lua数据结构之table的内部实现
Posted 努力脱发成为大牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lua数据结构之table的内部实现相关的知识,希望对你有一定的参考价值。
一、table结构
1、Table结构体
首先了解一下table结构的组成结构,table是存放在GCObject里的。结构如下:
typedef struct Table
CommonHeader;
lu_byte flags; /* 1<<p means tagmethod(p) is not present */
lu_byte lsizenode; /* 以2的lsizenode次方作为哈希表长度 */
struct Table *metatable /* 元表 */;
TValue *array; /* 数组 */
Node *node; /* 哈希表 */
Node *lastfree; /* 指向最后一个为闲置的链表空间 */
GCObject *gclist;
int sizearray; /* 数组的大小 */
Table;
从table的结构可以看出,table在设计的时候以两种结构来存放数据。一般情况对于整数key,会用array来存放,而其它数据类型key会存放在哈希表上。并且用lsizenode作为链表的长度,sizearray作为数组长度。
2、Node结构体
typedef union TKey
struct
TValuefields;
struct Node *next; /* 指向下一个冲突node */
nk;
TValue tvk;
TKey;
typedef struct Node
TValue i_val;
TKey i_key;
Node;Node结构很好理解,就是一个键值对的结构。主要是TKey结构,这里用了union,所以TKey的大小是nk的大小。并且实际上TValue与TValuefields是同一个结构,因此tvk与nk的TValuefields都是代表键值。而且这里有一个链表结构struct Node *next,用于指向下一个有冲突的node。
二、创建table
table的创建通过lua_newtable函数实现。通过定位具体实现是在luaH_new这个函数进行table的创建。代码如下:
Table *luaH_new (lua_State *L, int narray, int nhash)
Table *t = luaM_new(L, Table);/* new一个table对象 */
luaC_link(L, obj2gco(t), LUA_TTABLE);
t->metatable = NULL;
t->flags = cast_byte(~0);
/* temporary values (kept only if some malloc fails) */
t->array = NULL;
t->sizearray = 0;
t->lsizenode = 0;
t->node = cast(Node *, dummynode);
setarrayvector(L, t, narray);
setnodevector(L, t, nhash);
return t;
主要是对table进行初始化,其中setarrayvector是对数组大小进行设置,setnodevector是对hash表大小进行设置,具体代码如下:
/*
设置数组的容量
*/
static void setarrayvector (lua_State *L, Table *t, int size)
int i;
//重新设置数组的大小
luaM_reallocvector(L, t->array, t->sizearray, size, TValue);
//循环把数组元素初始化为nil类型
for (i=t->sizearray; i<size; i++)
setnilvalue(&t->array[i]);
t->sizearray = size;
/*
设置哈希表的容量
*/
static void setnodevector (lua_State *L, Table *t, int size)
int lsize;
if (size == 0) /* no elements to hash part? */
t->node = cast(Node *, dummynode); /* use common `dummynode' */
lsize = 0;
else
int i;
//实际大小转化为指数形式
lsize = ceillog2(size);
if (lsize > MAXBITS)
luaG_runerror(L, "table overflow");
//这里实际大小以2的lsize次方来算的
size = twoto(lsize);
//创建指定大小的空间
t->node = luaM_newvector(L, size, Node);
//循环初始化每个node
for (i=0; i<size; i++)
Node *n = gnode(t, i);
gnext(n) = NULL;
setnilvalue(gkey(n));
setnilvalue(gval(n));
t->lsizenode = cast_byte(lsize);
t->lastfree = gnode(t, size); /* 由于是新创建的,所以指向最后一个node,即指向下标为size的node */
三、插入键值
键值的插入流程:

如图所示,已经大致可以清楚新键产生的过程。接下来会分析比较重要的几个模块。
1、table空间的动态扩展
