OkHttp源码分析:五大拦截器详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OkHttp源码分析:五大拦截器详解相关的知识,希望对你有一定的参考价值。
参考技术A主要完成两件事: 重试与重定向
重试与重定向拦截器主要处理Response,可以看到RouteException和IOException都是调用了recover,返回true表示允许重试。允许重试—>continue—> while (true)—>realChain.proceed,这就完成了重试的过程。
接着看重定向
重定向总结
另附HTTP响应状态码分类:
小结: RetryAndFollowUpInterceptor是整个责任链中的第一个,首次接触到Request和最后接收Response的角色,它的主要功能是判断是否需要重试与重定向。
重试的前提是出现了RouteException或IOException,会通过recover方法进行判断是否进行重试。
重定向是发生在重试判定后,不满足重试的条件,会进一步调用followUpRequest根据Response的响应码进行重定向操作。
补全请求头:
小结: BridgeInterceptor是连接应用程序和服务器的桥梁,它为我们补全请求头,将请求转化为符合网络规范的Request。得到响应后:1.保存Cookie,在下次请求会读取对应的cookie数据设置进请求头,默认cookieJar不提供的实现 2.如果使用gzip返回的数据,则使用 GzipSource 包装便于解析。
缓存拦截器顾名思义处理缓存的,但是要建立在get请求的基础上,我们可以去通过okHttpClient.cache(cache)去设置。缓存拦截器的处理流程:
1.从缓存中取出对应请求的响应缓存
2.通过CacheStrategy判断使用缓存或发起网络请求,此对象中的networkRequest代表需要发起网络请求,cacheResponse表示直接使用缓存。
即: networkRequest存在则优先发起网络请求,否则使用cacheResponse缓存,若都不存在则请求失败。
如果最终判定不能使用缓存,需要发起网络请求,则来到下一个拦截器ConnectInterceptor
StreamAllocation对象是在第一个拦截器RetryAndFollowUpInterceptor中初始化完成的(设置了连接池、url路径等),当一个请求发出,需要建立连接,建立连接之后需要使用流来读取数据,这个StreamAllocation就是协调请求、连接与数据流三者之前的关系,它负责为一次请求寻找连接,然后获得流来实现网络通信。
StreamAllocation对象有两个关键角色:
真正的连接是在RealConnection中实现的,连接由ConnectionPool管理。
接着我们看下RealConnection的创建和连接的建立:
streamAllocation.newStream—>findHealthyConnection—>findConnection
findConnection:
①StreamAllocation的connection如果可以复用则复用
②如果connection不能复用,则从连接池中获取RealConnection对象,获取成功则返回
③如果连接池里没有,则new一个RealConnection对象
④调用RealConnection的connect()方法发起请求
⑤将RealConnection对象存进连接池中,以便下次复用
