深入Lua:Table的实现
Posted Unity3D游戏开发精华教程干货
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入Lua:Table的实现相关的知识,希望对你有一定的参考价值。
Table的结构
Lua和其他语言最不同的地方在于,它只有一个叫表的数据结构:这是一个数组和哈希表的混合体。神奇的地方在于只通过表,就可以实现模块,元表,环境,甚至面向对象等功能。这让我们很好奇它内部的结构到底是怎么样的。
它的结构定义在lobject.h中,是这样的:
typedef struct Table {// 这是一个宏,为GCObject共用部分,展开后就是:// GCObject *next; lu_byte tt; lu_byte marked// 所有的GC对象都以这个开始CommonHeader;// 和快速判断元方法有关,这里可以先略过lu_byte flags;// 哈希部分的长度对数:1 << lsizenode 才能得到实际的sizelu_byte lsizenode;// 数组部分的长度unsigned int sizearray;// 数组部分,为TValue组成的数组TValue *array;// 哈希部分,为Node组成的数组,见下面Node的说明Node *node;// lastfree指明空闲槽位Node *lastfree;// 元表:每个Table对象都可以有独立的元表,当然默认为NULLstruct Table *metatable;// GC相关的链表,这里先略过GCObject *gclist;} Table;
现在我们只需要关注Table是由数组(array)和哈希表(node)两部分组成即可,哈希表是一个由Node组成的数组,Node包括Key和Value,Node结构如下:
typedef struct Node {TValue i_val; // value为TValueTKey i_key; // key为TKey,看下面} Node;// TKey其实是一个联合,它可能是TValue,也可能是TValue的内容再加一个next字段。typedef union TKey {// 这个结构和TValue的差别只是多了一个next,TValuefields是一个宏,见下面struct {// 这部分和TValue的内存是一样的TValuefields;// 为了实现冲突结点的链接,当两个结点的key冲突后,用next把结点链接起来int next; /* for chaining (offset for next node) */} nk;TValue tvk;} TKey;// TValue包括的域
Table的哈希表也是链接法,但它并不会动态创建结点,它把所有结点都放在Node数组中,然后用TKey中的next字段,把冲突的结点连接起来。这样的哈希表就非常的紧凑,只要一块连续的内存即可。请看下图:
黄色的结点表示非nil的值,白色的结点表示nil值(也就是空闲结点)。
0,6,7号结点的关系是:这三个结点的Key计算出来的槽位都落在0号,但因为0号被优先占据,所以另外两个只能另外找空地,就找到6, 7号位置,然后为了表现他们的关系,用next表示这个结点到下一个结点的偏移。
新建Table
Table的实现代码在ltable.h|c,其中luaH_new函数创建一个空表:
Table *luaH_new (lua_State *L) {// 创建Table的GC对象GCObject *o = luaC_newobj(L, LUA_TTABLE, sizeof(Table));Table *t = gco2t(o);// 元表相关t->metatable = NULL;t->flags = cast_byte(~0);// 数组部分初始化空t->array = NULL;t->sizearray = 0;// 哈希部分初始化空setnodevector(L, t, 0);return t;}
Table取值
取值的函数有luaH_getint, luaH_getshortstr, luaH_getstr, luaH_get,其中luaH_getint会涉及到数组部分和哈希部分,代码如下:
const TValue *luaH_getint (Table *t, lua_Integer key) {// key在[1, sizearray)时在数组部分// key<=0或key>=sizearray则在哈希部分if (l_castS2U(key) - 1 < t->sizearray)return &t->array[key - 1];else {// 1. 这里是哈希部分,整型直接key & nodesize得到数组索引,取出结点地址返回Node *n = hashint(t, key);for (;;) {// 2. 比较该结点的key相等(同为整型且值相同),是则返回值if (ttisinteger(gkey(n)) && ivalue(gkey(n)) == key)return gval(n); /* that's it */else {// 3. 如果不是,通过上面所说的next取链接的下一个结点// 4. 因为是相对偏移,所以只要n+=nx即可得到连接的结点指针,再回到2int nx = gnext(n);if (nx == 0) break;n += nx;}}// 5. 如果找不到,就还回nil对象return luaO_nilobject;}}
