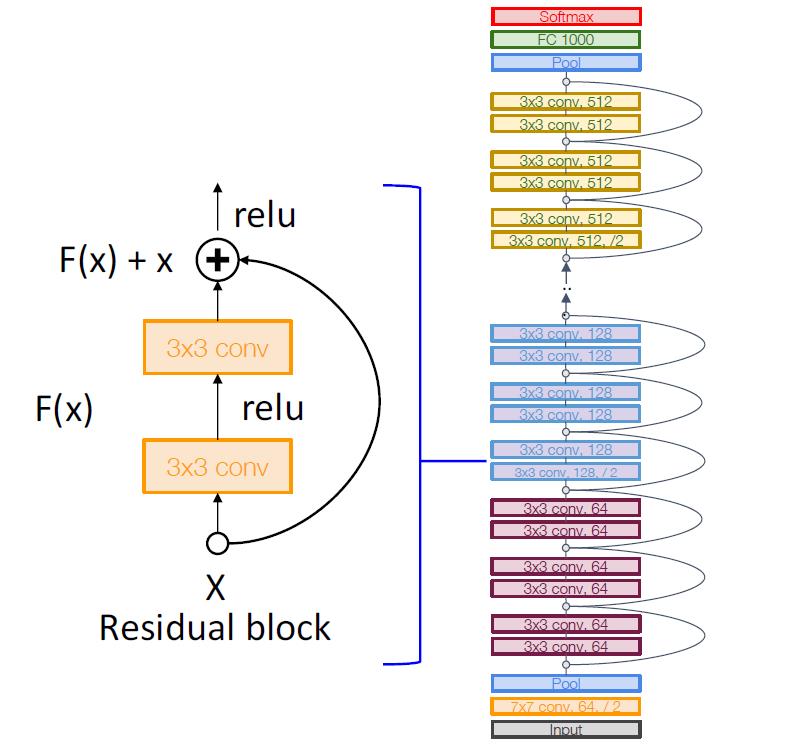
Stem
在初始阶段就用类似GoogleNet的方式将输入4x地downsample
Global Average Pooling
在网络的最后也没有使用全连接层,而是和GoogleNet采用了同样的方式:用global average pooling和一个线性分类层。
网络扩充
两个版本的ResNet,后者将网络进行类似VGG-19的扩充,获得了更好的网络结果

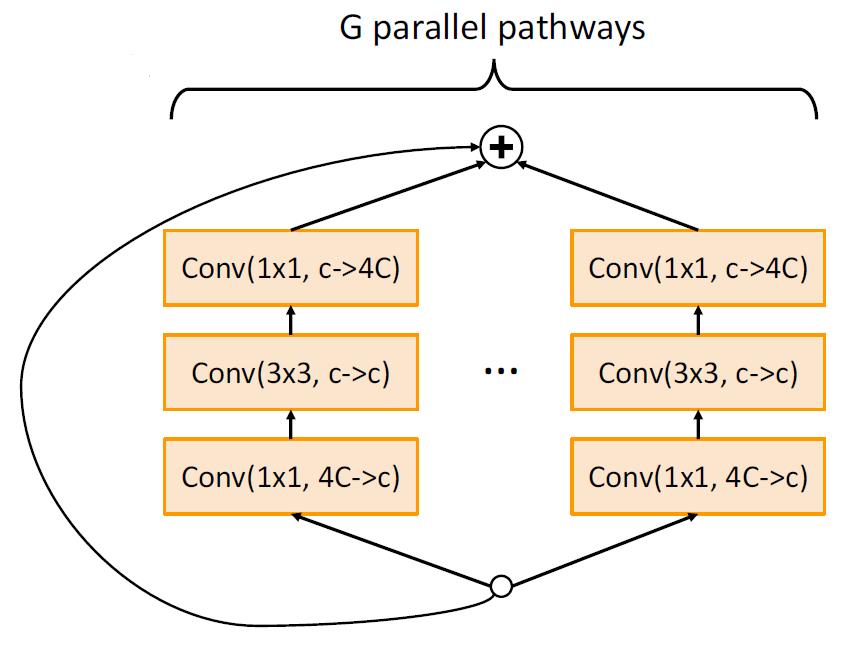
Bottleneck Block

左边是基础的ResBlock,右边是结合了Bottleneck的ResBlock。
首先我们能确定的是,这样并不会降低网络的接收域。
那右边的有点在于
- 更少的浮点数运算
- 更多的卷积层,和更多的非线性计算,这样能产生更好地feature组合效果
Block Design