⑥返回RealConnection对象
小结:
ConnectInterceptor拦截器从拦截器链中获取StreamAllocation对象,这个对象在第一个拦截器中创建,在ConnectInterceptor中才用到。
执行StreamAllocation对象的newStream方法创建HttpCodec对象,用来编码HTTP request和解码HTTP response。
newStream方法里面通过findConnection方法返回了一个RealConnection对象。
StreamAllocation对象的connect方法拿到上面返回的RealConnection对象,这个RealConnection对象是用来进行实际的网络IO传输的。
writeRequestHeaders和readResponseHeaders(以Http2Codec为例)
小结: CallServerInterceptor完成HTTP协议报文的封装和解析。
①获取拦截器链中的HttpCodec、StreamAllocation、RealConnection对象
②调用httpCodec.writeRequestHeaders(request)将请求头写入缓存
③判断是否有请求体,如果有,请求头通过携带特殊字段 Expect:100-continue来询问服务器是否愿意接受请求体。(一般用于上传大容量请求体或者需要验证)
④通过httpCodec.finishRequest()结束请求
⑤通过responseBuilder构建Response
⑥返回Response
OkHttp3 拦截器源码分析
OkHttp 内置拦截器
在这篇博客 OkHttp3 拦截器(Interceptor) ,我们已经介绍了拦截器的作用,拦截器是 OkHttp 提供的对 Http 请求和响应进行统一处理的强大机制,它可以实现网络监听、请求以及响应重写、请求失败充实等功能。
同时也了解了拦截器可以被链接起来使用,我们可以注册自定义的拦截器(应用拦截器和网络拦截器)到拦截器链上,如下图:
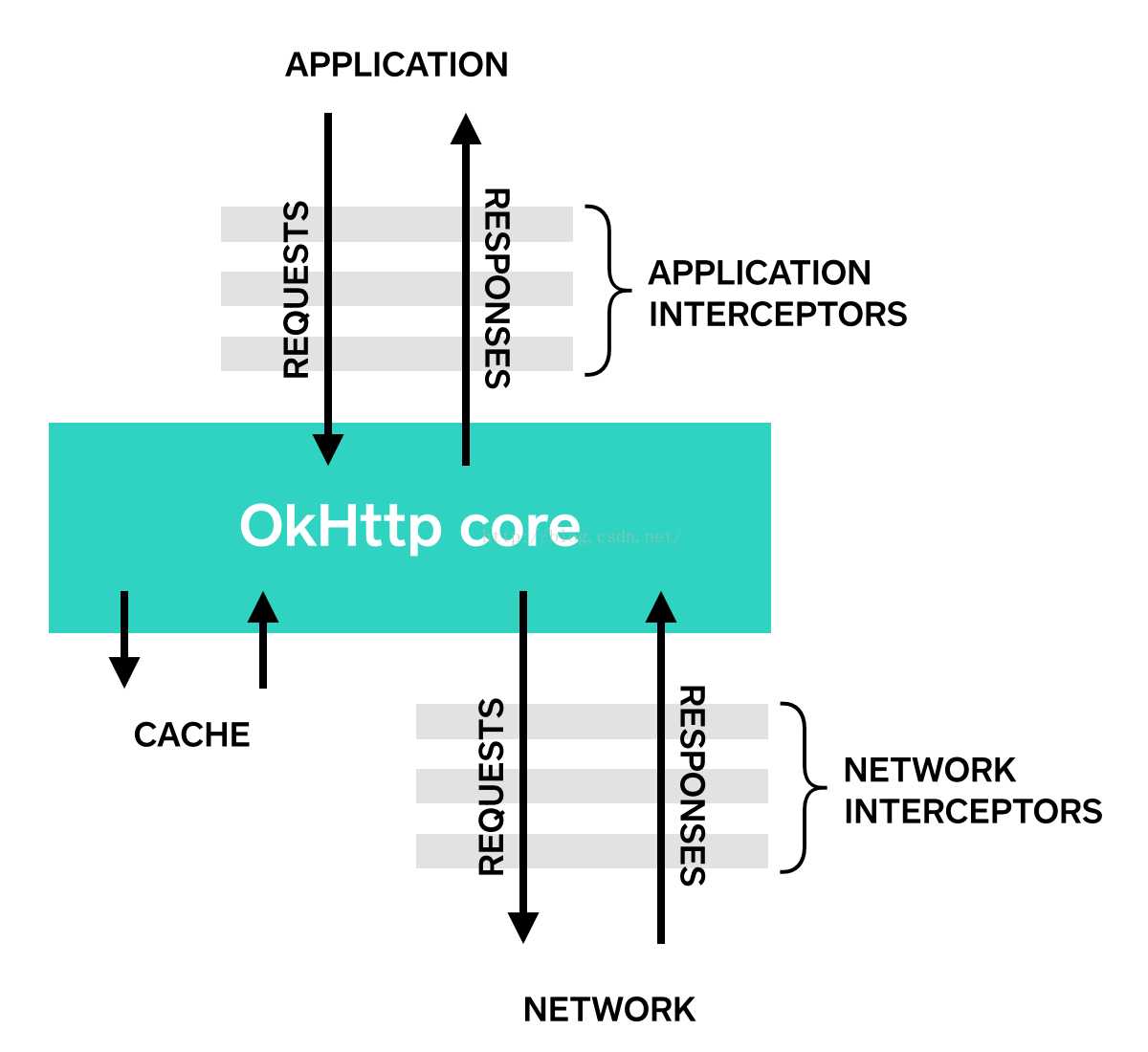
实际上除了我们自定义的拦截器外,OkHttp 系统内部还提供了几种其他的拦截器,就是上图中 OkHttp core 的部分。OkHttp 内部的拦截器各自负责不同的功能,每一个功能就是一个 Interceptor,这些拦截器连接起来形成了一个拦截器链,最终也就完成了一次网络请求。
具体如下图:
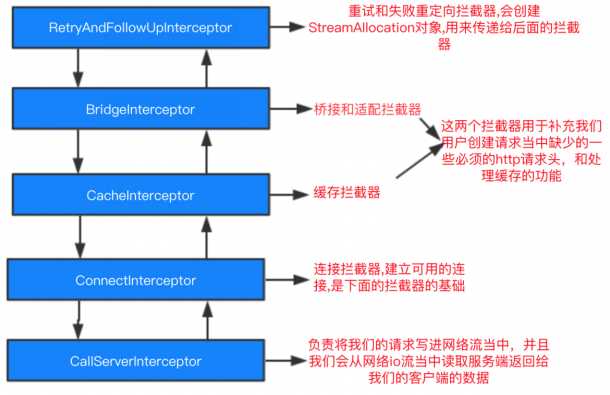
在上一篇博客 OkHttp3 源码分析 中,我们分析了 OkHttp 的同步和异步请求的流程源码,发现无论是同步请求还是异步请求都是通过调用 RealCall 的 getResponseWithInterceptorChain() 方法来获取 response 响应的。
RealCall. getResponseWithInterceptorChain()源码:
Response getResponseWithInterceptorChain() throws IOException {
List<Interceptor> interceptors = new ArrayList();
//添加自定义的应用拦截器
interceptors.addAll(this.client.interceptors());
//负责重定向和失败重试的拦截器
interceptors.add(this.retryAndFollowUpInterceptor);
