大数据采集清洗处理:使用MapReduce进行离线数据分析完整案例
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据采集清洗处理:使用MapReduce进行离线数据分析完整案例相关的知识,希望对你有一定的参考价值。
[TOC]
1 大数据处理的常用方法
大数据处理目前比较流行的是两种方法,一种是离线处理,一种是在线处理,基本处理架构如下:
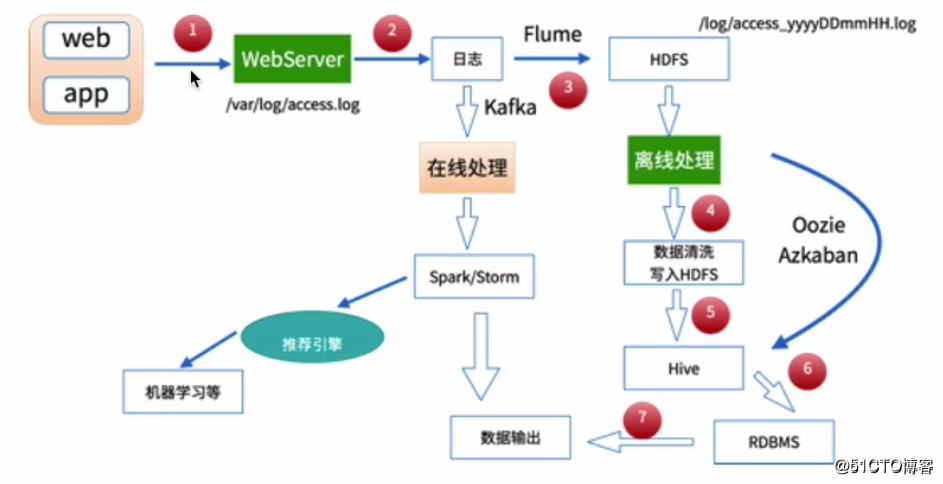
在互联网应用中,不管是哪一种处理方式,其基本的数据来源都是日志数据,例如对于web应用来说,则可能是用户的访问日志、用户的点击日志等。
如果对于数据的分析结果在时间上有比较严格的要求,则可以采用在线处理的方式来对数据进行分析,如使用Spark、Storm等进行处理。比较贴切的一个例子是天猫双十一的成交额,在其展板上,我们看到交易额是实时动态进行更新的,对于这种情况,则需要采用在线处理。
当然,如果只是希望得到数据的分析结果,对处理的时间要求不严格,就可以采用离线处理的方式,比如我们可以先将日志数据采集到HDFS中,之后再进一步使用MapReduce、Hive等来对数据进行分析,这也是可行的。
本文主要分享对某个电商网站产生的用户访问日志(access.log)进行离线处理与分析的过程,基于MapReduce的处理方式,最后会统计出某一天不同省份访问该网站的uv与pv。
2 生产场景与需求
在我们的场景中,Web应用的部署是如下的架构:
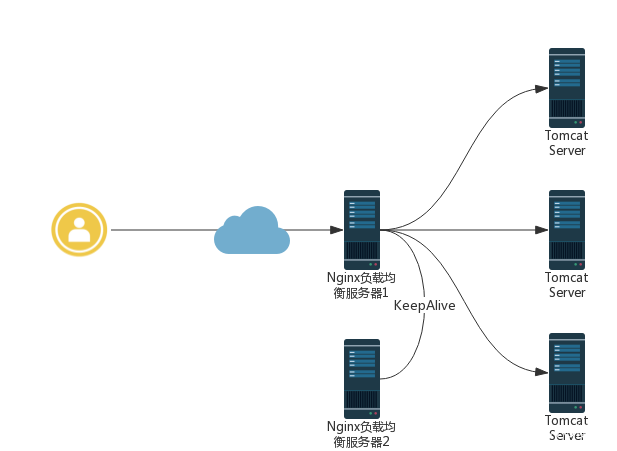
即比较典型的nginx负载均衡+KeepAlive高可用集群架构,在每台Web服务器上,都会产生用户的访问日志,业务需求方给出的日志格式如下:
1001 211.167.248.22 eecf0780-2578-4d77-a8d6-e2225e8b9169 40604 1 GET /top HTTP/1.0 408 null null 1523188122767
1003 222.68.207.11 eecf0780-2578-4d77-a8d6-e2225e8b9169 20202 1 GET /tologin HTTP/1.1 504 null Mozilla/5.0 (Windows; U; Windows NT 5.1)Gecko/20070309 Firefox/2.0.0.3 1523188123267
1001 61.53.137.50 c3966af9-8a43-4bda-b58c-c11525ca367b 0 1 GET /update/pass HTTP/1.0 302 null null 1523188123768
1000 221.195.40.145 1aa3b538-2f55-4cd7-9f46-6364fdd1e487 0 0 GET /user/add HTTP/1.1 200 null Mozilla/4.0 (compatible; MSIE 7.0; Windows NT5.2) 1523188124269
1000 121.11.87.171 8b0ea90a-77a5-4034-99ed-403c800263dd 20202 1 GET /top HTTP/1.0 408 null Mozilla/5.0 (Windows; U; Windows NT 5.1)Gecko/20070803 Firefox/1.5.0.12 1523188120263其每个字段的说明如下:
appid ip mid userid login_type request status http_referer user_agent time
其中:
appid包括:web:1000,android:1001,ios:1002,ipad:1003
mid:唯一的id此id第一次会种在浏览器的cookie里。如果存在则不再种。作为浏览器唯一标示。移动端或者pad直接取机器码。
login_type:登录状态,0未登录、1:登录用户
request:类似于此种 "GET /userList HTTP/1.1"
status:请求的状态主要有:200 ok、404 not found、408 Request Timeout、500 Internal Server Error、504 Gateway Timeout等
http_referer:请求该url的上一个url地址。
user_agent:浏览器的信息,例如:"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/47.0.2526.106 Safari/537.36"
time:时间的long格式:1451451433818。根据给定的时间范围内的日志数据,现在业务方有如下需求:
统计出每个省每日访问的PV、UV。3 数据采集:获取原生数据
数据采集工作由运维人员来完成,对于用户访问日志的采集,使用的是Flume,并且会将采集的数据保存到HDFS中,其架构如下:
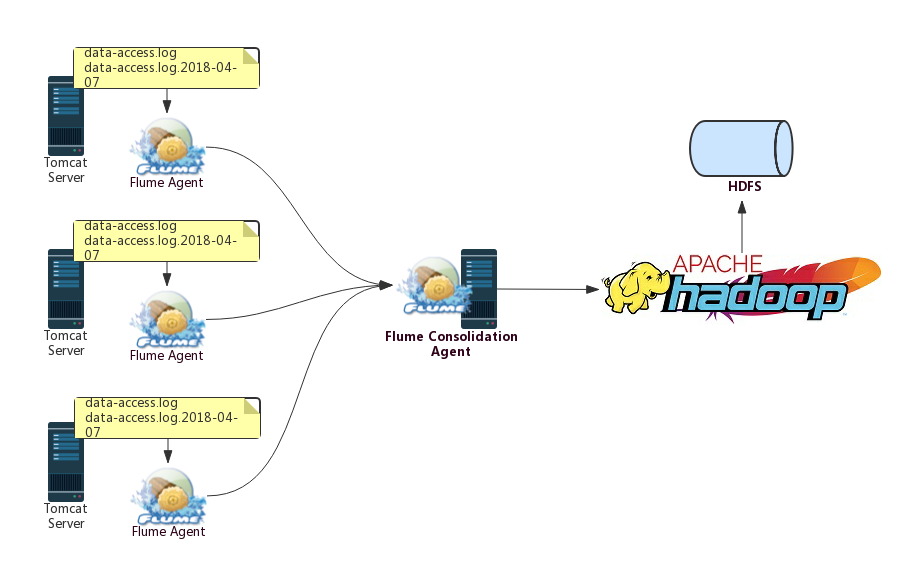
可以看到,不同的Web Server上都会部署一个Agent用于该Server上日志数据的采集,之后,不同Web Server的Flume Agent采集的日志数据会下沉到另外一个被称为Flume Consolidation Agent(聚合Agent)的Flume Agent上,该Flume Agent的数据落地方式为输出到HDFS。
