自然语言处理大模型大语言模型BLOOM推理工具测试
Posted BQW_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理大模型大语言模型BLOOM推理工具测试相关的知识,希望对你有一定的参考价值。
相关博客
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】WebGPT:基于人类反馈的浏览器辅助问答
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】大模型的涌现能力
BLOOM的原理见【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
BLOOM是由HuggingFace推出的大模型,其参数量达到176B(GPT-3是175B)。目前超过100B参数量且能够支持中文的开源大模型只有BLOOM和GLM-130B。由于HuggingFace是著名开源工具Transformers的开发公司,很多推理工具都会支持Transformers中的模型。
LLM(大语言模型)推理的两个问题:(1) 单张显卡无法容纳整个模型;(2) 推理速度太慢。本文初步整理了一些推理大模型的工具和代码,并简单测试了推理速度。下面是本文测试的一些背景:
-
目前是2023年2月
-
使用7B模型bloom-7b1-mt
-
4张3090(但在实际推理中仅使用2张3090)
-
依赖包的版本
transformers==4.26.0 tensor-parallel==1.0.24 deepspeed==0.7.7 bminf==2.0.1
零、辅助函数
# utils.py
import numpy as np
from time import perf_counter
def measure_latency(model, tokenizer, payload, device, generation_args=):
input_ids = tokenizer(payload, return_tensors="pt").input_ids.to(device)
latencies = []
# 预热
for _ in range(2):
_ = model.generate(input_ids, **generation_args)
# 统计时间
for _ in range(10):
start_time = perf_counter()
_ = model.generate(input_ids, **generation_args)
latency = perf_counter() - start_time
latencies.append(latency)
# 计算统计量
time_avg_ms = 1000 * np.mean(latencies) # 延时均值
time_std_ms = 1000 * np.std(latencies) # 延时方差
time_p95_ms = 1000 * np.percentile(latencies,95) # 延时的95分位数
return f"P95延时 (ms) - time_p95_ms; 平均延时 (ms) - time_avg_ms:.2f +\\- time_std_ms:.2f;"
def infer(model, tokenizer, payload, device):
input_ids = tokenizer(payload, return_tensors="pt").input_ids.to(device)
logits = model.generate(input_ids, num_beams=1, max_length=512)
out = tokenizer.decode(logits[0].tolist())
return out
一、层并行
BLOOM是Huggingface开发的,所以在transformers库中提供了支持。具体来说,在使用from_pretrained加载模型时,指定参数devce_map即可。其通过将模型的不同层放置在不同的显卡上,从而将单个大模型分拆至多张卡上(流水线并行也会将层分拆,然后采用流水线的方式训练模型)。下面是调用的示例代码:
# layer_parallel_test.py
import os
import transformers
from utils import measure_latency, infer
from transformers import AutoTokenizer, AutoModelForCausalLM
transformers.logging.set_verbosity_error()
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"
def run():
model_name = "bigscience/bloomz-7b1-mt"
payload = """
参考下面的文章,然后用与文章相同的语言回答问题: 段落:当细菌突破免疫系统的防御而开始增生时,疾病会由结核菌感染进展到症状明显的结核病。在原发型结核病 (占 1-5% 的比例),这种现象会在感染刚开始的时候很快的发生。然而>多数人感染模式为潜伏结核感染,通常没有明显症状。在5-10%潜伏结合感染的案例中,这些休眠的细菌经常会在感染后数年的时间制造出活动的结核。 问题:What is the next stage after TB infection?
"""
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
model = model.eval()
out = infer(model, tokenizer, payload, model.device)
print("="*70+" 模型输入输出 "+"="*70)
print(f"模型输入: payload")
print(f"模型输出: out")
print("\\n\\n"+"="*70+" 模型延时测试 "+"="*70)
print(measure_latency(model, tokenizer, payload, model.device))
print("\\n\\n"+"="*70+" 显存占用 "+"="*70)
print(os.system("nvidia-smi"))
if __name__ == "__main__":
run()
pass
模型的时延结果:
P95延时 (ms) - 118.402308691293; 平均延时 (ms) - 117.72 +- 0.58;
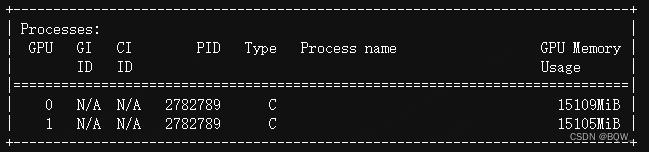
显存占用:

二、张量并行
张量并行是将矩阵乘法进行分块,从而将大矩阵拆分为更小的矩阵,这样就能把不同的矩阵放置在不同的显卡上。(具体原理会在后续的文章中介绍)
这里使用开源工具包tensor_parallel来实现。
# tensor_parallel_test.py
import os
import transformers
import tensor_parallel as tp
from utils import measure_latency, infer
from transformers import AutoTokenizer, AutoModelForCausalLM
transformers.logging.set_verbosity_error()
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"
def run():
model_name = "bigscience/bloomz-7b1-mt"
payload = """
参考下面的文章,然后用与文章相同的语言回答问题: 段落:当细菌突破免疫系统的防御而开始增生时,疾病会由结核菌感染进展到症状明显的结核病。在原发型结核病 (占 1-5% 的比例),这种现象会在感染刚开始的时候很快的发生。然而>多数人感染模式为潜伏结核感染,通常没有明显症状。在5-10%潜伏结合感染的案例中,这些休眠的细菌经常会在感染后数年的时间制造出活动的结核。 问题:What is the next stage after TB infection?