//桥接网络层和应用层,就是为用户所创建的请求补充添加一些服务端还必需的 http 请求头等
interceptors.add(new BridgeInterceptor(this.client.cookieJar()));
//负责读取缓存,更新缓存
interceptors.add(new CacheInterceptor(this.client.internalCache()));
//负责与服务端建立连接
interceptors.add(new ConnectInterceptor(this.client));
//配置自定义的网络拦截器
if (!this.forWebSocket) {
interceptors.addAll(this.client.networkInterceptors());
}
//向服务端发送请求,从服务端读取响应数据
interceptors.add(new CallServerInterceptor(this.forWebSocket));
//创建 拦截器链chain 对象,这里将各种拦截器的 List 集合传了进去
Chain chain = new RealInterceptorChain(interceptors, (StreamAllocation)null, (HttpCodec)null, (RealConnection)null, 0, this.originalRequest, this, this.eventListener, this.client.connectTimeoutMillis(), this.client.readTimeoutMillis(), this.client.writeTimeoutMillis());
//通过链式请求得到 response
return chain.proceed(this.originalRequest);
}在这个方法中,我们就发现了 OkHttp 内置的这几种拦截器,这几种拦截器的具体作用稍后再说,先来宏观的分析一下 getResponseWithInterceptorChain() 做了些什么工作:
- 创建了一系列的拦截器,并将其放入一个拦截器 List 集合中。
- 将拦截器的 List 集合传入 RealInterceptorChain 的构造方法中,创建出一个拦截器链 RealInterceptorChain 。
- 执行拦截器链 chain 的 proceed() 方法来依次调用每个不同功能的拦截器,最终获取响应。
那么这个 Chain 对象到底是如何处理拦截器集合的呢,为什么通过调用 chain.proceed 就能得到被拦截器链依次处理之后的 response 呢?
其实这个问题的答案就是责任链设计模式,建议先了解一下关于责任链模式的介绍,再回头往下看。
在理解了责任链模式之后,我们就能比较容易的理解拦截器是如何工作的了。
首先来看一看 Interceptor 接口,很明显的它就是责任链模式中的抽象处理者角色了,各种拦截器都需要实现它的 intercept 方法
/**
* Observes, modifies, and potentially short-circuits requests going out and the corresponding
* responses coming back in. Typically interceptors add, remove, or transform headers on the request
* or response.
