OkHttp 基本使用&源码分析
Posted 敲行代码再睡觉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OkHttp 基本使用&源码分析相关的知识,希望对你有一定的参考价值。
❝本文介绍了 OkHttp 的基本使用以及源码分析,强烈建议配合源码进行阅读,否则会不知所云!!!
第一次写源码分析类文章,辛苦各位老铁指正
本文基于 「OkHttp 3.11.0 版本」进行分析,查看源码时请对应,或者直接下载文末的 Demo 进行查看
❞
OkHttp 的基本使用
同步请求
异步请求
OkHttp 的源码分析
同步请求
异步请求
OkHttp 的任务调度(Dispatcher)
OkHttp 拦截器
官方定义
基本流程
RetryAndFollowUpInterceptor(重试)
BridgeInterceptor(桥接)
CacheInterceptor(缓存)
ConnectInterceptor(连接)
CallServerInterceptor(请求)
OkHttp 的基本使用
同步请求
-
创建 OkHttpClient 和 Request 对象 -
将 Request 封装成 Call 对象 -
调用 Call 的 execute() 发送同步请求
private fun synRequest() {
val client = OkHttpClient.Builder().readTimeout(5, TimeUnit.SECONDS).build()//1
val request = Request.Builder().url("https://www.baidu.com")
.get().build()//2
GlobalScope.launch(Dispatchers.Main) {
text.text = withContext(Dispatchers.IO) {
val call = client.newCall(request)//3
val response = call.execute()//4
response.body()?.string()
}
}
}
注意事项:
-
发送请求后,就会进入阻塞状态,直到收到响应
异步请求
-
创建 OkHttpClient和 Request 对象 -
将 Request封装成 Call 对象 -
调用 Call 的 enqueue 方法进行异步请求
private fun asyncRequest() {
val client = OkHttpClient.Builder().readTimeout(5, TimeUnit.SECONDS).build()//1
val request = Request.Builder().url("https://www.baidu.com")
.get().build()//2
val call = client.newCall(request)//3
call.enqueue(object : Callback {//4
override fun onFailure(call: Call, e: IOException) {
}
override fun onResponse(call: Call, response: Response) {
Log.d(TAG, "onResponse Thread: ${Thread.currentThread().name}")
val result = response.body()?.string()
GlobalScope.launch(Dispatchers.Main) {
text.text = result
}
}
})
}
注意事项:
-
onResponse 和 onFailure 都回调在 「子线程」中
OkHttp 的源码分析
「总体流程:」
同步请求
同步请求相对简单,从 RealCall.execute 方法开始
「流程图:」

其中 getResponseWithInterceptorChain 方法中的内容将在后面讲述
异步请求
从 RealCall.enqueue 方法开始:
「流程图:」
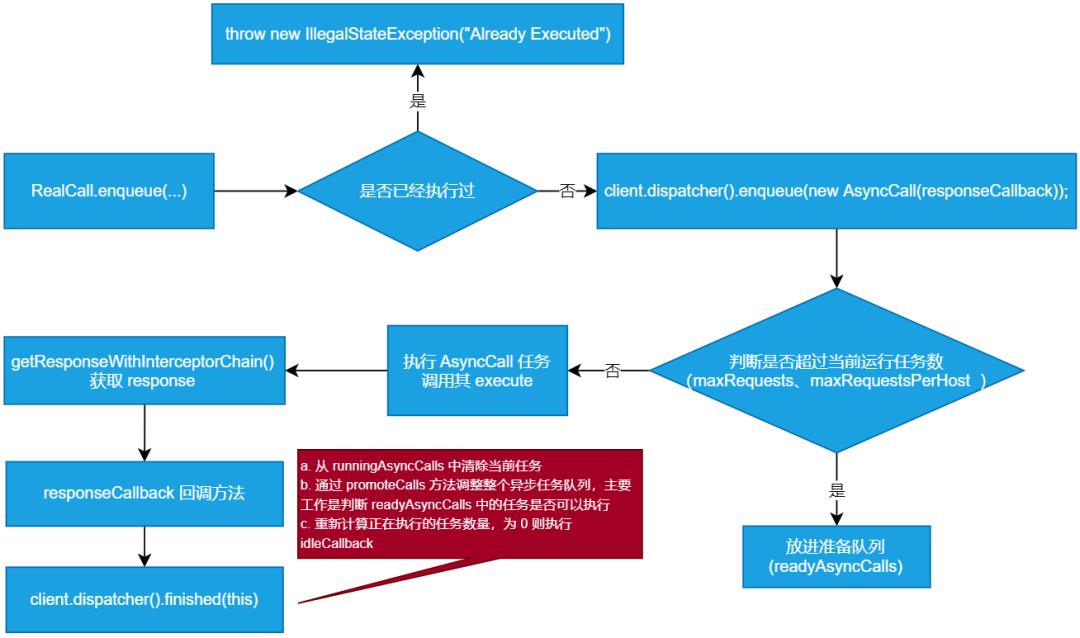
-