无论是array还是hash表,都是以2的倍数进行扩展的。比较有区别的是,array数组sizearray记录的是真实大小,而hash表的lsizenode记录的是2的倍数。当hash表空间满的时候,才会重新分配array和hash表。比较重要的两个函数是rehash和resize,前一个是重新算出要分配的空间,后一个是创建空间。先分析下rehash函数:
//加入key,重新分配hash与array的空间
static void rehash (lua_State *L, Table *t, const TValue *ek)
int nasize, na;//nasize前期累计整数key个数,后期做为数组空间大小,na表示数组不为nil的个数
int nums[MAXBITS+1]; /* 累计各个区间整数key不为nil的个数,包括hash, 例如nums[i]表示累计在[2^(i-1),2^i]区间内的整数key个数*/
int i;
int totaluse;//记录所有已存在的键,包括hash和array,即table里的成员个数
for (i=0; i<=MAXBITS; i++) nums[i] = 0; /* 初始化所有计数区间*/
nasize = numusearray(t, nums); /* 以区间统计数组里不为nil的个数,并获得总数*/
totaluse = nasize; /* all those keys are integer keys */
totaluse += numusehash(t, nums, &nasize); /* 统计hash表里已有的键,以及整数键的个数已经区间分布*/
//如果新key是整数类型的情况
nasize += countint(ek, nums);
//累计新key
totaluse++;
/* 重新计算数组空间 */
na = computesizes(nums, &nasize);
/* 重新创建内存空间, nasize为新数组大小,totaluse - na表示所有键的个数减去新数组的个数,即为新hash表需要存放的个数 */
resize(L, t, nasize, totaluse - na);
/*
重新分配数组和hash表空间
*/
static void resize (lua_State *L, Table *t, int nasize, int nhsize)
int i;
int oldasize = t->sizearray;
int oldhsize = t->lsizenode;
Node *nold = t->node; /* 保存当前的hash表,用于后面创建新hash表时,可以重新对各个node赋值*/
if (nasize > oldasize) /* 是否需要扩展数组 */
setarrayvector(L, t, nasize);
/* 重新分配hash空间*/
setnodevector(L, t, nhsize);
if (nasize < oldasize) /* 小于之前大小,即有部分整数key放到了hash里 */
t->sizearray = nasize;
/* 超出部分存放到hash表里*/
for (i=nasize; i<oldasize; i++)
if (!ttisnil(&t->array[i]))
setobjt2t(L, luaH_setnum(L, t, i+1), &t->array[i]);
/* 重新分配数组空间,去掉后面溢出部分*/
luaM_reallocvector(L, t->array, oldasize, nasize, TValue);
/* 从后到前遍历,把老hash表的值搬到新表中*/
for (i = twoto(oldhsize) - 1; i >= 0; i--)
Node *old = nold+i;
if (!ttisnil(gval(old)))
setobjt2t(L, luaH_set(L, t, key2tval(old)), gval(old));
//释放老hash表空间
if (nold != dummynode)
luaM_freearray(L, nold, twoto(oldhsize), Node); /* free old array */
2、键的创建规则
2、1整数类型
一般情况下,整数类型的键都是放在数组里的,但是有2种特殊情况会被分配到hash表里。
对于存放在数组有一个规则,每插入一个整数key时,都要判断包含当前key的区间[1, 2^n]里,是否满足table里所有整数类型key的数量大于2^(n - 1),如果不成立则需要把这个key放在hash表里。这样设计,可以减少空间上的浪费,并可以进行空间的动态扩展。例如:
a[0] = 1, a[1] = 1, a[5]= 1
结果分析:数组大小4, hash大小1,a[5]本来是在8这个区间里的,但是有用个数3 < 8 / 2,所以a[5]放在了hash表里。
a[0] = 1, a[1] = 1, a[5] = 1, a[6] = 1,
结果分析:数组大小4,hash大小2,有用个数4 < 8 / 2,所以a[5],a[6]放在hash表里。
a[0] = 1, a[1] = 1, a[5] = 1, a[6] = 1, a[7] = 1
结果分析:数组大小8,hash大小0, 有用个数5 > 8 / 2。
数组大小的规定由以下函数实现:
static int computesizes (int nums[], int *narray)
int i;
int twotoi; /* 2^i */
int a = 0; /* 统计到2^i位置不为空的数量 */
int na = 0; /* 记录重新调整后的不为空的数量 */
int n = 0; /* 记录重新调整后的数组大小 */
for (i = 0, twotoi = 1; twotoi/2 < *narray; i++, twotoi *= 2)
if (nums[i] > 0)