在我们的HDFS中,可以查看到其采集的日志:
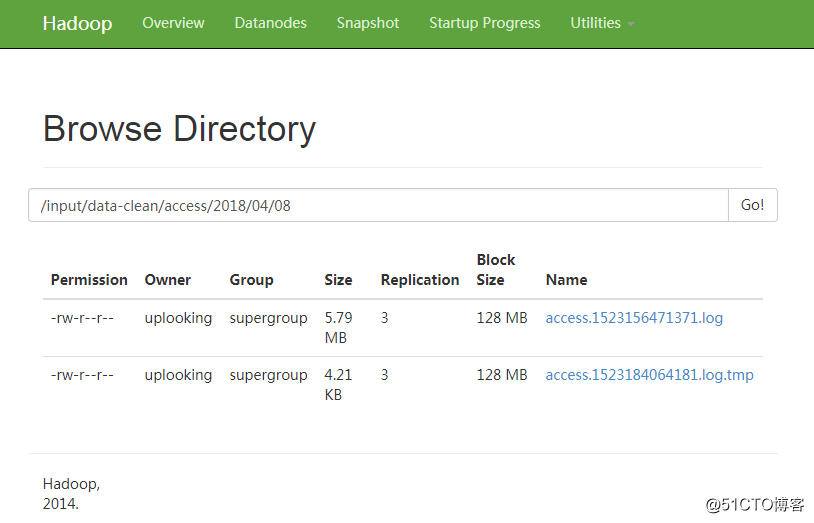
后面我们的工作正是要基于Flume采集到HDFS中的数据做离线处理与分析。
4 数据清洗:将不规整数据转化为规整数据
4.1 数据清洗目的
刚刚采集到HDFS中的原生数据,我们也称为不规整数据,即目前来说,该数据的格式还无法满足我们对数据处理的基本要求,需要对其进行预处理,转化为我们后面工作所需要的较为规整的数据,所以这里的数据清洗,其实指的就是对数据进行基本的预处理,以方便我们后面的统计分析,所以这一步并不是必须的,需要根据不同的业务需求来进行取舍,只是在我们的场景中需要对数据进行一定的处理。
4.2 数据清洗方案
原来的日志数据格式是如下的:
appid ip mid userid login_type request status http_referer user_agent time
其中:
appid包括:web:1000,android:1001,ios:1002,ipad:1003
mid:唯一的id此id第一次会种在浏览器的cookie里。如果存在则不再种。作为浏览器唯一标示。移动端或者pad直接取机器码。
login_type:登录状态,0未登录、1:登录用户
request:类似于此种 "GET /userList HTTP/1.1"
status:请求的状态主要有:200 ok、404 not found、408 Request Timeout、500 Internal Server Error、504 Gateway Timeout等
http_referer:请求该url的上一个url地址。
user_agent:浏览器的信息,例如:"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36"
time:时间的long格式:1451451433818。但是如果需要按照省份来统计uv、pv,其所包含的信息还不够,我们需要对这些数据做一定的预处理,比如需要,对于其中包含的IP信息,我们需要将其对应的IP信息解析出来;为了方便我们的其它统计,我们也可以将其request信息解析为method、 request_url、 http_version等,
所以按照上面的分析,我们希望预处理之后的日志数据包含如下的数据字段:
appid;
ip;
//通过ip来衍生出来的字段 province和city
province;
city;
mid;
userId;
loginType;
request;
//通过request 衍生出来的字段 method request_url http_version
method;
requestUrl;
httpVersion;
status;
httpReferer;
userAgent;
//通过userAgent衍生出来的字段,即用户的浏览器信息
browser;
time;即在原来的基础上,我们增加了其它新的字段,如province、city等。
我们采用MapReduce来对数据进行预处理,预处理之后的结果,我们也是保存到HDFS中,即采用如下的架构:

4.3 数据清洗过程:MapReduce程序编写
数据清洗的过程主要是编写MapReduce程序,而MapReduce程序的编写又分为写Mapper、Reducer、Job三个基本的过程。但是在我们这个案例中,要达到数据清洗的目的,实际上只需要Mapper就可以了,并不需要Reducer,原因很简单,我们只是预处理数据,在Mapper中就已经可以对数据进行处理了,其输出的数据并不需要进一步经过Redcuer来进行汇总处理。
所以下面就直接编写Mapper和Job的程序代码。
4.3.1 AccessLogCleanMapper
package cn.xpleaf.dataClean.mr.mapper;
import cn.xpleaf.dataClean.mr.writable.AccessLogWritable;
import cn.xpleaf.dataClean.utils.JedisUtil;
import cn.xpleaf.dataClean.utils.UserAgent;
import cn.xpleaf.dataClean.utils.UserAgentUtil;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.log4j.Logger;
import redis.clients.jedis.Jedis;
import java.io.IOException;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* access日志清洗的主要mapper实现类
* 原始数据结构:
* appid ip mid userid login_tpe request status http_referer user_agent time ---> 10列内容
* 清洗之后的结果:
* appid ip province city mid userid login_type request method request_url http_version status http_referer user_agent browser yyyy-MM-dd HH:mm:ss