"""
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, low_cpu_mem_usage=True)
model = tp.tensor_parallel(model, ["cuda:0", "cuda:1"])
model = model.eval()
out = infer(model, tokenizer, payload, model.device)
print("="*70+" 模型输入输出 "+"="*70)
print(f"模型输入: payload")
print(f"模型输出: out")
print("\\n\\n"+"="*70+" 模型延时测试 "+"="*70)
print(measure_latency(model, tokenizer, payload, model.device))
print("\\n\\n"+"="*70+" 显存占用 "+"="*70)
print(os.system("nvidia-smi"))
if __name__ == "__main__":
run()
pass
模型的时延结果:
P95延时 (ms) - 91.34029923006892; 平均延时 (ms) - 90.66 +- 0.46;
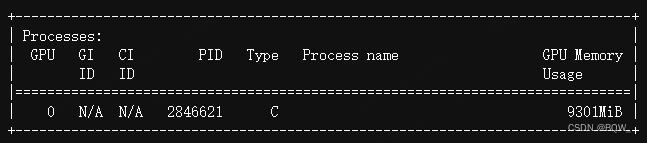
显存占用:
三、模型量化
原理见【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍。
量化是一种常见的模型压缩技术,核心思想是将模型参数从高精度转换为低精度。在BLOOM上使用8-bit量化只需要在调用from_pretrained时,设置参数load_in_8bit=True, device_map="auto"。
(注:bloom在实现量化时,会按照是否超越阈值来分拆矩阵,然后对低于阈值的模型参数进行量化,这会拖慢推理速度)
# int8_test.py
import os
import transformers
from utils import measure_latency, infer
from transformers import AutoTokenizer, AutoModelForCausalLM
transformers.logging.set_verbosity_error()
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"
def run():
model_name = "bigscience/bloomz-7b1-mt"
payload = """
参考下面的文章,然后用与文章相同的语言回答问题: 段落:当细菌突破免疫系统的防御而开始增生时,疾病会由结核菌感染进展到症状明显的结核病。在原发型结核病 (占 1-5% 的比例),这种现象会在感染刚开始的时候很快的发生。然而>多数人感染模式为潜伏结核感染,通常没有明显症状。在5-10%潜伏结合感染的案例中,这些休眠的细菌经常会在感染后数年的时间制造出活动的结核。 问题:What is the next stage after TB infection?
"""
max_memory_mapping = 0: "24GB", 1: "0GB"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, load_in_8bit=True, device_map="auto", max_memory=max_memory_mapping)
model = model.eval()
out = infer(model, tokenizer, payload, model.device)
print("="*70+" 模型输入输出 "+"="*70)
print(f"模型输入: payload")
print(f"模型输出: out")
print("\\n\\n"+"="*70+" 模型延时测试 "+"="*70)
print(measure_latency(model, tokenizer, payload, model.device))
print("\\n\\n"+"="*70+" 显存占用 "+"="*70)
print(os.system("nvidia-smi"))
if __name__ == "__main__":
run()
pass
模型的时延结果:
P95延时 (ms) - 147.89210632443428; 平均延时 (ms) - 143.30 +- 3.02;
显存占用:
四、DeepSpeed-Inference
DeepSpeed-Inference是分布式训练工具DeepSpeed中用户模型推理的功能。
# deepspeed_test.py
import os
import torch
import deepspeed
import transformers
from utils import measure_latency, infer
from transformers import AutoTokenizer, AutoModelForCausalLM
transformers.logging.set_verbosity_error()
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"
def run():
model_name = "bigscience/bloomz-7b1-mt"
payload = """
参考下面的文章,然后用与文章相同的语言回答问题: 段落:当细菌突破免疫系统的防御而开始增生时,疾病会由结核菌感染进展到症状明显的结核病。在原发型结核病 (占 1-5% 的比例),这种现象会在感染刚开始的时候很快的发生。然而>多数人感染模式为潜伏结核感染,通常没有明显症状。在5-10%潜伏结合感染的案例中,这些休眠的细菌经常会在感染后数年的时间制造出活动的结核。 问题:What is the next stage after TB infection?