a += nums[i];
if (a > twotoi/2) /* 判断当前的数量是否满足大于2^(i - 1) */
n = twotoi; /* optimal size (till now) */
na = a; /* all elements smaller than n will go to array part */
if (a == *narray) break; /* all elements already counted */
*narray = n;
lua_assert(*narray/2 <= na && na <= *narray);
return na;
通过前面的分析,可以清楚的知道这个函数的意图,根据统计出来的所有整数键重新划分数据大小。其中参数nums[]是一个数组,每个nums[i]都记录了在数组中[2^i, 2^(i + 1)]的区间内不为空的数量。参数narray是个指针,获得重新调整后的数组大小。
另外还有一种被分配到hash表里的情况,当hash表有空间并且当前key值越界的时候,会先放在hash表里,直到hash表满的时候,才会把hash表里的所有整数键按上面的方法进行操作。
2、2其他类型
对于非整数类型的键会被全部分配到hash表里。前面我们提到,table用一个Node数组来作为hash表的容器,利用hash算法把键转化为某个数组下标,来进行存放。hash表在设计的时候有一点比较巧妙的地方,我们知道hash算出来的位置有可能是会冲突的,所以如果当前插入的key发生冲突的时候,会把当前插入的key放到lastfree中,并把当前的node链接到冲突链中。这里有一种情况,如果插入的newkey的位置不是因为冲突而被占,而是其他oldkey因为冲突暂时存放的话,会把这个位置让会给原本属于这个位置的newkey,并把oldkey放到lastfree中。可能不好理解,还是来模拟解释下:

位置被占的情况:

接下来再来看下主要代码就比较容易理解了:
static TValue *newkey (lua_State *L, Table *t, const TValue *key)
Node *mp = mainposition(t, key);
//两种情况,主键有值的情况很好理解。另一种,是t->node没有分配空间的情况,即第一次插入的情况。
if (!ttisnil(gval(mp)) || mp == dummynode)
Node *othern;
Node *n = getfreepos(t); /* 获得lastfree指向的空间 */
if (n == NULL) /* 没有空间 */
rehash(L, t, key); /* 重整hash和array的大小 */
return luaH_set(L, t, key); /* re-insert key into grown table */
lua_assert(n != dummynode);
othern = mainposition(t, key2tval(mp));
//这里想了很久终于明白为什么有othern != mp这种情况,表示mp这个node原本不属于这个位置的,只是占用而已。
//因为mainposition取出来的node,有可能本来就不是存放在这个位置的。而是之前与某一个位置冲突,而放在lastfree里的。
//所以othern != mp这种情况,表示的是原来不应存放在这个位置的node移到lastfree,而这个位置被新node占据。
if (othern != mp) /* is colliding node out of its main position? */
/* yes; move colliding node into free position */
//这里是遍历找到mp的前一个冲突节点
while (gnext(othern) != mp) othern = gnext(othern); /* find previous */
//把othern的下一个节点(即mp的位置)指向lastfree,mp的值赋值给lastfree
gnext(othern) = n; /* redo the chain with `n' in place of `mp' */
*n = *mp; /* copy colliding node into free pos. (mp->next also goes) */
gnext(mp) = NULL; /* now `mp' is free */
setnilvalue(gval(mp));
//表示mp的位置原本就是属于这个位置的。也就是说与这个位置的哈希值是碰撞的。
else /* colliding node is in its own main position */
/* new node will go into free position */
//这里新node(即n)是链接在冲突链的第二个位置
gnext(n) = gnext(mp); /* chain new position */
gnext(mp) = n;
mp = n;
gkey(mp)->value = key->value; gkey(mp)->tt = key->tt;
luaC_barriert(L, t, key);
lua_assert(ttisnil(gval(mp)));
return gval(mp);
3、键值的赋值
键值对赋值的过程,就是通过获取栈顶的前两个位置作为key和value,如果这个key在table里是不存在的则创建新的key,并返回key对应的TValue指针,再对指针其进行赋值。具体实现如下:
/*
对table插入key与值
*/
void luaV_settable (lua_State *L, const TValue *t, TValue *key, StkId val)
