mysql查询速度慢
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql查询速度慢相关的知识,希望对你有一定的参考价值。
sql如下,要8秒钟,哪位能改写或者是优化mysql的设置
select * from interrelated i,userbaseinfo u, resoucetongjiinfo r,restype re ,restyperecord res
where
re.typecode=03
and re.typeid= res.typeid
and i.id= res.OBJID
and u.userid=i.userid
and r.resourceid=i.id
order by i.time
limit 0,4
我们先来看第一个阶段,MySQL慢的诊断思路,一般我们会从三个方向来做:
第一个方向是MySQL内部的观测
第二个方向是外部资源的观测
第三个方向是外部需求的改造
1.1 MySQL 内部观测
我们来看MySQL内部的观测,常用的观测手段是这样的,从上往下看,第一部分是Processlist,看一下哪个SQL压力不太正常,第二步是explain,解释一下它的执行计划,第三步我们要做Profilling,如果这个SQL能再执行一次的话, 就做一个Profilling,然后高级的DBA会直接动用performance_schema ,MySQL 5.7 以后直接动用sys_schema,sys_schema是一个视图,里面有便捷的各类信息,帮助大家来诊断性能。再高级一点,我们会动用innodb_metrics进行一个对引擎的诊断。
除了这些手段以外,大家还提出了一些乱七八糟的手段,我就不列在这了,这些是常规的一个MySQL的内部的状态观测的思路。除了这些以外,MySQL还陆陆续续提供了一些暴露自己状态的方案,但是这些方案并没有在实践中形成套路,原因是学习成本比较高。
1.2 外部资源观测
外部资源观测这部分,我引用了一篇文章,这篇文章的二维码我贴在上面了。这篇文章是国外的一个神写的,标题是:60秒的快速巡检,我们来看一下它在60秒之内对服务器到底做了一个什么样的巡检。一共十条命令,这是前五条,我们一条一条来看。
1.uptime,uptime告诉我们这个机器活了多久,以及它的平均的负载是多少。
2.dmesg -T | tail,告诉我们系统日志里边有没有什么报错。
3.vmstat 1,告诉我们虚拟内存的状态,页的换进换出有没有问题,swap有没有使用。
4. mpstat -P ALL,告诉我们CPU压力在各个核上是不是均匀的。
5.pidstat 1,告诉我们各个进程的对资源的占用大概是什么样子。
我们来看一下后五条:
首先是iostat-xz 1,查看IO的问题,然后是free-m内存使用率,之后两个sar,按设备网卡设备的维度,看一下网络的消耗状态,以及总体看TCP的使用率和错误率是多少。最后一条命令top,看一下大概的进程和线程的问题。
这个就是对于外部资源的诊断,这十条命令揭示了应该去诊断哪些外部资源。
1.3 外部需求改造
第三个诊断思路是外部的需求改造,我在这里引用了一篇文档,这篇文档是MySQL的官方文档中的一章,这一章叫Examples of Common Queries,文档中介绍了常规的SQL怎么写, 给出了一些例子。文章的链接二维码在slide上。
我们来看一下它其中提到的一个例子。
它做的事情是从一个表里边去选取,这张表有三列,article、dealer、price,选取每个作者的最贵的商品列在结果集中,这是它的最原始的SQL,非常符合业务的写法,但是它是个关联子查询。
关联子查询成本是很贵的,所以上面的文档会教你快速地把它转成一个非关联子查询,大家可以看到中间的子查询和外边的查询之间是没有关联性的。
第三步,会教大家直接把子查询拿掉,然后转成这样一个SQL,这个就叫业务改造,前后三个SQL的成本都不一样,把关联子查询拆掉的成本,拆掉以后SQL会跑得非常好,但这个SQL已经不能良好表义了,只有在诊断到SQL成本比较高的情况下才建议大家使用这种方式。
为什么它能够把一个关联子查询拆掉呢?