luaH_getstr他luaH_get最终可能调用到getgeneric这个函数,这个函数也只是查找哈希部分,代码如下:
static const TValue *getgeneric (Table *t, const TValue *key) {// mainposition函数通过key找到“主位置”的结点,// 意思是用key算出Node数组的索引,从那个索引取出结点,// 相当于上图中编号为6或7中结点的key取出的主位置结点是0号Node *n = mainposition(t, key);// 1. 初始的n就是主位置结点for (;;) { /* check whether 'key' is somewhere in the chain */// 2. 判断n的key是否和参数key相等,相等那就是这个结点,luaV_rawequalobj根据不同类型// 做不同处理if (luaV_rawequalobj(gkey(n), key))return gval(n); /* that's it */else {// 3. 否则取链接的下一个结点的偏移int nx = gnext(n);// 4. 无偏移,说明没有下一个结点,直接返回nil对象if (nx == 0)return luaO_nilobject; /* not found */// 5. 取下一个结点给n,循环到第2n += nx;}}}
Table设值
设值的逻辑比取值要复杂得多,因为涉及到空间不够要重建表的内容。对外接口主要luaH_set和luaH_setint,之所以分出一个int函数当然是因为要处理数组部分,先来看这个函数:
void luaH_setint (lua_State *L, Table *t, lua_Integer key, TValue *value) {// 1. 先取值const TValue *p = luaH_getint(t, key);TValue *cell;// 2. 不为nil对象即是取到,保存在cell变量。if (p != luaO_nilobject)cell = cast(TValue *, p);else {// 3. 初始化一个TValue的key,然后调用luaH_newkey新建一个key,并返key关联的value到cellTValue k;setivalue(&k, key);cell = luaH_newkey(L, t, &k);}// 最后将新value赋值给cellsetobj2t(L, cell, value);}
luaH_newkey函数的主要逻辑:
这个函数的主要功能将一个key插入哈希表,并返回key关联的value指针。
首先通过key计算出主位置,如果主位置为空结点那最简单,将key设进该结点,然后返回结点的值指针。如果不是空结点就要分情况,看3和4两种情况
如果该结点就是主位置结点,那么要另找一个空闲位置,把Key放进去,和主结点链接起来,然后返回新结点的值指针。
如果该结点不是主位置结点,把这个结点移到空闲位置去;然后我进驻这个位置,并返回结点的值指针。
这样说好像也难以理解,没关系,用几张图来说明:
情况2的:
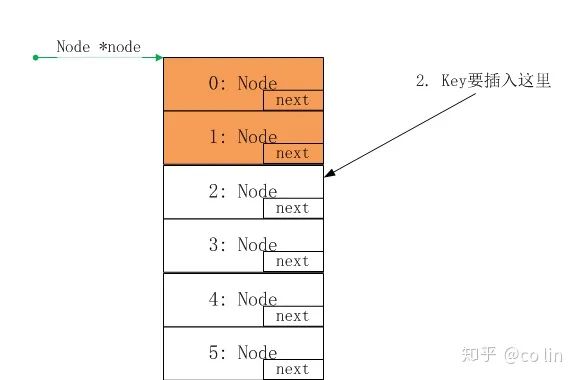
情况3的,虚线是本来要插入的位置,实线是最终插入的位置,黄线是结点链接。
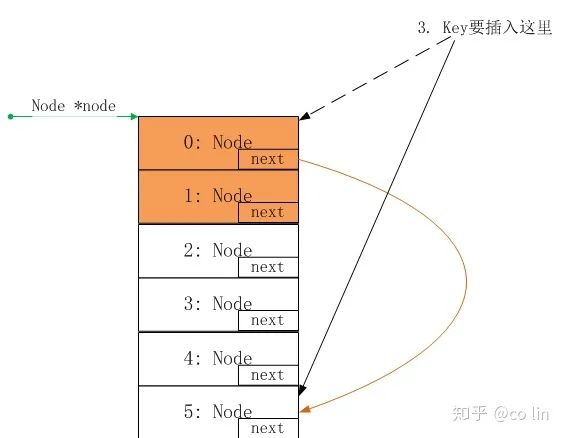
情况4的,Key要插入7号位置,7号结点移到6号,然后key进入7号位置。
现在来看函数代码应该就好懂了,函数代码经过精简:
TValue *luaH_newkey (lua_State *L, Table *t, const TValue *key) {Node *mp;TValue aux;// 计算主位置mp = mainposition(t, key);// 主位置被占,或者哈希部分为空if (!ttisnil(gval(mp)) || isdummy(t)) {Node *othern;// 找空闲位置,这里还涉及到没空闲位置会重建哈希表的操作,下一节说Node *f = getfreepos(t);if (f == NULL) {rehash(L, t, key);return luaH_set(L, t, key);}// 通过主位置这个结点的key,计算出本来的主位置结点othern = mainposition(t, gkey(mp));if (othern != mp) {// 这种就对应上面说的情况4的处理,把结点移到空闲位置去// 移动之前,要先把链接结点的偏移调整一下while (othern + gnext(othern) != mp) /* find previous */othern += gnext(othern);gnext(othern) = cast_int(f - othern); /* rechain to point to 'f' */// 把冲突结点移到空闲位置*f = *mp; /* copy colliding node into free pos. (mp->next also goes) */// 如果冲突结点也有链接结点,也要调整过来if (gnext(mp) != 0) {gnext(f) += cast_int(mp - f); /* correct 