Mysql 查询速度慢怎么办
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql 查询速度慢怎么办相关的知识,希望对你有一定的参考价值。
我有一张表,student,28万条数据,27个字段。
当不加where条件的时候,查询结果很快就出来了。当加了where就很慢,为什么呢?
问题
我们有一个 SQL,用于找到没有主键 / 唯一键的表,但是在 mysql 5.7 上运行特别慢,怎么办?
实验
我们搭建一个 MySQL 5.7 的环境,此处省略搭建步骤。
写个简单的脚本,制造一批带主键和不带主键的表:
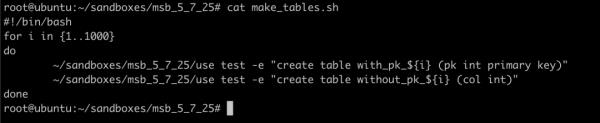
执行一下脚本:

现在执行以下 SQL 看看效果:
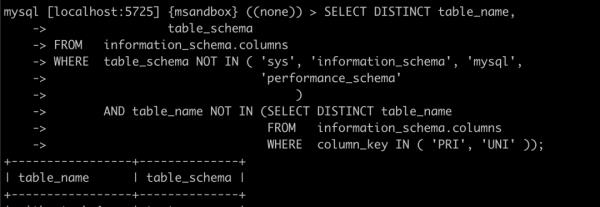
...
执行了 16.80s,感觉是非常慢了。
现在用一下 DBA 三板斧,看看执行计划:
感觉有点惨,由于 information_schema.columns 是元数据表,没有必要的统计信息。
那我们来 show warnings 看看 MySQL 改写后的 SQL:

我们格式化一下 SQL:
可以看到 MySQL 将
select from A where A.x not in (select x from B) //非关联子查询
转换成了
select from A where not exists (select 1 from B where B.x = a.x) //关联子查询
如果我们自己是 MySQL,在执行非关联子查询时,可以使用很简单的策略:
select from A where A.x not in (select x from B where ...) //非关联子查询:1. 扫描 B 表中的所有记录,找到满足条件的记录,存放在临时表 C 中,建好索引2. 扫描 A 表中的记录,与临时表 C 中的记录进行比对,直接在索引里比对,
而关联子查询就需要循环迭代:
select from A where not exists (select 1 from B where B.x = a.x and ...) //关联子查询扫描 A 表的每一条记录 rA: 扫描 B 表,找到其中的第一条满足 rA 条件的记录。
显然,关联子查询的扫描成本会高于非关联子查询。
我们希望 MySQL 能先"缓存"子查询的结果(缓存这一步叫物化,MATERIALIZATION),但MySQL 认为不缓存更快,我们就需要给予 MySQL 一定指导。
...

可以看到执行时间变成了 0.67s。
整理
我们诊断的关键点如下:
\\1. 对于 information_schema 中的元数据表,执行计划不能提供有效信息。
\\2. 通过查看 MySQL 改写后的 SQL,我们猜测了优化器发生了误判。
\\3. 我们增加了 hint,指导 MySQL 正确进行优化判断。
但目前我们的实验仅限于猜测,猜中了万事大吉,猜不中就无法做出好的诊断。
参考技术A 不加WHERE时就=打开门进到数据库里,如果加上WHERE就=打开门,在进到数据库里,在慢慢的找数据里面的东西,这就是区别 参考技术B 回答亲:1.升级硬件2.根据查询条件,建立索引,优化索引、优化访问方式,限制结果集的数据量。3.扩大服务器的内存4.增加服务器CPU个数
参考技术C 28万条数据量不是很大,字段稍微有点多,如果不加WHERE 条件的话,数据库判定是查询所有数据库,而加了WHERE 条件时,数据库判定要去详细的查找某个数据,所以速度自然会慢,建立索引可以解决您的问题;CREATE INDEX 索引名 ON 表名 (WHERE 条件用到的列名,如有多个就以逗号分隔);
这次在去WHERE 的时候就会快很多本回答被提问者采纳 参考技术D 你先找下sql优化的办法,建立索引是一种办法。
一个办法是分表。比如把每个年级的学生使用一个表来装,就是把student分成student1,student2...
在查询前先判断是哪个年级的再使用相应的表。
以后再不行就分服务器,每个服务器装一个年级的表。
以后再大,一个表就要分服务器来装了,但你应该用不到这种技术。可以参考google的bigtable
以上是关于Mysql 查询速度慢怎么办的主要内容,如果未能解决你的问题,请参考以下文章