判断当前 call 是否只执行了一次,否则抛出异常 -
创建一个 AsyncCall 对象,它其实是一个 Runable 对象 -
通过 client.dispatcher().enqueue() 传入 AsyncCall 对象执行异步请求,如果当前运行的异步任务队列(runningAsyncCalls)元素个数小于 maxRequests 并且当前请求的 Host 个数小于 maxRequestsPerHost 则直接放进运行对象并执行当前的任务,否则放进准备队列中(readyAsyncCalls) -
如果第 3 步可以执行,则会调用 AsyncCall 的 execute 方法,之后调用 getResponseWithInterceptorChain() 获取 Response,执行 onResponse 或 onFailure。这也印证了上面提到的异步任务回调是在子线程中 -
execute 方法末尾会必调 client.dispatcher().finished(this) 方法 -
finished 方法中会做三件事:a. 从 runningAsyncCalls 中清除当前任务 b. 通过 promoteCalls 方法调整整个异步任务队列,主要工作是判断准备队列 readyAsyncCalls 中的任务是否可以执行 c. 重新计算正在执行的任务数量,为 0 则执行 idleCallback
❝默认 maxRequests=64, maxRequestsPerHost=5
❞
OkHttp 的任务调度(Dispatcher)
Dispatcher 用于维护同步和异步的请求状态,并维护一个线程池来执行请求。同步请求相对简单,主要说异步相关的内容,下面代码是 Dispatcher 类中几个非常重要的字段:
/** 线程池,通过懒加载创建. */
private @Nullable ExecutorService executorService;
/** 准备异步任务队列 */
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
/** 正在运行的异步任务队列,包括未结束却已取消的任务 */
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();
/** 正在运行的同步任务队列,包括未结束却已取消的任务 */
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();
executorService 通过懒加载方式创建:
-
corePoolSize 为 0 即核心线程池数量为 0,表示空闲一段时间之后将线程全部销毁 -
maximumPoolSize 线程池最大数量设置为 int 最大值 -
keepAliveTime 当前线程数大于核心线程数时多余空闲线程存活的时间,即 60s
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false));
}
return executorService;
}
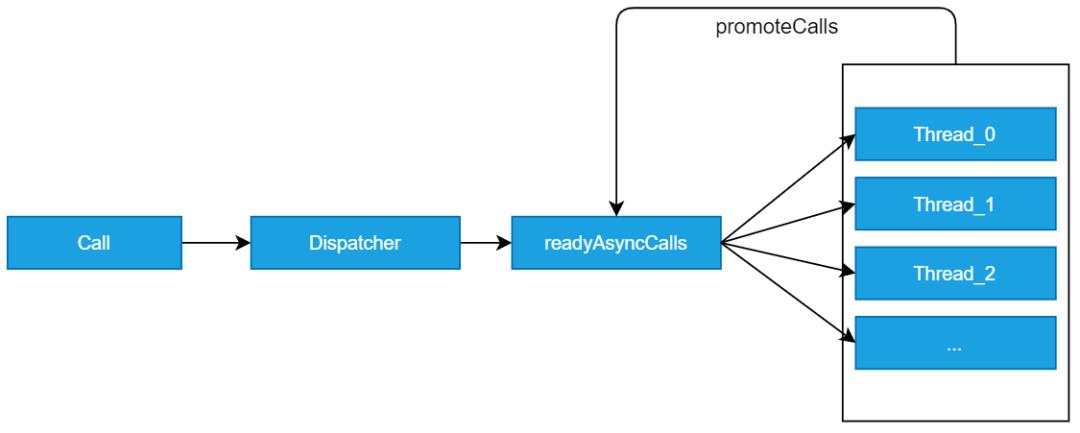
「异步请求为什么需要两个队列?」
可以理解成生产者和消费者模型
-
dispatcher 生产者 -
executorService 消费者池 -
readyAsyncCalls 缓存 -
runningAsyncCalls 正在运行的任务
「readyAsyncCalls 队列中的线程调用时机在哪?」
从上一小节的流程图就可以看出 AsyncCall 的 execute 方法调用结束后必然调用 「client.dispatcher().finished(this)」,最终会走到 Dispatcher.promoteCalls 方法中,判断 runningAsyncCalls 的数量是否符合要求,若符合则直接添加到 runningAsyncCalls 队列中并通过线程池执行任务
private void promoteCalls() {
if (runningAsyncCalls.size() >= maxRequests) return; // Already running max capacity.
