HAWQ实践——搭建示例模型(MySQLHAWQ)
Posted wzy0623
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HAWQ实践——搭建示例模型(MySQLHAWQ)相关的知识,希望对你有一定的参考价值。
一、业务场景
本系列实验将应用HAWQ数据库,为一个销售订单系统建立数据仓库。本篇说明示例的业务场景、数据仓库架构、实验环境、源和目标库的建立过程、测试数据和日期维度的生成。后面陆续进行初始数据装载、定期数据装载、调度ETL工作流自动执行、维度表技术、事实表技术、OLAP和数据可视化等实验。目的是演示以HAWQ代替传统数据仓库的具体实现全过程。
1. 操作型数据源
示例的操作型系统是一个销售订单系统,初始时只有产品、客户、销售订单三个表,实体关系图如图1所示。
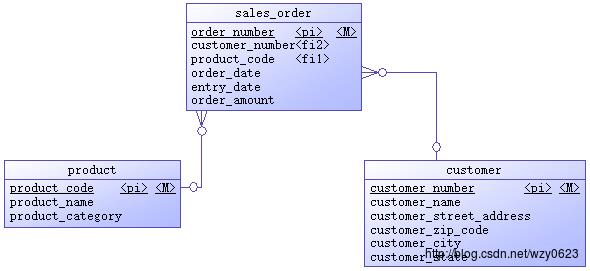
图1
这个场景中的表及其属性都很简单。产品表和客户表属于基本信息表,分别存储产品和客户的信息。产品只有产品编号、产品名称、产品分类三个属性,产品编号是主键,唯一标识一个产品。客户有六个属性,除客户编号和客户名称外,还包含省、市、街道、邮编四个客户所在地区属性。客户编号是主键,唯一标识一个客户。在实际应用中,基本信息表通常由其它后台系统维护。销售订单表有六个属性,订单号是主键,唯一标识一条销售订单记录。产品编号和客户编号是两个外键,分别引用产品表和客户表的主键。另外三个属性是订单时间、登记时间和订单金额。订单时间指的是客户下订单的时间,订单金额属性指的是该笔订单需要花费的金额,这些属性的含义很清楚。订单登记时间表示订单录入的时间,大多数情况下它应该等同于订单时间。如果由于某种情况需要重新录入订单,还要同时记录原始订单的时间和重新录入的时间,或者出现某种问题,订单登记时间滞后于下订单的时间,这两个属性值就会不同。
源系统采用关系模型设计,为了减少表的数量,这个系统只做到了2NF。地区信息依赖于邮编,所以这个模型中存在传递依赖。
2. 销售订单数据仓库模型
使用以下步骤设计数据仓库模型。
- 选择业务流程。在本示例中只涉及一个销售订单的业务流程。
- 声明粒度。ETL处理时间周期为每天一次,事实表中存储最细粒度的订单事务记录。
- 确认维度。显然产品和客户是销售订单的维度。日期维度用于业务集成,并为数据仓库提供重要的历史视角,每个数据仓库中都应该有一个日期维度。订单维度是特意设计的,用于说明退化维度技术。
- 确认事实。销售订单是当前场景中唯一的事实。
示例数据仓库的实体关系图如图2所示。
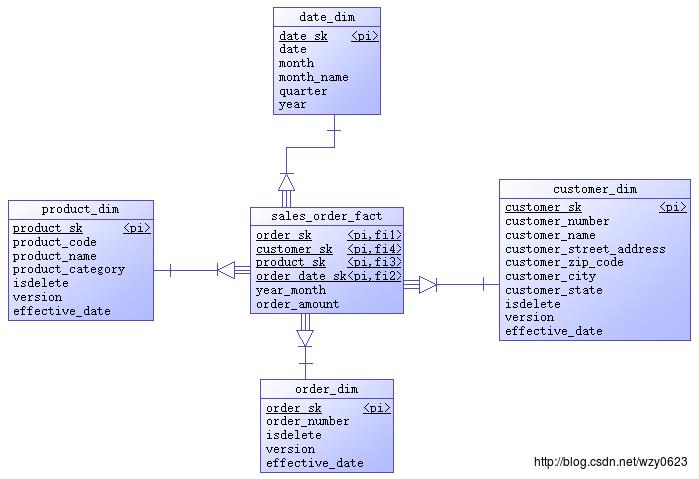
图2
二、数据仓库架构
“架构”是什么?这个问题从来就没有一个准确的答案。在软件行业,一种被普遍接受的架构定义是指系统的一个或多个结构。结构中包括软件的构建(构建是指软件的设计与实现),构建的外部可以看到属性以及它们之间的相互关系。参考此定义,这里把数据仓库架构理解成构成数据仓库的组件及其之间的关系,那么就有了下面的数据仓库架构图。
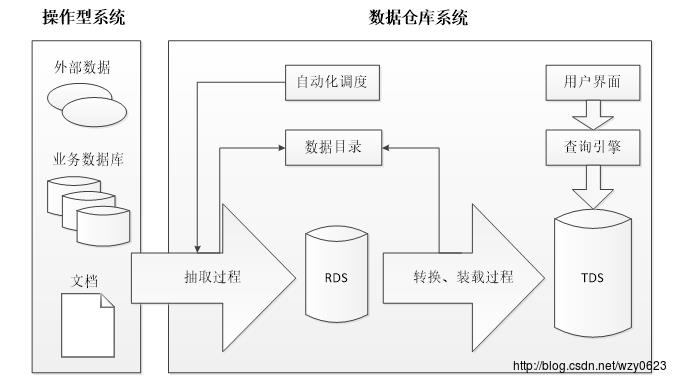
图3
图中显示的整个数据仓库环境包括操作型系统和数据仓库系统两大部分。操作型系统的数据经过抽取、转换和装载(ETL)过程进入数据仓库系统。这里把ETL过程分成了抽取和转换装载两个部分。抽取过程负责从操作型系统获取数据,该过程一般不做数据聚合和汇总,物理上是将操作型系统的数据全量或增量复制到数据仓库系统的RDS中。转换装载过程将数据进行清洗、过滤、汇总、统一格式化等一系列转换操作,使数据转为适合查询的格式,然后装载进数据仓库系统的TDS中。传统数据仓库的基本模式是用一些过程将操作型系统的数据抽取到文件,然后另一些过程将这些文件转化成mysql这样的关系数据库的记录。最后,第三部分过程负责把数据导入进数据仓库。本例中的业务数据使用MySQL数据库存储。
RDS(RAW DATA STORES)是原始数据存储的意思。它的作用主要有三个:作为数据缓冲区;提供细节数据;保留原始数据,便于跟踪和修正ETL的错误。本例中的RDS使用HAWQ的HDFS外部表。