*/
public interface Interceptor {
Response intercept(Chain chain) throws IOException;
interface Chain {
Request request();
Response proceed(Request request) throws IOException;
...
}
}这里我们注意到 Interceptor 还包含了一个内部接口 Chain,通过查看 Chain 接口,也可以大概了解它的功能:
- 通过 request() 方法来获取 request 请求
- 通过 proceed(request) 方法来处理 request 请求,并返回 response 响应
刚刚也介绍了在 getResponseWithInterceptorChain() 方法中,正是由 Chain 来依次调用拦截器来获取 response 的:
//创建 拦截器链chain 对象,这里将各种拦截器的 List 集合传了进去
Chain chain = new RealInterceptorChain(interceptors, (StreamAllocation)null, (HttpCodec)null, (RealConnection)null, 0, this.originalRequest, this, this.eventListener, this.client.connectTimeoutMillis(), this.client.readTimeoutMillis(), this.client.writeTimeoutMillis());
//通过链式请求得到 response
return chain.proceed(this.originalRequest);那么它具体是怎么工作的呢?我们先来看一下RealInterceptorChain 的构造方法
public final class RealInterceptorChain implements Interceptor.Chain {
private final List<Interceptor> interceptors;
private final StreamAllocation streamAllocation;
private final HttpCodec httpCodec;
private final RealConnection connection;
private final int index;
private final Request request;
private final Call call;
private final EventListener eventListener;
private final int connectTimeout;
private final int readTimeout;
private final int writeTimeout;
private int calls;
public RealInterceptorChain(List<Interceptor> interceptors, StreamAllocation streamAllocation,
HttpCodec httpCodec, RealConnection connection, int index, Request request, Call call,
EventListener eventListener, int connectTimeout, int readTimeout, int writeTimeout) {
this.interceptors = interceptors;
this.connection = connection;
this.streamAllocation = streamAllocation;
this.httpCodec = httpCodec;
this.index = index;
this.request = request;
this.call = call;
this.eventListener = eventListener;
this.connectTimeout = connectTimeout;
this.readTimeout = readTimeout;
this.writeTimeout = writeTimeout;
}需要特别注意的是这个构造方法里的 index 参数,传入给构造方法的 index 最终被赋值给了一个全局变量 index(这个变量很重要,之后会被使用到)。在构造出了 RealInterceptorChain 对象之后,接着就调用它的 proceed 方法来执行拦截器了。
来看一下 chain.proceed(request) 方法的具体实现:
RealInterceptorChain#proceed:
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec,
RealConnection connection) throws IOException {
if (index >= interceptors.size()) throw new AssertionError();
calls++;
...
// Call the next interceptor in the chain.
RealInterceptorChain next = new RealInterceptorChain(interceptors, streamAllocation, httpCodec,
connection, index + 1, request, call, eventListener, connectTimeout, readTimeout,
writeTimeout);
//从拦截器集合中获取当前拦截器
Interceptor interceptor = interceptors.get(index);
//调用当前的拦截器的 intercept 方法获取 response
Response response = interceptor.intercept(next);
...