if (readyAsyncCalls.isEmpty()) return; // No ready calls to promote.
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}
「流程图:」
OkHttp 拦截器
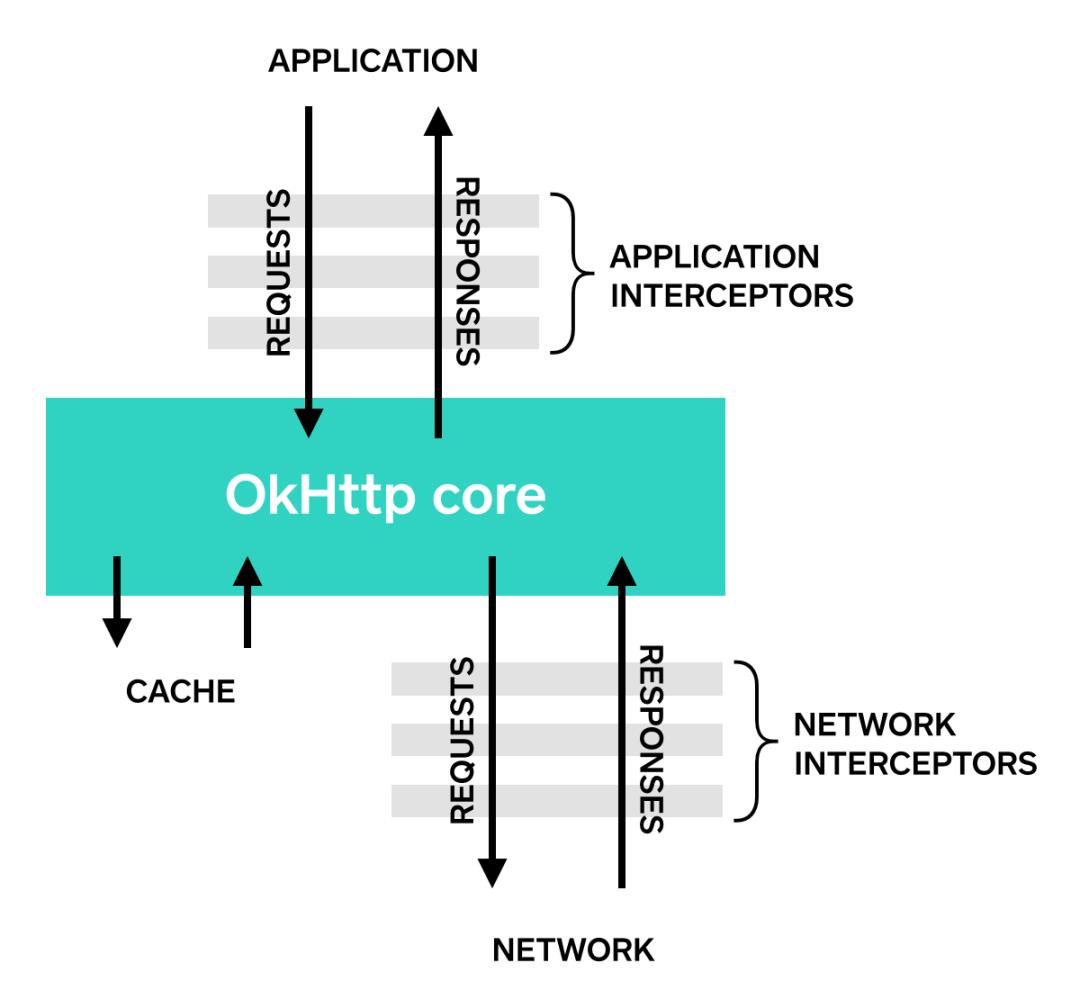
官方定义
拦截器是 OkHttp 中提供一种强大机制,它可以实现网络监听、请求以及响应重写、请求失败重试等功能
基本流程
「流程图」
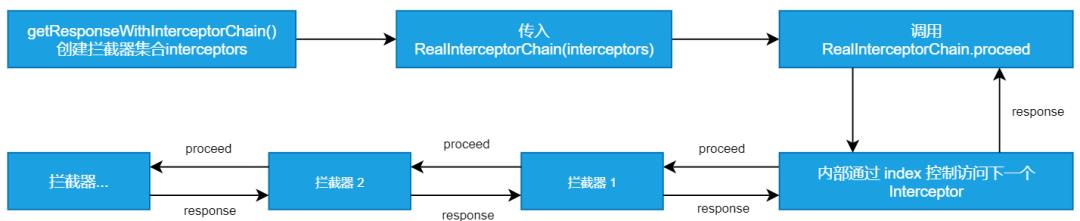
-
创建一系列拦截器,并将其放入一个拦截器 list 中 -
创建一个拦截器链 RealInterceptorChain,传入拦截器集合,RealInterceptorChain 内部包含当前拦截器访问的 index 用于控制访问 list 中第几个拦截器 -
首次传入 index=0,并执行拦截器链的 proceed 方法 -
执行当前拦截器 interceptor.intercept -
当前拦截器执行 RealInterceptorChain.proceed 返回 response -
index+1,并重复第2步 -
对response进行处理,返回给上一个拦截器
「OkHttp 内部的拦截器调用关系」
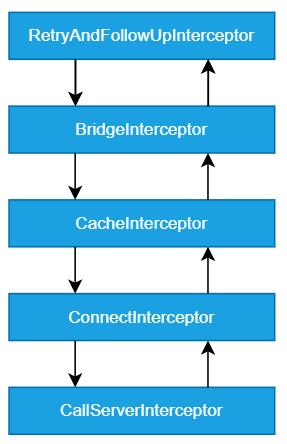
RetryAndFollowUpInterceptor(重试)
该拦截器用于处理 OkHttp 的重试逻辑
-
创建 StreamAllocation 对象,传递给下一个拦截器(后面会提到) -
内部有一个 While(true) 循环,用于触发重试逻辑 -
循环内调用 RealInterceptorChain.proceed(...) 进行网络请求(即调用下一个拦截器) 得到 response -
循环内有 followUpCount 变量用于控制最大重试次数, 「最大 20 次」 -
根据异常结果或响应码判断是否进行重新请求 -
将 response 返回给上一个拦截器
BridgeInterceptor(桥接)
负责将用户构建的一个 Request 请求转化为能够进行网络访问的请求,主要是请求头 Header 的构建
另外如果是 gzip 资源还会处理 gzip 的解压等
CacheInterceptor(缓存)
在说 CacheInterceptor 拦截器前需要先看下 OkHttp 的缓存的基本配置和使用:
private fun cacheRequest() {
val cacheFile = File(externalCacheDir, "okHttpCacheFile")
val client = OkHttpClient.Builder()
.cache(Cache(cacheFile, 1024 * 1024 * 10))//指定缓存目录 缓存最大容量(10M)
.readTimeout(5, TimeUnit.SECONDS)