TDS(TRANSFORMED DATA STORES)意为转换后的数据存储。这里存储真正的数据仓库中的数据。本例中的TDS使用HAWQ内部表。
自动化调度组件的作用是自动定期重复执行ETL过程。作为通用的需求,所有数据仓库系统都应该能够建立周期性自动执行的工作流作业。传统数据仓库一般利用操作系统自带的调度功能(如Linux的cron或Windows的计划任务)实现作业自动执行。本示例使用Falcon完成自动调度任务。
数据目录有时也被称为元数据存储,它可以提供一份数据仓库中数据的清单。一个好的数据目录是让用户体验到系统易用性的关键。HAWQ是数据库系统,自带元数据表。
查询引擎组件负责实际执行用户查询。传统数据仓库中,它可能是存储转换后数据的MySQL等关系数据库系统内置的查询引擎,还可能是以固定时间间隔向其导入数据的OLAP立方体,如Essbase cube。HAWQ本身就是以一个强大的查询引擎而存在,本示例使用HAWQ作为查询引擎正是物尽其用。
用户界面指的是最终用户所使用的接口程序。可能是一个GUI软件,如BI套件的中的客户端软件,也可能就是一个浏览器。本示例的用户界面使用Zeppelin。
三、实验环境
1. 硬件环境
四台VMware虚机组成的Hadoop集群,每台机器配置如下:
- 15K RPM SAS 100GB
- Intel(R) Xeon(R) E5-2620 v2 @ 2.10GHz,双核双CPU
- 8G内存,8GSwap
- 10000Mb/s虚拟网卡
2. 软件环境
- Linux:CentOS release 6.4,核心2.6.32-358.el6.x86_64
- Ambari:2.4.1
- Hadoop:HDP 2.5.0
- HAWQ:2.1.1.0
- HAWQ PXF:3.1.1
- MySQL 5.6.14
HDP与HAWQ的安装部署参考“用HAWQ轻松取代传统数据仓库(二) —— 安装部署”。表1汇总了各主机的角色。
| 主机名 | IP地址 | 角色 |
| hdp1 | 172.16.1.124 | HAWQ Segment |
| hdp2 | 172.16.1.125 | HAWQ Standby Master、HAWQ Segment |
| hdp3 | 172.16.1.126 | HAWQ Primary Master、HAWQ Segment |
| hdp4 | 172.16.1.127 | HAWQ Segment、MySQL |
表1
四、HAWQ相关配置
1. 创建客户端认证
编辑master上的/data/hawq/master/pg_hba.conf文件,添加dwtest用户,如图4所示。
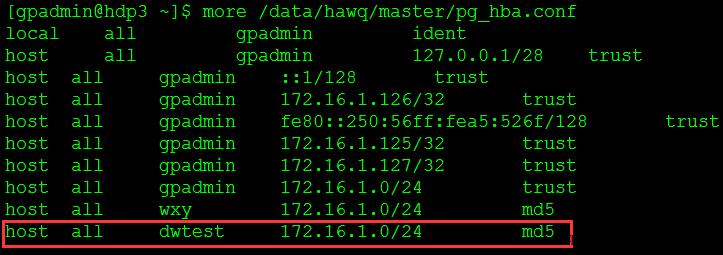
图4
2. 设置并发连接参数
-- 设置参数
hawq config -c max_connections -v 100
hawq config -c seg_max_connections -v 1000
hawq config -c max_prepared_transactions -v 200
-- 重启HAWQ
hawq restart cluster
-- 查看配置
hawq config -s max_connections
hawq config -s seg_max_connections
hawq config -s max_prepared_transactions查看参数值如图5所示。
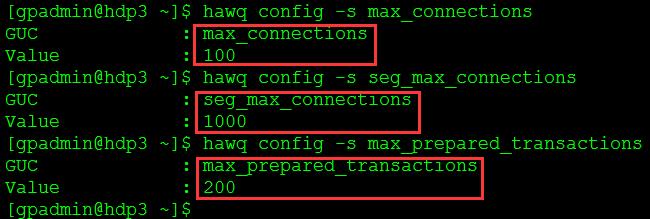
图5
(1)max_connections
限制master允许的最大客户端并发连接数,缺省值是1280。在HAWQ系统中,用户客户端只能通过master实例连接到系统。此参数的值越大,HAWQ需要的共享内存越多。shared_buffers参数设置一个HAWQ segment实例使用的共享内存缓冲区的,缺省值是125MB,最小值是128KB与16KB * max_connections的较大者。如果连接HAWQ时发生共享内存分配的错误,可以尝试增加SHMMAX或SHMALL操作系统参数的值,或者降低shared_buffers或者max_connections参数的值解决此类问题。