这背后的原理是关系代数,所有的SQL都可以被表达成等价的关系代数式,关系代数式之间有等价关系,这个等价关系通过变换可以把关联子查询拆掉。
上面的这篇文档是一个大学的教材,它从头教了关于代数和SQL之间的关系。然后一步步推导怎么去简化这句SQL。
第一,MySQL本身提供了很多命令来观察MySQL自身的各类状态,大家从上往下检一般能检到SQL的问题或者服务器的问题。
第二,从服务器的角度,我们从巡检的脚本角度入手,服务器的资源就这几种,观测手法也就那么几种,我们把服务器的资源全部都观察一圈就可以了。
第三,如果实在搞不定,需求方一定要按照数据库容易接受的方式去写SQL,这个成本会下降的非常快,这个是常规的MySQL慢的诊断思路。
from interrelated i,
userbaseinfo u,
resoucetongjiinfo r,
restype re,
restyperecord res
where re.typeid = res.typeid
and i.id = res.OBJID
and u.userid = i.userid
and r.resourceid = i.id
and re.typecode = 03
order by i.time limit 0, 4
好像没啥好办法本回答被提问者采纳 参考技术B SELECT *本身就慢,
还有,如果数据量大,就不要一次性提取,那不合理。
凡是提取出来的数据,填充到缓存里,这样以后检索重复数据的时候,
就不需要再次让数据库引擎执行查询,而是直接从内存中提取。 参考技术C 建索引 参考技术D 哇。。。。5表查询
太霸道了
如何解决mysql 查询和更新速度慢
问题
我们有一个 SQL,用于找到没有主键 / 唯一键的表,但是在 MySQL 5.7 上运行特别慢,怎么办?
实验
我们搭建一个 MySQL 5.7 的环境,此处省略搭建步骤。
写个简单的脚本,制造一批带主键和不带主键的表:
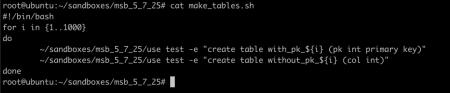
执行一下脚本:

现在执行以下 SQL 看看效果:
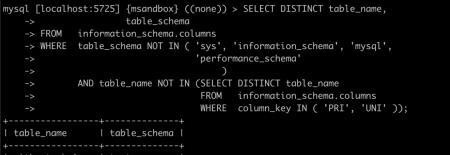
...
执行了 16.80s,感觉是非常慢了。
现在用一下 DBA 三板斧,看看执行计划:
感觉有点惨,由于 information_schema.columns 是元数据表,没有必要的统计信息。
那我们来 show warnings 看看 MySQL 改写后的 SQL:

我们格式化一下 SQL:
可以看到 MySQL 将
select from A where A.x not in (select x from B) //非关联子查询
转换成了
select from A where not exists (select 1 from B where B.x = a.x) //关联子查询
如果我们自己是 MySQL,在执行非关联子查询时,可以使用很简单的策略:
select from A where A.x not in (select x from B where ...) //非关联子查询:1. 扫描 B 表中的所有记录,找到满足条件的记录,存放在临时表 C 中,建好索引2. 扫描 A 表中的记录,与临时表 C 中的记录进行比对,直接在索引里比对,
而关联子查询就需要循环迭代:
select from A where not exists (select 1 from B where B.x = a.x and ...) //关联子查询扫描 A 表的每一条记录 rA: 扫描 B 表,找到其中的第一条满足 rA 条件的记录。
显然,关联子查询的扫描成本会高于非关联子查询。
我们希望 MySQL 能先"缓存"子查询的结果(缓存这一步叫物化,MATERIALIZATION),但MySQL 认为不缓存更快,我们就需要给予 MySQL 一定指导。
...

可以看到执行时间变成了 0.67s。
整理
我们诊断的关键点如下:
\\1. 对于 information_schema 中的元数据表,执行计划不能提供有效信息。
\\2. 通过查看 MySQL 改写后的 SQL,我们猜测了优化器发生了误判。
\\3. 我们增加了 hint,指导 MySQL 正确进行优化判断。
但目前我们的实验仅限于猜测,猜中了万事大吉,猜不中就无法做出好的诊断。
参考技术A 在做客户关系管理系统的时候遇到联表查询,速度特别慢,导致页面加载时间过长而出现错误。在上网查询后发现建立索引可以优化查询在没有建立索引的时候
select c.*,s.* from crm_cu_re c join crm_cu_info s on c.CUS_MAIN_ID=s.CUS_MAIN_ID)
查询结果
(526 row(s) returned)
Total Time : 00:01:15:723
仅仅526条记录!!!查询花了近66秒!!!!!!!