.build()
val request = Request.Builder().url("https://www.xxx.com")
.cacheControl(
CacheControl.Builder()
//设置max-age为5分钟之后,这5分钟之内不管有没有网, 都读缓存
.maxAge(5, TimeUnit.MINUTES)
// max-stale设置为5天,意思是,网络未连接的情况下设置缓存时间为5天
.maxStale(5, TimeUnit.DAYS)
.build()
)
.get().build()
val call = client.newCall(request)
call.enqueue(object : Callback {
override fun onFailure(call: Call, e: IOException) {
GlobalScope.launch(Dispatchers.Main) {
responseText.text = "失败:${e.message}"
}
}
override fun onResponse(call: Call, response: Response) {
Log.d(TAG, "onResponse Thread: ${Thread.currentThread().name}")
val result = response.body()?.string()
GlobalScope.launch(Dispatchers.Main) {
responseText.text = result
printLog(response.cacheResponse()?.toString() ?: "cacheResponse 为空")
}
}
})
}
❝需要注意的是 Cache 的生效与否也取决于服务端是否支持
❞
「基本流程」
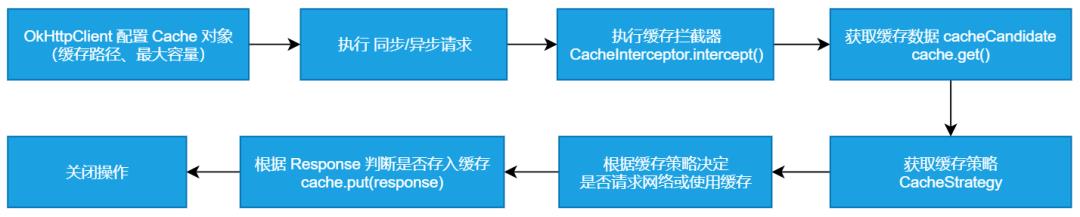
「需要注意以下几点」:
-
OkHttp 缓存采用 DiskLruCache 进行存储,即使用 LRU 算法 -
从源码看 OkHttp 并不支持 「非 Get」 请求的缓存
从 Cache.put 方法可以看到:
if (!requestMethod.equals("GET")) {
// Don't cache non-GET responses. We're technically allowed to cache
// HEAD requests and some POST requests, but the complexity of doing
// so is high and the benefit is low.
return null;
}
-
缓存的内容不光只缓存 response 的 body 的内容,会将 response 的 header 也会存起来
ConnectInterceptor(连接)
「基本流程」
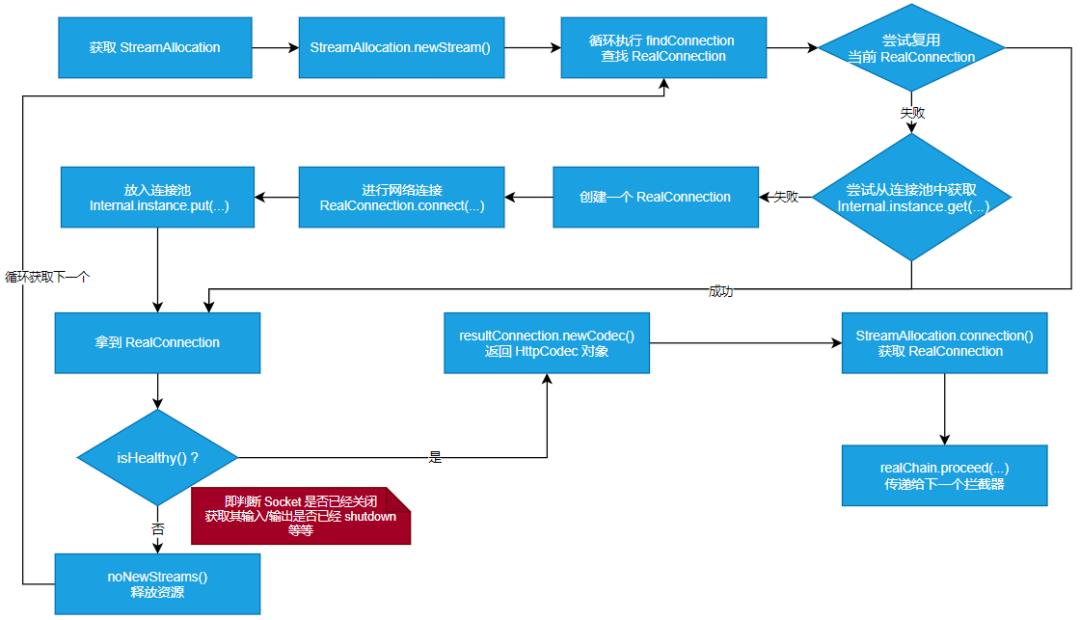