*/
public class AccessLogCleanMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
private Logger logger;
private String[] fields;
private String appid; //数据来源 web:1000,android:1001,ios:1002,ipad:1003
private String ip;
//通过ip来衍生出来的字段 province和city
private String province;
private String city;
private String mid; //mid:唯一的id此id第一次会种在浏览器的cookie里。如果存在则不再种。作为浏览器唯一标示。移动端或者pad直接取机器码。
private String userId; //用户id
private String loginType; //登录状态,0未登录、1:登录用户
private String request; //类似于此种 "GET userList HTTP/1.1"
//通过request 衍生出来的字段 method request_url http_version
private String method;
private String requestUrl;
private String httpVersion;
private String status; //请求的状态主要有:200 ok、/404 not found、408 Request Timeout、500 Internal Server Error、504 Gateway Timeout等
private String httpReferer; //请求该url的上一个url地址。
private String userAgent; //览器的信息,例如:"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36"
//通过userAgent来获取对应的浏览器
private String browser;
//private long time; //action对应的时间戳
private String time;//action对应的格式化时间yyyy-MM-dd HH:mm:ss
private DateFormat df;
private Jedis jedis;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
logger = Logger.getLogger(AccessLogCleanMapper.class);
df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
jedis = JedisUtil.getJedis();
}
/**
* appid ip mid userid login_tpe request status http_referer user_agent time ---> 10列内容
* ||
* ||
* appid ip province city mid userid login_type request method request_url http_version status http_referer user_agent browser yyyy-MM-dd HH:mm:ss
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
fields = value.toString().split("\t");
if (fields == null || fields.length != 10) { // 有异常数据
return;
}
// 因为所有的字段没有进行特殊操作,只是文本的输出,所以没有必要设置特定类型,全部设置为字符串即可,
// 这样在做下面的操作时就可以省去类型的转换,但是如果对数据的合法性有严格的验证的话,则要保持类型的一致
appid = fields[0];
ip = fields[1];
// 解析IP
if (ip != null) {
String ipInfo = jedis.hget("ip_info", ip);
province = ipInfo.split("\t")[0];
city = ipInfo.split("\t")[1];
}
mid = fields[2];
userId = fields[3];
loginType = fields[4];
request = fields[5];
method = request.split(" ")[0];
requestUrl = request.split(" ")[1];
httpVersion = request.split(" ")[2];
status = fields[6];
httpReferer = fields[7];
userAgent = fields[8];
if (userAgent != null) {
UserAgent uAgent = UserAgentUtil.getUserAgent(userAgent);