(2)seg_max_connections
限制segment允许master发起的最大并发连接数,缺省值是1280。该参数应该设置为max_connections的5-10倍。增加此参数时必须同时增加max_prepared_transactions参数的值。与master类似,此参数的值越大,HAWQ需要的共享内存越多。
(3)max_prepared_transactions
设置同时处于准备状态的事务数,缺省值为250。HAWQ内部使用准备事务保证跨segment的数据完整性。
3. 创建数据库用户
(1)用gpadmin连接HAWQ,建立用户dwtest,授予建库权限。
-- 创建用户
create role dwtest with password '123456' login createdb;
-- 查看用户
\\dg查看用户如图6所示。
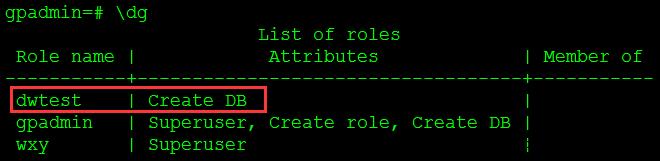
图6
(2)测试登录
psql -U dwtest -d gpadmin -h hdp3
-- 查看数据库
\\l连接成功后,查看数据库如图7所示。
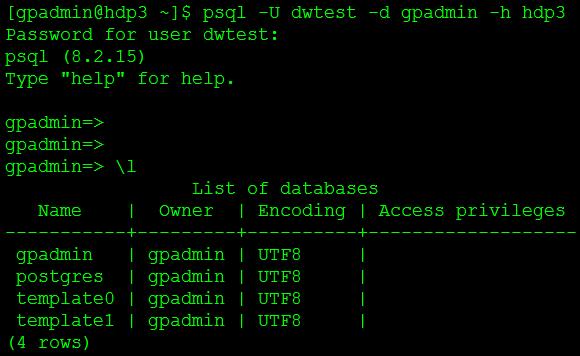
图7
4. 创建资源队列
(1)将缺省的pg_default的资源限制由50%改为20%,同时将过度使用因子设置为5。
alter resource queue pg_default with
(memory_limit_cluster=20%,core_limit_cluster=20%,resource_overcommit_factor=5);
(2)建立一个dwtest用户使用的专用队列,资源限制由80%,同时将过度使用因子设置为2。
create resource queue dwtest_queue with
(parent='pg_root', memory_limit_cluster=80%, core_limit_cluster=80%,resource_overcommit_factor=2);
(3)查看资源队列配置,结果如图8所示。
select rsqname,
parentoid,
activestats,
memorylimit,
corelimit,
resovercommit,
allocpolicy,
vsegresourcequota,
nvsegupperlimit,
nvseglowerlimit,
nvsegupperlimitperseg,
nvseglowerlimitperseg
from pg_resqueue;
图8
(4)用gpadmin将dwtest用户的资源队列设置为新建的dwtest_queue,结果如图9所示。
-- 修改用户资源队列
alter role dwtest resource queue dwtest_queue;
-- 查看用户资源队列
select rolname, rsqname from pg_roles, pg_resqueue
where pg_roles.rolresqueue=pg_resqueue.oid;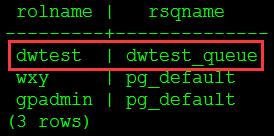
图9
假设其他用户都使用缺省的pg_default队列。采用以上定义,工作负载通过资源队列划分如下:
- 如果没有活跃用户使用pg_default队列时,dwtest用户可以使用100%的资源。
- 如果有同时使用pg_default队列的其它用户,则dwtest用户使用80%,其它用户使用20%资源。
- 如果没有dwtest用户的活跃任务,其它使用pg_default队列的用户可以使用100%的资源。
5. 配置资源
(1)查看集群所有节点都已启动,结果如图10所示。
select * from gp_segment_configuration;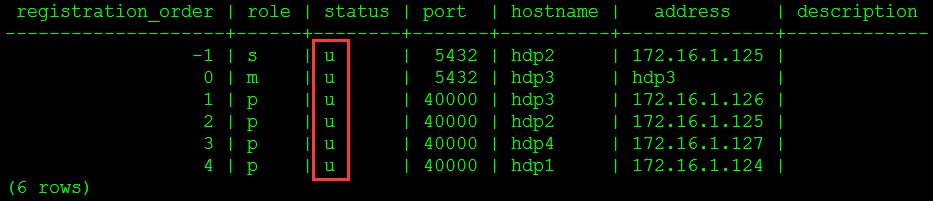