'next' */gnext(mp) = 0; /* now 'mp' is free */}setnilvalue(gval(mp));}else {// 这是对应上面说的情况3/* new node will go into free position */if (gnext(mp) != 0)gnext(f) = cast_int((mp + gnext(mp)) - f); /* chain new position */else lua_assert(gnext(f) == 0);gnext(mp) = cast_int(f - mp);mp = f;}}// 到这里可以将key赋值给结点,并返回结点的值指针setnodekey(L, &mp->i_key, key);luaC_barrierback(L, t, key);lua_assert(tti
snil(gval(mp)));
return gval(mp);
}
从上面看整个逻辑最复杂的部分就是结点链接的调整。
getfreepos函数用于找空闲结点,Table结构中有一个lastfree变量,它刚开始指向结点数组的最后,getfreepos使lastfree不断向前移,直到找到空闲的结点:
static Node *getfreepos (Table *t) {if (!isdummy(t)) {while (t->lastfree > t->node) {t->lastfree--;if (ttisnil(gkey(t->lastfree)))return t->lastfree;}}return NULL; /* could not find a free place */}
如果lastfree移到数组最前面,说明找不到空闲结点,会返回空,这时开始重建Table。说明找不到空闲结点,其实是有可能存在空闲结点的,比如lastfree后面的结点如果被设置为nil,lastfree就没法知道了,因为它总是往前移,不管的后面结点。不管如何,只要移到数组最前面,就开始重建表。
Table重建
rehash函数要确定有多少整型key,并决定这些整型key有多少值放到数组部分去,然后剩下的值放到哈希部分,最后有可能会缩减空间,也可能会扩大空间。
我们把它分拆出来一步步看,先来看一些辅助函数:
统计数组部分有多少个非nil值:
na = numusearray(t, nums);na是非nil值(有效值)的数量,nums是一个数组,里面统计着各个范围内的有效值数量,类似下图这样:
nums会决定最后数组的大小
统计哈希表部分的值数量,以及整数key的一些信息:
totaluse = na;totaluse += numusehash(t, nums, &na);
totaluse是有效值的总数量,nums是上面那个范围统计数组,na是整型key的值数量;最终得到几个有用的信息:
totaluse 有效值的总数量
na 整型key的有效值数量
nums 整型key的分布范围
有了这些信息,接下来就要计算出数组的尺寸:
asize = computesizes(nums, &na);asize是计算后的数组大小,na返回多少个整型key的值进入数组部分。
asize总是为2的幂,而computesizes的目的是使数组的有效值尽可能密集,能超过数组大小的一半。
得到数组的大小和哈希表的大小后,就可以重建Table:
luaH_resize(L, t, asize, totaluse - na);上面所描述的步骤就是rehash做的事情,luaH_resize我尝试从源代码来解释:
void luaH_resize (lua_State *L, Table *t, unsigned int nasize,unsigned int nhsize) {unsigned int i;int j;AuxsetnodeT asn;unsigned int oldasize = t->sizearray;int oldhsize = allocsizenode(t);Node *nold = t->node; // 先把老的Node数组保存起来// 如果数组尺寸变大,调用setarrayvector扩充if (nasize > oldasize)setarrayvector(L, t, nasize);// 创建新的Node数组,我把代码简化了,lastfree会在这里重新指向数组尾// node数组的大小为nhsize向上取整为2的幂setnodevector(L, t, nhsize);// 如果数组尺寸变小if (nasize < oldasize) { /* array part must shrink? */t->sizearray = nasize;// 将超出那部分移到哈希表去for (i=nasize; i<oldasize; i++) {if (!ttisnil(&t->array[i]))luaH_setint(L, t, i + 1, &t->array[i]);}// 重设数组大小luaM_reallocvector(L, t->array, oldasize, nasize, TValue);}// 将上面保存的Node数组的值,设回新的Node数组for (j = oldhsize - 1; j >= 0; j--) {Node *old = nold + j;if (!ttisnil(gval(old))) {setobjt2t(L, luaH_set(L, t, gkey(old)), gval(old));}}// 最后释放老的Node数组if (oldhsize > 0) /* not the dummy node? */luaM_freearray(L, nold, cast(size_t, oldhsize)); /* free old hash */}