尝试建立索引
create index main on crm_custerm_info(CUS_MAIN_ID);
再次用相同的语句查询
select c.*,s.* fromcrm_cu_re c join crm_cu_info s on _MAIN_ID=s.CUS_MAIN_ID)
查询结果
(526 row(s) returned)
Total Time : 00:00:00:234
同样的526条记录查询花费时间不到1秒!!!效率提高无数倍。
相同的如果按cus_main_id跟新 crm_cu_info表
在没有建立索引前 执行 update crm_cu_info set C_NAME ="22" WHERE CUS_MAIN_ID ='xxxxxx'
(1 row(s) affected)
Execution Time : 00:00:00:546
Transfer Time : 00:00:00:000
Total Time : 00:00:00:546
建立索引后 create index main on crm_cu_info(CUS_MAIN_ID);
(0 row(s) affected)
Execution Time : 00:00:00:000
Transfer Time : 00:00:00:016
Total Time : 00:00:00:016
效率明显提高很多
由此可见索引是快速搜索的关键。MySQL索引的建立对于MySQL的高效运行是很重要的。下面几种常见的MySQL索引类型。
在数据库表中,对字段建立索引可以大大提高查询速度。假如我们创建了一个 mytable表:
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL ); 我们随机向里面插入了10000条记录,其中有一条:5555,admin。
在查找username="admin"的记录 SELECT * FROMmytable WHERE username='admin';时,如果在username上已经建立了索引,MySQL无须任何扫描,即准确可找到该记录。相反,MySQL会扫描所有记录,即要查询10000条记录。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索包含多个列。
MySQL索引类型包括:
(1)普通索引
这是最基本的索引,它没有任何限制。它有以下几种创建方式:
◆创建索引
CREATE INDEX indexName ONmytable(username(length)); 如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length,下同。
◆修改表结构
ALTER mytable ADD INDEX [indexName] ON(username(length)) ◆创建表的时候直接指定
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX [indexName] (username(length)) ); 删除索引的语法:
DROP INDEX [indexName] ON mytable;
(2)唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
◆创建索引
CREATE UNIQUE INDEX indexName ONmytable(username(length)) ◆修改表结构
ALTER mytable ADD UNIQUE [indexName] ON(username(length)) ◆创建表的时候直接指定
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, UNIQUE [indexName] (username(length)) );
(3)主键索引
它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引:
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, PRIMARY KEY(ID) ); 当然也可以用 ALTER 命令。记住:一个表只能有一个主键。
(4)组合索引
为了形象地对比单列索引和组合索引,为表添加多个字段:
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, city VARCHAR(50) NOT NULL, age INT NOT NULL ); 为了进一步榨取MySQL的效率,就要考虑建立组合索引。就是将 name, city, age建到一个索引里:
ALTER TABLE mytable ADD INDEX name_city_age(name(10),city,age); 建表时,usernname长度为 16,这里用 10。这是因为一般情况下名字的长度不会超过10,这样会加速索引查询速度,还会减少索引文件的大小,提高INSERT的更新速度。
如果分别在 usernname,city,age上建立单列索引,让该表有3个单列索引,查询时和上述的组合索引效率也会大不一样,远远低于我们的组合索引。虽然此时有了三个索引,但MySQL只能用到其中的那个它认为似乎是最有效率的单列索引。
建立这样的组合索引,其实是相当于分别建立了下面三组组合索引:
usernname,city,age usernname,city usernname 为什么没有 city,age这样的组合索引呢?这是因为MySQL组合索引“最左前缀”的结果。简单的理解就是只从最左面的开始组合。并不是只要包含这三列的查询都会用到该组合索引,下面的几个SQL就会用到这个组合索引:
SELECT * FROM mytable WHREEusername="admin" AND city="郑州" SELECT * FROM mytable WHREEusername="admin" 而下面几个则不会用到:
SELECT * FROM mytable WHREE age=20 ANDcity="郑州" SELECT * FROM mytableWHREE city="郑州"
(5)建立索引的时机
到这里我们已经学会了建立索引,那么我们需要在什么情况下建立索引呢?一般来说,在WHERE和JOIN中出现的列需要建立索引,但也不完全如此,因为MySQL只对<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE才会使用索引。例如:
SELECT t.Name FROM mytable t LEFT JOIN mytable m ON t.Name=m.username WHERE m.age=20 ANDm.city='郑州' 此时就需要对city和age建立索引,由于mytable表的userame也出现在了JOIN子句中,也有对它建立索引的必要。
刚才提到只有某些时候的LIKE才需建立索引。因为在以通配符%和_开头作查询时,MySQL不会使用索引。例如下句会使用索引:
SELECT * FROM mytable WHERE usernamelike'admin%' 而下句就不会使用:
SELECT * FROM mytable WHEREt Namelike'%admin' 因此,在使用LIKE时应注意以上的区别。
(6)索引的不足之处
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:
◆虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
◆建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
(7)使用索引的注意事项
使用索引时,有以下一些技巧和注意事项:
◆索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
◆使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
◆索引列排序
MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
◆like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%”不会使用索引而like “aaa%”可以使用索引。
◆不要在列上进行运算
select * from users whereYEAR(adddate)<2007; 将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成
select * from users whereadddate<‘2007-01-01’;
◆不使用NOT IN和<>操作本回答被提问者采纳
以上是关于mysql查询速度慢的主要内容,如果未能解决你的问题,请参考以下文章