图10
所有节点的状态都应该是启动状态(status='u')。hawq_rm_rejectrequest_nseg_limit参数保持缺省值0.25,就是说现有集群的全部4个segment中如果有两个宕机,则HAWQ的资源管理器将直接拒绝查询的资源请求。
(2)资源管理使用缺省的独立模式,如图11所示。
在该模式下,HAWQ使用集群节点资源时,不考虑其它共存的应用,HAWQ假设它能使用所有segment的资源。对于专用HAWQ集群,独立模式是可选的方案。
hawq config -s hawq_global_rm_type
图11
(3)设置segment资源配额,如图12所示。
物理内存8G,双核双CPU,共4个虚拟CPU核。所以每个segment使用的内存与CPU核数配额分别配置为8GB和4,最大限度使用资源。
hawq config -s hawq_rm_memory_limit_perseg
hawq config -s hawq_rm_nvcore_limit_perseg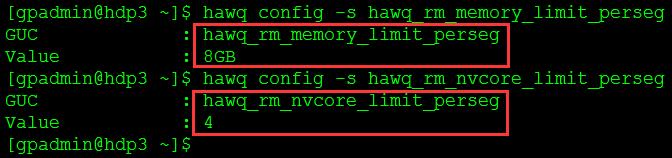
图12
所有资源队列中虚拟段的资源限额均为缺省的256MB,每个segment可以分配32个虚拟段。并且8GB是256MB的32倍,每核2GB内存,这种配置防止形成资源碎片。
6. 在HDFS上创建HAWQ外部表对应的目录
su - hdfs -c 'hdfs dfs -mkdir -p /data/ext'
su - hdfs -c 'hdfs dfs -chown -R gpadmin:gpadmin /data/ext'
su - hdfs -c 'hdfs dfs -chmod -R 777 /data/ext'
su - hdfs -c 'hdfs dfs -chmod -R 777 /user'
su - hdfs -c 'hdfs dfs -ls /data'结果如图13所示。
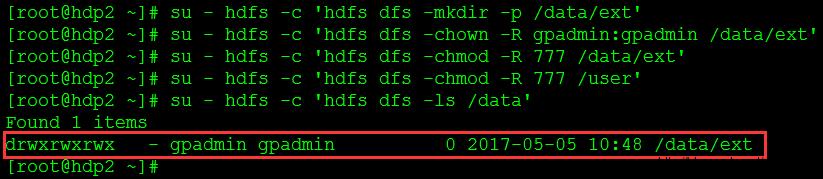
图13
五、创建测试数据库
1. 创建源库对象并生成测试数据
(1)执行下面的SQL语句在MySQL中建立源数据库表。
-- 建立源数据库
drop database if exists source;
create database source;
use source;
-- 建立客户表
create table customer (
customer_number int not null auto_increment primary key comment '客户编号,主键',
customer_name varchar(50) comment '客户名称',
customer_street_address varchar(50) comment '客户住址',
customer_zip_code int comment '邮编',
customer_city varchar(30) comment '所在城市',
customer_state varchar(2) comment '所在省份'
);
-- 建立产品表
create table product (
product_code int not null auto_increment primary key comment '产品编码,主键',
product_name varchar(30) comment '产品名称',
product_category varchar(30) comment '产品类型'
);
-- 建立销售订单表
create table sales_order (
order_number int not null auto_increment primary key comment '订单号,主键',
customer_number int comment '客户编号',
product_code int comment '产品编码',
order_date datetime comment '订单日期',