"""
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16)
model = deepspeed.init_inference(
model=model, # Transformers模型
mp_size=2, # 模型并行数量
dtype=torch.float16, # 权重类型(fp16)
replace_method="auto", # 让DS自动替换层
replace_with_kernel_inject=True, # 使用kernel injector替换
)
out = infer(model, tokenizer, payload, model.module.device)
print("="*70+" 模型输入输出 "+"="*70)
print(f"模型输入: payload")
print(f"模型输出: out")
print("\\n\\n"+"="*70+" 模型延时测试 "+"="*70)
print(measure_latency(model, tokenizer, payload, model.module.device))
print("\\n\\n"+"="*70+" 显存占用 "+"="*70)
print(os.system("nvidia-smi"))
if __name__ == "__main__":
run()
pass
这里不能使用python来自动脚本,需要使用下面的命令:
deepspeed --num_gpus 2 --master_port 60000 deepspeed_test.py
模型的时延结果:
P95延时 (ms) - 31.88958093523979; 平均延时 (ms) - 30.75 +- 0.64;
显存占用:
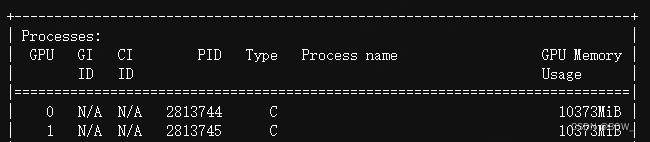
五、BMInf
BMInf能够在单张显卡下加载完整的模型,但是推理速度非常慢(应该是利用了Offload技术)。
import os
import bminf
import transformers
from utils import measure_latency, infer
from transformers import AutoTokenizer, AutoModelForCausalLM
transformers.logging.set_verbosity_error()
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"
def run():
model_name = "bigscience/bloomz-7b1-mt"
payload = """
参考下面的文章,然后用与文章相同的语言回答问题: 段落:当细菌突破免疫系统的防御而开始增生时,疾病会由结核菌感染进展到症状明显的结核病。在原发型结核病 (占 1-5% 的比例),这种现象会在感染刚开始的时候很快的发生。然而>多数人感染模式为潜伏结核感染,通常没有明显症状。在5-10%潜伏结合感染的案例中,这些休眠的细菌经常会在感染后数年的时间制造出活动的结核。 问题:What is the next stage after TB infection?
"""
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, low_cpu_mem_usage=True)
model = model.eval()
model = bminf.wrapper(model, quantization=False, memory_limit=8 << 30)
out = infer(model, tokenizer, payload, model.device)
print("="*70+" 模型输入输出 "+"="*70)
print(f"模型输入: payload")
print(f"模型输出: out")
print("\\n\\n"+"="*70+" 模型延时测试 "+"="*70)
print(measure_latency(model, tokenizer, payload, model.device))
print("\\n\\n"+"="*70+" 显存占用 "+"="*70)
print(os.system("nvidia-smi"))
if __name__ == "__main__":
run()
pass
模型的时延结果:
P95延时 (ms) - 719.2403690889478; 平均延时 (ms) - 719.05 +- 0.14;
显存占用:
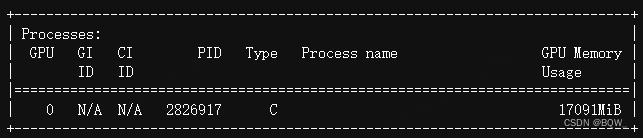
六、结论
- DeepSpeed-Inference的速度是最快的;
- 张量并行比自带的层并行快一些;
- 8 bit量化虽然速度慢一些,但是能够实现单卡推理;
- BMInf虽然速度最慢,但是其可能在不损失模型精度的情况下,单卡推理;
说明
- 本文并不是这些推理工具的最佳实践,仅是罗列和展示这些工具如何使用;
- 这些工具从不同的角度来优化模型推理,对于希望进一步了解具体如何实现的人来说,可以阅读源代码;
以上是关于自然语言处理大模型大语言模型BLOOM推理工具测试的主要内容,如果未能解决你的问题,请参考以下文章