int loop;
TValue temp;
//这里循环100次,是因为要遍历所有的元表有无对应的key
for (loop = 0; loop < MAXTAGLOOP; loop++)
const TValue *tm;
if (ttistable(t)) /* `t' is a table? */
Table *h = hvalue(t);
//判断这个key是否存在,如果没有创建一个
TValue *oldval = luaH_set(L, h, key); /* do a primitive set */
//如果是已有的node会通过第一个条件,如果是新的node,判断是否有元表
//也就是说,不会执行里面的判断只有一种可能,就是有_newindex这个元表
if (!ttisnil(oldval) || /* result is no nil? */
(tm = fasttm(L, h->metatable, TM_NEWINDEX)) == NULL) /* or no TM? */
//把val赋值给oldval
setobj2t(L, oldval, val);
h->flags = 0;
luaC_barriert(L, h, val);
return;
/* else will try the tag method */
//如果元表为nil,报错。
else if (ttisnil(tm = luaT_gettmbyobj(L, t, TM_NEWINDEX)))
luaG_typeerror(L, t, "index");
//如果是function,则执行这个function
if (ttisfunction(tm))
callTM(L, tm, t, key, val);
return;
/* else repeat with `tm' */
setobj(L, &temp, tm); /* avoid pointing inside table (may rehash) */
t = &temp;
luaG_runerror(L, "loop in settable");
四、for循环的分析
1、for循环的入栈操作
在lua里,table.foreach(key, value)可以遍历整一个table,因此来对foreach具体分析一下。foreach函数的作用,是从table里循环查找下一个key和value,压入栈顶,并与lua层定义的function一起进行处理的一个过程。具体代码如下:
static int foreach (lua_State *L)
luaL_checktype(L, 1, LUA_TTABLE);
luaL_checktype(L, 2, LUA_TFUNCTION);
lua_pushnil(L); /* 这里把nil作为初始key,会用作存储第一个key*/
//每遍历一遍,一定是当前key在栈顶。
while (lua_next(L, 1))
lua_pushvalue(L, 2); /* function */
lua_pushvalue(L, -3); /* key */
lua_pushvalue(L, -3); /* value */
lua_call(L, 2, 1); /* 执行funciton */
if (!lua_isnil(L, -1))
return 1;
lua_pop(L, 2); /* 这里弹出函数调用的返回值,和value,即栈顶为当前key */
return 0;
栈的活动模型流程如图:
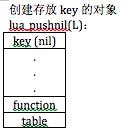 ->
-> ->
-> ->
-> ->
-> ->
-> ->
->
2、键值的查找
键值的查找必定是先从数组开始找,数组找完了之后才按hash表找。并且都是以下标从小到大的顺序遍历,每次找到之后,都会把key存放起来,并把对应的value压栈。下一次循环时在算出当前key的位置下标,通过位置下标往后移一单位来获得下一个key。流程如图:

具体的代码如下:
int luaH_next (lua_State *L, Table *t, StkId key)
//返回key对应的下标,如果是在hash表里的,是返回下标加上sizearray;
如果是第一次查找则返回-1
int i = findindex(L, t, key);
//i++,即会从下一个key值开始遍历,因为有可能是空的,所以需要遍历到不为空为止。
for (i++; i < t->sizearray; i++) /* try first array part */
if (!ttisnil(&t->array[i])) /* a non-nil value? */
setnvalue(key, cast_num(i+1));
//在栈里面,value赋值给栈顶的空位置,即L->top = &t->array[i]
//在函数外面会执行L->top++的。
setobj2s(L, key+1, &t->array[i]);
return 1;
//i - t->sizearray,求出hash下标的真正位置
for (i -= t->sizearray; i < sizenode(t); i++) /* then hash part */
if (!ttisnil(gval(gnode(t, i)))) /* a non-nil value? */
setobj2s(L, key, key2tval(gnode(t, i)));
setobj2s(L, key+1, gval(gnode(t, i)));
return 1;
return 0; /* no more elements */
以上是关于lua数据结构之table的内部实现的主要内容,如果未能解决你的问题,请参考以下文章