entry_date datetime comment '登记日期',
order_amount decimal(10 , 2 ) comment '销售金额',
foreign key (customer_number)
references customer (customer_number)
on delete cascade on update cascade,
foreign key (product_code)
references product (product_code)
on delete cascade on update cascade
);
(2)执行下面的SQL语句生成源库测试数据。
use source;
-- 生成客户表测试数据
insert into customer
(customer_name,customer_street_address,customer_zip_code,
customer_city,customer_state)
values
('really large customers', '7500 louise dr.',17050, 'mechanicsburg','pa'),
('small stores', '2500 woodland st.',17055, 'pittsburgh','pa'),
('medium retailers','1111 ritter rd.',17055,'pittsburgh','pa'),
('good companies','9500 scott st.',17050,'mechanicsburg','pa'),
('wonderful shops','3333 rossmoyne rd.',17050,'mechanicsburg','pa'),
('loyal clients','7070 ritter rd.',17055,'pittsburgh','pa'),
('distinguished partners','9999 scott st.',17050,'mechanicsburg','pa');
-- 生成产品表测试数据
insert into product (product_name,product_category)
values
('hard disk drive', 'storage'),
('floppy drive', 'storage'),
('lcd panel', 'monitor');
-- 生成100条销售订单表测试数据
drop procedure if exists generate_sales_order_data;
delimiter //
create procedure generate_sales_order_data()
begin
drop table if exists temp_sales_order_data;
create table temp_sales_order_data as select * from sales_order where 1=0;
set @start_date := unix_timestamp('2016-03-01');
set @end_date := unix_timestamp('2016-07-01');
set @i := 1;
while @i<=100 do
set @customer_number := floor(1 + rand() * 6);
set @product_code := floor(1 + rand() * 2);
set @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
set @amount := floor(1000 + rand() * 9000);
insert into temp_sales_order_data values (@i,@customer_number,@product_code,@order_date,@order_date,@amount);
set @i:=@i+1;