对于ResNet最重要的就是ResBlock的设计问题。
左边是原有的设计,将输入X结合到ReLu函数之后,但是其实这样并不能完整地学习到输入X,因为ReLu是一个非线性函数,输出是非负的。
将shortcut输入调换一下位置,从一个卷积层的输出,直接越过一段卷积块的计算,累积到输出。这样的好处是,能够真真切切地学习到identity。计算我们把中间的卷积层的Weight全部抹除为0,输入任然能够在这一个block之后体现自己的价值。
Model Ensembles
将Inception,Inception-Resnet, Resnet, Wide Resnet models进行组合
Squeeze-and-Excitation Networks
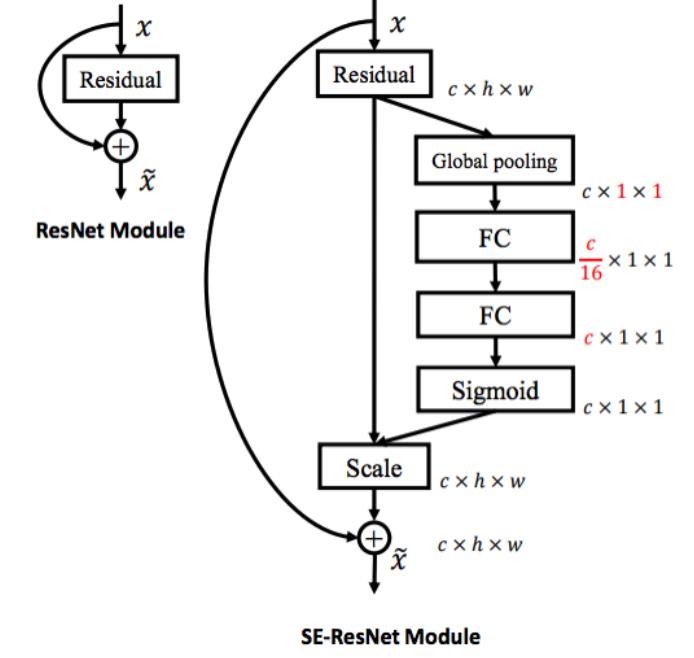
向每个ResBlock添加一个”Squeeze-and-excite”分支,以执行global池化,全连接层,然后再将结果累计回到特征图上。
相比于单纯的ResBlock,它获得了全局的内容。
Densely Connected Neural Networks
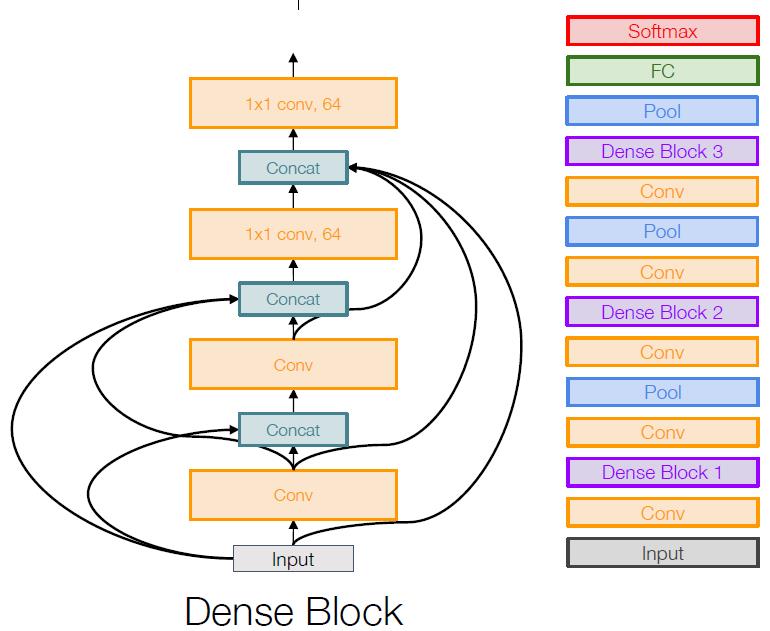
DenseBlock的思路是基于前面几个网络的,它将网络的输出,与另外的网络输入输出进行结合(即,连接),这样在前向传播的过程中,能够强化以前学习的特征,鼓励特征的重复利用,而不是将以前学过的特征丢弃。
以上是关于计算机视觉中的深度学习8: 卷积神经网络的结构的主要内容,如果未能解决你的问题,请参考以下文章