轻松玩转开源大语言模型bloom
Posted XINFINFZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了轻松玩转开源大语言模型bloom相关的知识,希望对你有一定的参考价值。
前言
chatgpt已经成为了当下热门,github首页的trending排行榜上天天都有它的相关项目,但背后隐藏的却是openai公司提供的api收费服务。作为一名开源爱好者,我非常不喜欢知识付费或者服务收费的理念,所以便有决心写下此系列,让一般大众们可以不付费的玩转当下比较新的开源大语言模型bloom及其问答系列模型bloomz。那么废话不多说,本篇将介绍如何在个人电脑上简单的使用bloom模型生成句子。
模型介绍

bloom是一个开源的支持最多59种语言和176B参数的大语言模型。它是在Megatron-LM GPT2的基础上修改训练出来的,主要使用了解码器唯一结构,对词嵌入层的归一化,使用GeLU激活函数的线性偏差注意力位置编码等技术。它的训练集包含了45种自然语言和12种编程语言,1.5TB的预处理文本转化为了350B的唯一token。bigscience在hugging face上发布的bloom模型包含多个参数多个版本,本文中出于让大家都能动手实践的考虑,选择最小号的bloom-1b1版本,其他模型请自行尝试。
环境准备
python版本最好是3.8及以上,因为项目都会逐渐对老版本python停止支持,可能找不到现成的wheel包从而需要自己编译,而windows下需要使用VS,那是个相当痛苦的过程。
推荐pip原生虚拟环境安装,不推荐conda虚拟环境。本文的安装方法都是基于pip,如果你不懂pip虚拟环境请运行以下命令(linux如果有python2,请运行pip3):
pip install virtualenv -i https://mirror.baidu.com/pypi/simple #安装虚拟环境包
python -m venv bloom #在当前目录创建名叫bloom的虚拟环境
创建完后如何启动:
先一路cd到根目录,即脚本文件夹所在目录,然后cd进去activate。
cd Scripts
activate
比如我这里是名叫gpt-ch的环境:
输完后这样就表示启动成功了,所有的命令都会在隔离环境里运行,安装的包也都会在gpt-ch/Lib/site-packages里:
安装pip包
如果只用cpu进行推理,只需要安装以下包:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
pip install transformers -i https://mirror.baidu.com/pypi/simple
如果你想用英伟达gpu进行推理,请自行安装gpu版的torch。这里提供wheel下载链接:
记得torch和torchvision的版本是需要对应的,然后这里默认你已经安装配置好了cuda路径,如果没有请看我之前的文章或者去网上查。
以我这里的cu117版本为例。

运行以下命令:
pip install torch-1.13.0+cu117-cp39-cp39-win_amd64.whl #自行更改文件名
pip install torchvision-0.14.0+cu117-cp39-cp39-win_amd64.whl #自行更改文件名
pip install transformers -i https://mirror.baidu.com/pypi/simple