return response;
}这个方法的关键逻辑在这与这三行代码
一, 在 chain.proceed 的方法中,又 new 了一个 RealInterceptorChain,不过这里传入的参数是 index + 1,也就是说,每次调用 proceed 方法,都会产生出一个 index成员变量 +1的 RealInterceptorChain 对象。而且该 chain 对象的名字为 next,所以我们大致也能猜测一下它代表的是下一个 chain 对象。
RealInterceptorChain next = new RealInterceptorChain(interceptors, streamAllocation, httpCodec,
connection, index + 1, request, call, eventListener, connectTimeout, readTimeout,
writeTimeout);二, 根据 index 索引值获取当前拦截器,这个 index 就是之前创建 chain 构造函数时的 index 值
大家应该还记得在 getResponseWithInterceptorChain 第一次创建 Chain 对象时,index被初始化为0。
Interceptor interceptor = interceptors.get(index);三, 调用当前拦截器的 intercept(Chain chain) 方法
Response response = interceptor.intercept(next);这里我们就以 index 为 0 为例,获取 interceptors 集合中的第一个拦截器 RetryAndFollowUpInterceptor(假设没有添加用户自定义的应用拦截器),来看一下它的 intercept 方法:
@Override public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Call call = realChain.call();
EventListener eventListener = realChain.eventListener();
StreamAllocation streamAllocation = new StreamAllocation(client.connectionPool(),
createAddress(request.url()), call, eventListener, callStackTrace);
this.streamAllocation = streamAllocation;
int followUpCount = 0;
Response priorResponse = null;
while (true) {
if (canceled) {
streamAllocation.release();
throw new IOException("Canceled");
}
Response response;
boolean releaseConnection = true;
try {
response = realChain.proceed(request, streamAllocation, null, null);
releaseConnection = false;
} catch (RouteException e) {
// The attempt to connect via a route failed. The request will not have been sent.
if (!recover(e.getLastConnectException(), streamAllocation, false, request)) {
throw e.getFirstConnectException();
}
releaseConnection = false;
continue;
} catch (IOException e) {
// An attempt to communicate with a server failed. The request may have been sent.
boolean requestSendStarted = !(e instanceof ConnectionShutdownException);
if (!recover(e, streamAllocation, requestSendStarted, request)) throw e;
releaseConnection = false;
continue;
} finally {
// We‘re throwing an unchecked exception. Release any resources.
if (releaseConnection) {
streamAllocation.streamFailed(null);
streamAllocation.release();
}
}
...
}
}这段代码中最关键的地方是:
response = realChain.proceed(request, streamAllocation, null, null);我们发现,原来在 intercept() 中又会调用 chain.proceed() 方法,而每次调用 proceed 方法中又会去获取一个索引为 index + 1 的下一个拦截器,并执行该拦截器的 intercept() 方法,就是这样相互的递归调用,实现了对拦截器的逐步调用。
这个过程流程图如下:
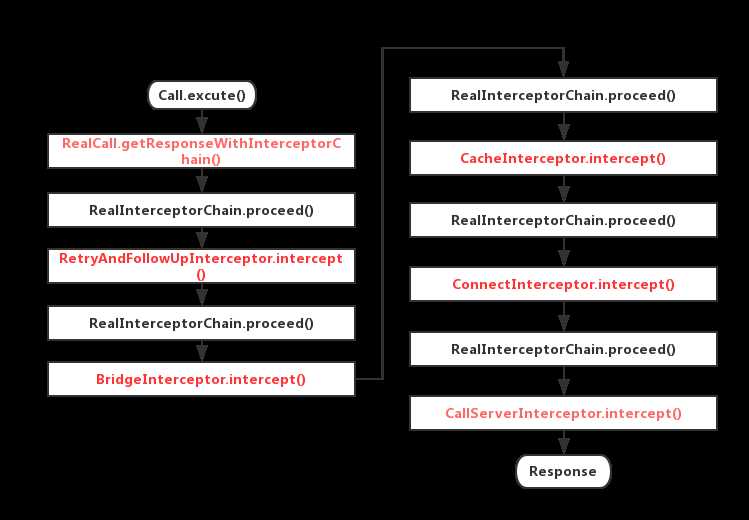
到这里也许我们会有一个疑问,那就是为什么每次都需要创建一个新的 RealInterceptorChain 对象,只需要修改 index 变量的值不是也能实现同样的效果吗?这里的原因是 RealInterceptorChain 对象中还包含了 request 请求信息在内的其他信息,而每次执行拦截器的 intercept 方法时,因为递归调用的缘故,本层 的 intercept 并没有被执行完,如果复用 RealInterceptorChain 对象,则其他层次会对本层次 RealInterceptorChain 对象产生影响。
参考
https://blog.csdn.net/aiynmimi/article/details/79643123
https://blog.csdn.net/qq_16445551/article/details/79008433
以上是关于OkHttp源码分析:五大拦截器详解的主要内容,如果未能解决你的问题,请参考以下文章