if (uAgent != null) {
browser = uAgent.getBrowserType();
}
}
try { // 转换有可能出现异常
time = df.format(new Date(Long.parseLong(fields[9])));
} catch (NumberFormatException e) {
logger.error(e.getMessage());
}
AccessLogWritable access = new AccessLogWritable(appid, ip, province, city, mid,
userId, loginType, request, method, requestUrl,
httpVersion, status, httpReferer, this.userAgent, browser, time);
context.write(NullWritable.get(), new Text(access.toString()));
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
// 资源释放
logger = null;
df = null;
JedisUtil.returnJedis(jedis);
}
}4.3.2 AccessLogCleanJob
package cn.xpleaf.dataClean.mr.job;
import cn.xpleaf.dataClean.mr.mapper.AccessLogCleanMapper;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* 清洗用户access日志信息
* 主要的驱动程序
* 主要用作组织mapper和reducer的运行
*
* 输入参数:
* hdfs://ns1/input/data-clean/access/2018/04/08 hdfs://ns1/output/data-clean/access
* 即inputPath和outputPath
* 目前outputPath统一到hdfs://ns1/output/data-clean/access
* 而inputPath则不确定,因为我们的日志采集是按天来生成一个目录的
* 所以上面的inputPath只是清洗2018-04-08这一天的
*/
public class AccessLogCleanJob {
public static void main(String[] args) throws Exception {
if(args == null || args.length < 2) {
System.err.println("Parameter Errors! Usage <inputPath...> <outputPath>");
System.exit(-1);
}
Path outputPath = new Path(args[args.length - 1]);
Configuration conf = new Configuration();
String jobName = AccessLogCleanJob.class.getSimpleName();
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(AccessLogCleanJob.class);
// 设置mr的输入参数
for( int i = 0; i < args.length - 1; i++) {
FileInputFormat.addInputPath(job, new Path(args[i]));
}
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(AccessLogCleanMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
// 设置mr的输出参数
outputPath.getFileSystem(conf).delete(outputPath, true); // 避免job在运行的时候出现输出目录已经存在的异常
FileOutputFormat.setOutputPath(job, outputPath);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(0); // map only操作,没有reducer
job.waitForCompletion(true);
}
}4.3.3 执行MapReduce程序
将上面的mr程序打包后上传到我们的Hadoop环境中,这里,对2018-04-08这一天产生的日志数据进行清洗,执行如下命令:
yarn jar data-extract-clean-analysis-1.0-SNAPSHOT-jar-with-dependencies.jarcn.xpleaf.dataClean.mr.job.AccessLogCleanJob hdfs://ns1/input/data-clean/access/2018/04/08 hdfs://ns1/output/data-clean/access观察其执行结果:
......