pip install accelerate -i https://mirror.baidu.com/pypi/simple
模型下载
首先请编写以下代码保存运行:
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigscience/bloom-1b1" #1b1,可改名成你想要的更大的模型
tokenizer = AutoTokenizer.from_pretrained(checkpoint) #下载模型的tokenizer
model = AutoModelForCausalLM.from_pretrained(checkpoint) #下载模型
网速足够快的情况下等一会就下载好了,但通常情况下我们得ctrl+c打断代码运行,手动下载模型存放到对应位置,即.cache\\huggingface\\hub\\models–bigscience–bloom-1b1下。
如果你是windows,那么这个cache文件夹默认会创建在C:\\Users\\Administrator\\下。
如果你是linux,你使用了root权限,会在root文件夹下创建,如果是普通用户权限,则会在对应名称的普通用户目录下,此外该文件夹在linux中默认为隐藏文件夹,需打开权限查看。
下载模型地址
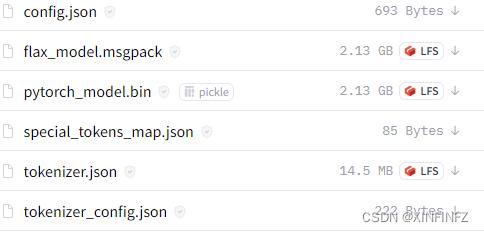
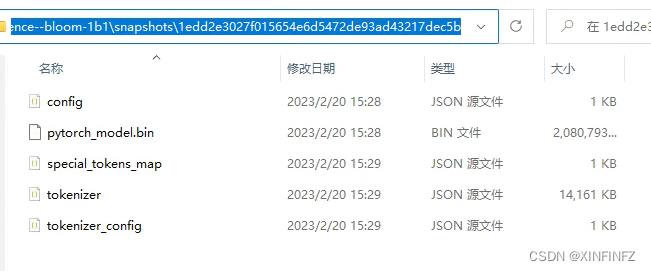
把如上图所示链接中的五个文件(不包含这个flax_model.msgpack)下载下来放进自己的本地目录下的snapshots\\一串数字(如下图所示)即可,其他文件夹都不用管。
生成第一段话
万事准备就绪后,就可以开始愉快的游玩了,运行以下代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
a1 = time.time()
checkpoint = "bigscience/bloom-1b1"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("奋进在不可逆转的复兴进程上", return_tensors="pt") #prompt
outputs = model.generate(inputs,min_length=150,max_new_tokens=200,do_sample=True)
print(tokenizer.decode(outputs[0])) #使用tokenizer对生成结果进行解码
a2 = time.time()
print(f'time cost is a2 - a1 s')
time模块用来计时,我的是十二代i7,花了40s生成。
这里有一些生成时的参数需要讲解一下:
min_length是指最小生成长度,等于你输入的提示词+最小生成的token数,也就是input_length+min_new_tokens。
max_new_tokens规定了最大生成的token数目,这里的token你可以理解为一个词,不好翻译所以一律token,忽略你输入的prompt。与之相关的是max_length参数,其实max_length就是max_new_tokens+你输入的prompt长度。
do_sample=True表示进行抽样,否则会使用贪心解码策略。
生成以下结果:

效果如何?是觉得不如人意还是效果逼真呢?
下期我们将尝试各种解码策略生成不一样的结果并进行比较,看到这里的朋友们可以点个关注,我们下期再见。
谷歌开源BERT不费吹灰之力轻松训练自然语言模型