❝RealConnection:用于实际网络传输的对象
HttpCodec: 用于编码 request,解码 response
❞
「连接池(ConnectionPool)」
主要作用是在「一定的范围内复用连接(Connection)」,同时进行有效的「清理回收 Connection」
连接池结构图:
OkHttp 的每次请求都会产生一个 StreamAllocation 对象,会将其「弱引用」添加到 RealConnection.allocations 集合中( (RealConnection.findConnection 中负责添加),这个 allocations 集合主要是为了判断每一个 Connection 是否超过了最大连接数以及后面提到回收算法所使用
ConnectionPool 内部维护一个 ArrayDeque 「队列」 (connections) 用于存放 RealConnection,ConnectionPool 的 get 方法就负责遍历这个 connections 队列,从中取出「符合资格的 connection」 (即调用 RealConnection.isEligible 进行判断),获得成功后赋值给 streamAllocation
ConnectionPool 的 put 方法相对简单,通过调用 connections.add(connection) 将 connection 添加到连接池。特别的在 put 方法中会执行 cleanupRunnable,可以看下面的源码:
void put(RealConnection connection) {
assert (Thread.holdsLock(this));
if (!cleanupRunning) {
cleanupRunning = true;
executor.execute(cleanupRunnable );
}
connections.add(connection);
}
「ConnectionPool 的自动回收」
其中 cleanupRunnable 就负责对连接池中的 Connection 的进行自动回收。
特点如下:
-
内部有一个 「死循环」实现自动回收 -
利用了类似 Java GC 的 「标记清除算法」进行回收 -
监控每个 Connection 的 StreamAllocation 的数量,当其为 0 时进行回收
通过 OkHttp 连接池的回收,就可以「保持多个“健康”的 keep-alive 连接」
private final Runnable cleanupRunnable = new Runnable() {
@Override public void run() {
while (true) {
...
long waitNanos = cleanup(System.nanoTime());
...
try {
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
...
}
}
};
「OkHttp 是如何标记可回收连接的呢?」