18/04/08 20:54:21 INFO mapreduce.Job: Running job: job_1523133033819_0009
18/04/08 20:54:28 INFO mapreduce.Job: Job job_1523133033819_0009 running in uber mode : false
18/04/08 20:54:28 INFO mapreduce.Job: map 0% reduce 0%
18/04/08 20:54:35 INFO mapreduce.Job: map 50% reduce 0%
18/04/08 20:54:40 INFO mapreduce.Job: map 76% reduce 0%
18/04/08 20:54:43 INFO mapreduce.Job: map 92% reduce 0%
18/04/08 20:54:45 INFO mapreduce.Job: map 100% reduce 0%
18/04/08 20:54:46 INFO mapreduce.Job: Job job_1523133033819_0009 completed successfully
18/04/08 20:54:46 INFO mapreduce.Job: Counters: 31
......可以看到MapReduce Job执行成功!
4.4 数据清洗结果
上面的MapReduce程序执行成功后,可以看到在HDFS中生成的数据输出目录:
我们可以下载其中一个结果数据文件,并用Notepadd++打开查看其数据信息:

5 数据处理:对规整数据进行统计分析
经过数据清洗之后,就得到了我们做数据的分析统计所需要的比较规整的数据,下面就可以进行数据的统计分析了,即按照业务需求,统计出某一天中每个省份的PV和UV。
我们依然是需要编写MapReduce程序,并且将数据保存到HDFS中,其架构跟前面的数据清洗是一样的:
5.1 数据处理思路:如何编写MapReduce程序
现在我们已经得到了规整的数据,关于在于如何编写我们的MapReduce程序。
因为要统计的是每个省对应的pv和uv,pv就是点击量,uv是独立访客量,需要将省相同的数据拉取到一起,拉取到一块的这些数据每一条记录就代表了一次点击(pv + 1),这里面有同一个用户产生的数据(通过mid来唯一地标识是同一个浏览器,用mid进行去重,得到的就是uv)。
而拉取数据,可以使用Mapper来完成,对数据的统计(pv、uv的计算)则可以通过Reducer来完成,即Mapper的各个参数可以为如下:
Mapper<LongWritable, Text, Text(Province), Text(mid)>而Reducer的各个参数可以为如下:
Reducer<Text(Province), Text(mid), Text(Province), Text(pv + uv)>5.2 数据处理过程:MapReduce程序编写
根据前面的分析,来编写我们的MapReduce程序。
5.2.1 ProvincePVAndUVMapper
package cn.xpleaf.dataClean.mr.mapper;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Mapper<LongWritable, Text, Text(Province), Text(mid)>
* Reducer<Text(Province), Text(mid), Text(Province), Text(pv + uv)>
*/
public class ProvincePVAndUVMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
if(fields == null || fields.length != 16) {
return;
}
String province = fields[2];
String mid = fields[4];
context.write(new Text(province), new Text(mid));
}
}5.2.2 ProvincePVAndUVReducer
package cn.xpleaf.dataClean.mr.reducer;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
/**
* 统计该标准化数据,产生结果
* 省 pv uv
* 这里面有同一个用户产生的数|据(通过mid来唯一地标识是同一个浏览器,用mid进行去重,得到的就是uv)
* Mapper<LongWritable, Text, Text(Province), Text(mid)>
* Reducer<Text(Province), Text(mid), Text(Province), Text(pv + uv)>
*/
public class ProvincePVAndUVReducer extends Reducer<Text, Text, Text, Text> {
private Set<String> uvSet = new HashSet<>();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
long pv = 0;
uvSet.clear();
for(Text mid : values) {
pv++;
uvSet.add(mid.toString());
}
long uv = uvSet.size();
String pvAndUv = pv + "\t" + uv;
context.write(key, new Text(pvAndUv));
}
}5.2.3 ProvincePVAndUVJob
package cn.xpleaf.dataClean.mr.job;
import cn.xpleaf.dataClean.mr.mapper.ProvincePVAndUVMapper;
import cn.xpleaf.dataClean.mr.reducer.ProvincePVAndUVReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* 统计每个省的pv和uv值
* 输入:经过clean之后的access日志