AI研习社出品
编译:micah 酱番梨 忆臻
目前自然语言处理模型是人工智能的前沿科技,他们是很多AI系统与用户交互的接口。NLP 发展的主要阻碍来自于模型对于高质量标记数据的依赖。由于语言是一个任何事物都可以应用的普遍交流的机制,这也意味着很难找到一个特定领域的注解数据去训练模型。针对这个挑战, NLP 模型 决定先使用大量的没有标签的数据训练语言原理。非常有名的预训练模型包括 Word2Vec,Glove 或者FasText。然而 预训练模型有自己的挑战,对于大量数据的上下文关系的表达常常失败。最近来自GOOGLE AI 语言团队的研究者们开放了 BERT项目的源代码,一个为预训练语言表达而生的库,并且其训练结果达到了很不错的效果。
Bidirectional Encoder Representations from Transformers (BERT) 起源于Google内部的一篇研究,提出了一种在大量上下文相关的语言的预训练模型中获取数据的不同方法。这些表达方式可以被用于特定领域的NLP 任务,类似于问答式语句,情感分析。开源项目的发布,既是论文中提出的 TensorFlow 技术的实施, 也是一系列的预训练模型。
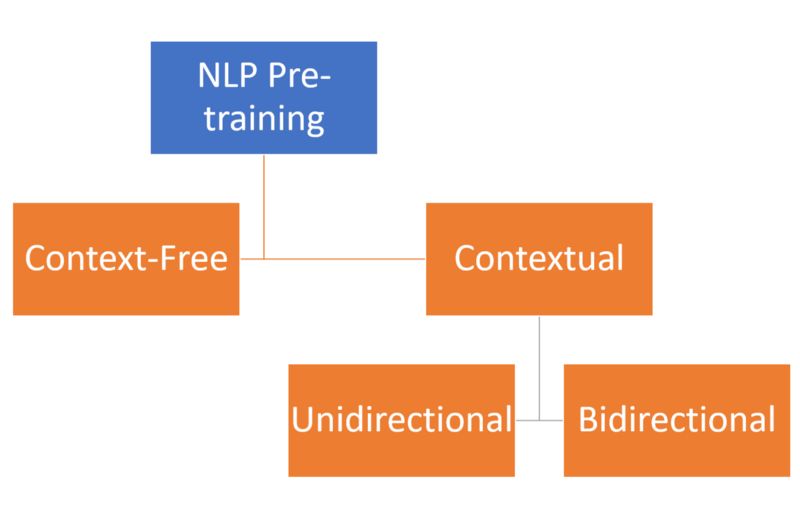
1. 上下文检索与双向性
现在 你可能会想知道BERT与其他预训练模型不同的地方。理论上,NLP 预训练技术可以是上下文无关的,也可以是上下文互相检索的。上下文无关的模型,像 word2vec 或者 GloVegenerate 是以单个词汇嵌入词汇表的表达方式。例如,“足球”这个单词在以下语句中有相同的语义“我去了足球比赛”,“我遇到了一些来自皇家马德里的足球球员”。
上下文检索的模型并非由单个词汇生成表达语句,而是根据这句话不同方向上的其他其他单词来生成表达句。在我们的例子中,上下文检索式的模型中“足球”的含义根据短语“我去..”或者“我遇到了...”而生成 而不是根据“比赛”“皇家马德里的球员”。本质上,预训练模型可以是上下文无关的也可以是上下文检索式的,更深入的,可以是单向性的也可以是双向性的。
BERT 通过根据前后单词的意思创建上下文检索表达语义, 延伸了之前的预训练模型方法,丰富了语言模型。在NLP模型中达成双向的,上下文检索的语义表达并不像听起来那么容易。双向性最大的困难在于,在训练模型中 不能简单的将单词的前一个和后一个单词作为上下文,可能会让单词间接的在多层模型中寻找 “自己 “。Google BERT 使用了非常聪明的架构来应对这一挑战。
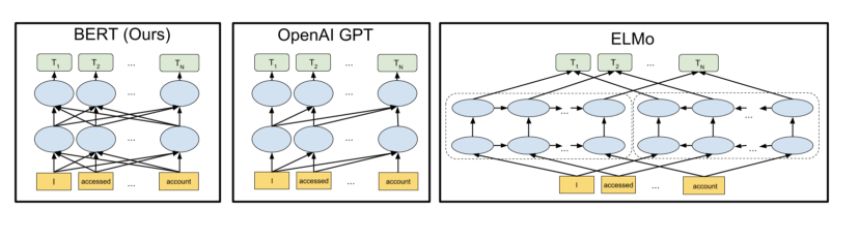
2. 架构
BERT 的模型架构基于多层双向转换解码 ,与 tensor2tensor library 中的原理十分相似。BERT 有着与其他预训练模型 OpenAI GPT 或者 ELMo十分相似的网络架构。但是在转换器之间有着如下图所示的双向连接。
BERT 最大的贡献在于使用了两个 奇异的非监督预测任务来解决之前提到的挑战。使得让单词在文章上下文里“认出自己”变为可能。BERT解决这个挑战使用了多种不同的预训练任务:屏蔽和下一句预测。第一个预处理模型遮蔽约15%的输入单词,在深度双向转换解码中运行整个语句,并且只预测被遮蔽的单词,例如:

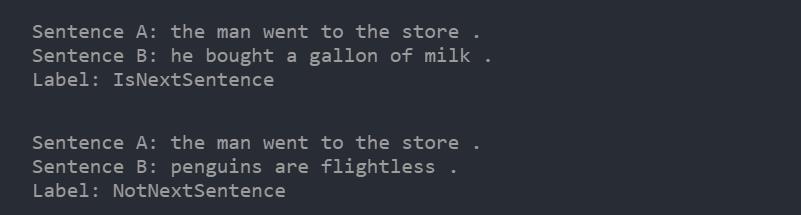
第二个预处理任务通过语料库中随机生成的简单语句,学习语句之间的联系。
给出两个语句A 和B, B是A之后的语句吗?还是B 只是语料库中随机抽取的一句话?