在 ConnectionPool.cleanup() 方法中可以看到,会遍历每一个连接,如果 pruneAndGetAllocationCount 方法返回大于 0 则无需回收,否则之后的代码就会标记该 connection
long cleanup(long now) {
...
for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
// If the connection is in use, keep searching.
if (pruneAndGetAllocationCount(connection, now) > 0) {
inUseConnectionCount++;
continue;
}
}
...
}
再来看这个 pruneAndGetAllocationCount 方法,很关键一步就是判断 connection.allocations 中的「弱引用对象是否为空」,如果不为空则继续遍历,为空则会 remove,最后返回集合剩余大小
private int pruneAndGetAllocationCount(RealConnection connection, long now) {
List<Reference<StreamAllocation>> references = connection.allocations;
for (int i = 0; i < references.size(); ) {
Reference<StreamAllocation> reference = references.get(i);
if (reference.get() != null) {
i++;
continue;
}
...
references.remove(i);
...
}
...
return references.size();
}
CallServerInterceptor(请求)
该拦截器负责发起真正的网络请求以及接受网络响应
简单的总结下:
-
调用 httpCodec.writeRequestHeaders(request) 向 Socket 中写入 Header 信息 -
调用 request.body().writeTo(bufferedRequestBody) 向 Socket 中写入请求 Body 信息 -
调用 httpCodec.finishRequest() 完成请求体的写入 -
调用 httpCodec.readResponseHeaders(false) 读取网络响应的 Header 信息 -
调用 httpCodec.openResponseBody(response) 读取网络响应的 Body 信息 -
返回 response,给上一个拦截器
Demo 地址
https://github.com/changer0/FrameworkLearning
以上就是本节内容,欢迎大家关注
以上是关于OkHttp 基本使用&源码分析的主要内容,如果未能解决你的问题,请参考以下文章