重建表涉及到内容的搬迁,特别是哈希部分,如果有一张大表经常导致rehash,那么效率应该是很受影响的。
Table遍历
Table的遍历是由luaH_next函数实现:
int luaH_next (lua_State *L, Table *t, StkId key);它根据key先遍历数组,再遍历哈希表,比如数组部分key一直加1遍历,哈希部分是根据Key找到Node数组的位置往后遍历。
这会带来一个什么问题呢?如果Table的空洞很多,它的遍历效率一定会非常慢的,可以用下面的例子验证:
local function make_table()local t = {}local size = 10000000for i = 1, size dot[tostring(i)] = iendfor i = 1, size-1 dot[tostring(i)] = nilendreturn tendlocal function test_pairs(t)local tm = os.clock()for i = 1, 10000 dofor k, v in pairs(t) doendendtm = os.clock() - tmprint("time=", tm)endtest_pairs(make_table())
上例的表先设置1千万个Key,然后删除成只有1个Key,此时遍历这个只有1个Key的表,会花费将近24S的时间,这给我们一个经验,一定要防止很多空洞的表出现。当然如果rehash之后会变正常,但rehash也会有很大的性能消耗的。
哈希表的主位置结点
上面代码多次看到mainposition这个函数,它的作用是根据Key计算出Node数组的槽位,并返回该槽位的结点指针来。因为Key可以是除了nil外的任何类型,所以Key的哈希值要分情况计算:
static Node *mainposition (const Table *t, const TValue *key) {switch (ttype(key)) {case LUA_TNUMINT:return hashint(t, ivalue(key));case LUA_TNUMFLT:return hashmod(t, l_hashfloat(fltvalue(key)));case LUA_TSHRSTR:return hashstr(t, tsvalue(key));case LUA_TLNGSTR:return hashpow2(t, luaS_hashlongstr(tsvalue(key)));case LUA_TBOOLEAN:return hashboolean(t, bvalue(key));case LUA_TLIGHTUSERDATA:return hashpointer(t, pvalue(key));case LUA_TLCF:return hashpointer(t, fvalue(key));default:lua_assert(!ttisdeadkey(key));return hashpointer(t, gcvalue(key));}}
LUA_TNUMINT为整数,
i % (size -1)即得到槽位,因为size是2的幂,所以减1才能减少冲突的概率。LUA_TNUMFLT为浮点数,它不是强制转成整数,因为整数未必可以表示浮点数。它是用浮点数中的尾数放大到INT_MAX范围内的整数,再加上其指数,最后得到一个无符数的整数。
LUA_TSHRSTR为短字符串,因为短字符串的哈希值早已计算出,所以直接用它的哈希值得到槽位即可。
LUA_TLNGSTR为长字符串,长串用惰性求哈希值的方式,第1次要计算一次哈希值,计算完保存到TString结构中,以后直接用即可。其哈希值的计算方法不是遍历所有字节,这样如果遇到巨大的字符串可能有效率问题,它是从串中平均采出最多32个字节来计算的,这样最多就遍历32次。
LUA_TBOOLEAN为布尔值,由于C的布尔值其实就是整数,所以和整数处理方式一样。
Lua代码中处处有技巧,比如上面的长字符串求哈希值,建议直接阅读一下luaS_hashlongstr这个函数。
关于Table的思考
我们一步步地分析了Table的实现,确实也惊讶于其结构的紧凑。但是,从我个人观点看,Lua的Table并非是一个好的设计,其复杂性的根源在于混合了哈希表和数组,看似想用最少的数据结构做最多的事情,其实内部实现和上层应用都变复杂了,违返了单一职责原则。
假如Lua把Table中的数组部分分离出来,写成一个单独类型的对象,这样Table的逻辑会很清晰,也很易于优化。
往期精选
声明:发布此文是出于传递更多知识以供交流学习之目的。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与我们联系,我们将及时更正、删除,谢谢。
原文:https://zhuanlan.zhihu.com/p/97830462
以上是关于深入Lua:Table的实现的主要内容,如果未能解决你的问题,请参考以下文章