* appid ip province city mid userid login_type request method request_url http_version status http_referer user_agent browser yyyy-MM-dd HH:mm:ss
* 统计该标准化数据,产生结果
* 省 pv uv
*
* 分析:因为要统计的是每个省对应的pv和uv
* pv就是点击量,uv是独立访客量
* 需要将省相同的数据拉取到一起,拉取到一块的这些数据每一条记录就代表了一次点击(pv + 1)
* 这里面有同一个用户产生的数据(通过mid来唯一地标识是同一个浏览器,用mid进行去重,得到的就是uv)
* Mapper<LongWritable, Text, Text(Province), Text(mid)>
* Reducer<Text(Province), Text(mid), Text(Province), Text(pv + uv)>
*
* 输入参数:
* hdfs://ns1/output/data-clean/access hdfs://ns1/output/pv-uv
*/
public class ProvincePVAndUVJob {
public static void main(String[] args) throws Exception {
if (args == null || args.length < 2) {
System.err.println("Parameter Errors! Usage <inputPath...> <outputPath>");
System.exit(-1);
}
Path outputPath = new Path(args[args.length - 1]);
Configuration conf = new Configuration();
String jobName = ProvincePVAndUVJob.class.getSimpleName();
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(ProvincePVAndUVJob.class);
// 设置mr的输入参数
for (int i = 0; i < args.length - 1; i++) {
FileInputFormat.addInputPath(job, new Path(args[i]));
}
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(ProvincePVAndUVMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 设置mr的输出参数
outputPath.getFileSystem(conf).delete(outputPath, true); // 避免job在运行的时候出现输出目录已经存在的异常
FileOutputFormat.setOutputPath(job, outputPath);
job.setOutputFormatClass(TextOutputFormat.class);
job.setReducerClass(ProvincePVAndUVReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(1);
job.waitForCompletion(true);
}
}5.2.4 执行MapReduce程序
将上面的mr程序打包后上传到我们的Hadoop环境中,这里,对前面预处理之后的数据进行统计分析,执行如下命令:
yarn jar data-extract-clean-analysis-1.0-SNAPSHOT-jar-with-dependencies.jar cn.xpleaf.dataClean.mr.job.ProvincePVAndUVJob hdfs://ns1/output/data-clean/access hdfs://ns1/output/pv-uv观察其执行结果:
......
18/04/08 22:22:42 INFO mapreduce.Job: Running job: job_1523133033819_0010
18/04/08 22:22:49 INFO mapreduce.Job: Job job_1523133033819_0010 running in uber mode : false
18/04/08 22:22:49 INFO mapreduce.Job: map 0% reduce 0%
18/04/08 22:22:55 INFO mapreduce.Job: map 50% reduce 0%
18/04/08 22:22:57 INFO mapreduce.Job: map 100% reduce 0%
18/04/08 22:23:03 INFO mapreduce.Job: map 100% reduce 100%
18/04/08 22:23:03 INFO mapreduce.Job: Job job_1523133033819_0010 completed successfully
18/04/08 22:23:03 INFO mapreduce.Job: Counters: 49
......可以看到MapReduce Job执行成功!
5.3 数据处理结果
上面的MapReduce程序执行成功后,可以看到在HDFS中生成的数据输出目录:

我们可以下载其结果数据文件,并用Notepadd++打开查看其数据信息:

至此,就完成了一个完整的数据采集、清洗、处理的完整离线数据分析案例。
相关的代码我已经上传到GitHub,有兴趣可以参考一下:
https://github.com/xpleaf/data-extract-clean-analysis
以上是关于大数据采集清洗处理:使用MapReduce进行离线数据分析完整案例的主要内容,如果未能解决你的问题,请参考以下文章
大数据采集清洗处理:使用MapReduce进行离线数据分析完整案例
ETL项目2:大数据清洗,处理:使用MapReduce进行离线数据分析并报表显示完整项目
Flume+Kafka+Storm+Redis构建大数据实时处理系统:实时统计网站PVUV+展示