这两个预处理任务的结合使得 BERT在几乎所有的NLP任务中 得到了更加丰富的,双向的语义表达。
使用BERT有两个阶段:预训练 和 微调
预训练:相当的昂贵(在 4~ 16 个 云 TPUs 上跑4天),但是对于每一个语言,只用跑一次。为了减缓任务的严峻性, Google 发布了好几款可以用于NLP 场景的预训练模型。
微调:很便宜,所有在纸上可以完成的工作都可以在一个云端TPU的一小时之内完成,或者使用GPU 的话需要几个小时的时间。从相同的预训练模型开始。
3. BERT 实践
Google以BERT 作为其他优秀的NLP 系统的基准,取得了引人瞩目的成就。 最重要的是,BERT 取得的所有的结果不需要根据任务改变神经网络的结构。
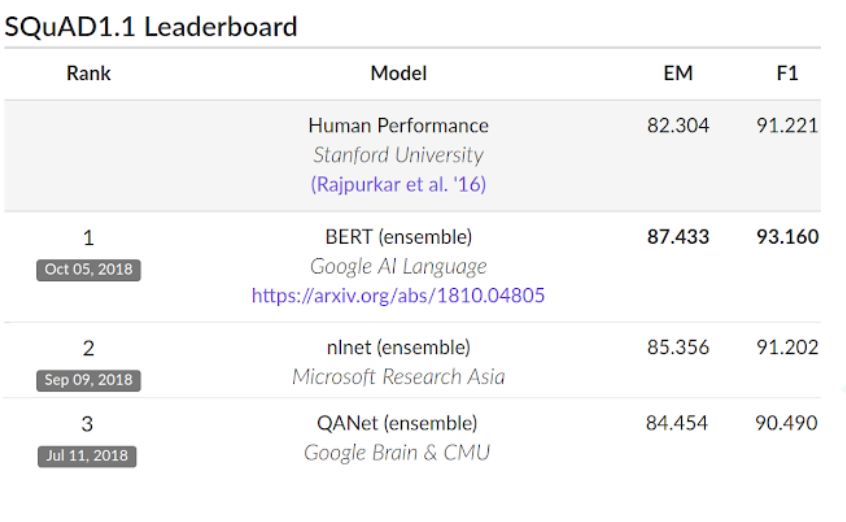
在 SQuAD v1.1 ,BERT 取得了93.2% 的F1 分数(精准度计算的分数),超越了之前模型的91.6%和人工翻译的91.2%。
BERT 也提高了 GLUE benchmark 的基准的 7.6%, 一个9种的自然语言理解(NLU)集合任务。
语言模型的迁移学习近期带来了大量的经验性提升表明了大量的,无监督的预训练模型是众多语言理解系统中的重要组成部分。BERT 表明了在NLP预处理模型中获取双向的,上下文语言的表达是可能的。目前实施BERT的TensorFlow 允许开发者将这个前沿技术应用于他们的NLP 场景的同时维护可管理的计算成本。
原文链接:
https://towardsdatascience.com/google-open-sources-bert-to-train-natural-language-models-without-breaking-the-bank-813ef38018fc
推荐阅读:
以上是关于轻松玩转开源大语言模型bloom的主要内容,如果未能解决你的问题,请参考以下文章