end while;
truncate table sales_order;
insert into sales_order
select null,customer_number,product_code,order_date,entry_date,order_amount from temp_sales_order_data order by order_date;
commit;
end
//
delimiter ;
call generate_sales_order_data(); 说明:创建了一个MySQL存储过程生成100条销售订单测试数据。为了模拟实际订单的情况,订单表中的客户编号、产品编号、订单时间和订单金额都取一个范围内的随机值,订单时间与登记时间相同。因为订单表的主键是自增的,为了保持主键值和订单时间字段的值顺序保持一致,引入了一个名为temp_sales_order_data的表,存储中间临时数据。在后面章节中都是使用此方案生成订单测试数据。
(3)创建读取源数据的用户
create user 'dwtest'@'%' identified by '123456';
grant select on source.* to 'dwtest'@'%';
2. 创建目标库及其模式
(1)用dwtest用户连接HAWQ
psql -U dwtest -d gpadmin -h hdp3
(2)建立数据库dw
create database dw;
(3)在dw库中建立模式rds和tds,结果如图14所示。
-- 连接dw数据库
\\c dw
-- 创建ext模式
create schema ext;
-- 创建rds模式
create schema rds;
-- 创建tds模式
create schema tds;
-- 查看模式
\\dn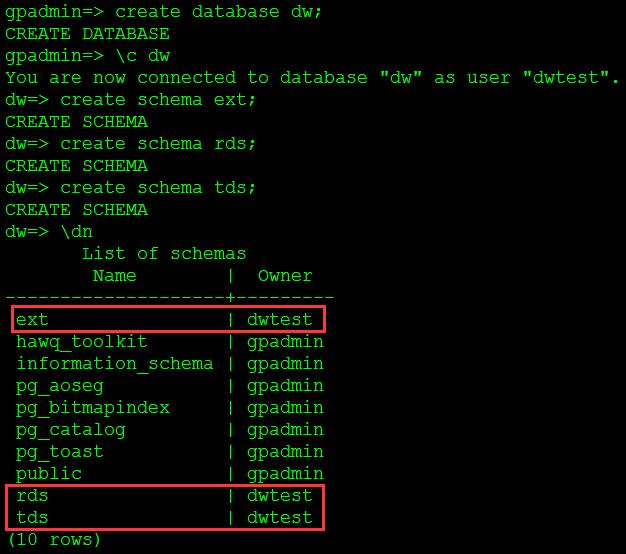
图14
(4)设置模式查找路径,结果如图15所示。
-- 修改数据库的模式查找路径
alter database dw set search_path to ext, rds, tds;
-- 重新连接dw数据库
\\c dw
-- 显示模式查找路径
show search_path;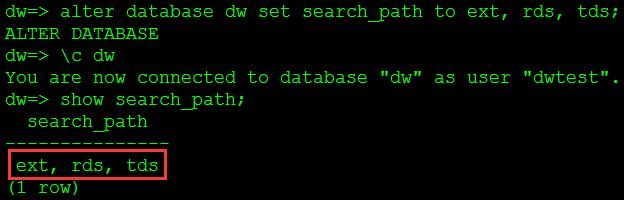
图15
HAWQ的模式是数据库中对象和数据的逻辑组织。模式允许在一个数据库中有多个同名的对象,如表。如果对象属于不同的模式,同名对象之间不会冲突。使用schema有如下好处:
- 方便管理多个用户共享一个数据库,但是又可以互相独立。
- 方便管理众多对象,更有逻辑性。
- 方便兼容某些第三方应用程序,如果创建对象时是带schema的。
每个HAWQ会话在任一时刻只能连接一个数据库,因此将RDS和TDS对象存放单独的数据库显然是不合适的。这里在dw库中创建了ext、rds、tds三个模式。在前面描述数据仓库架构时只提到了RDS和TDS,并指出本示例的RDS使用HAWQ的HDFS外部表,为什么这里创建了三个模式呢?究其原因有如下:
- Sqoop可以将MySQL数据导入到HDFS或hive,但目前还没有命令行工具可以将MySQL数据直接导入到HAWQ数据库中。所以不得不将缓冲数据存储到HDFS,再利用HAWQ的外部表进行访问。
- 如果只创建两个模式分别用作RDS和TDS,则会带来性能问题。在变化数据捕获(CDC)时需要关联RDS和TDS的表,而HAWQ的外部表和内部表关联查询的速度是很慢的,在数据量非常大的情况下,更是慢到不能忍受。
- 通常维度数据量比事实数据量小得多。在这个前提下,用EXT模式存储直接从MySQL导出的外部数据,包括全部维度数据和增量的事实数据,然后将这些数据装载进RDS模式内部表中。这一步装载的数据量并不是很大,而且没有关联逻辑,都是简单的单表查询与数据插入。在装载TDS内部表时,仍然关联RDS与TDS的表,但这两个模式中的表都是内部表,查询速度是可接受的。
这里使用三个schema来划直接外部数据、源数据存储和多维数据仓库的对象,不但逻辑上非常清晰,而且兼顾了ETL的处理速度。
3. 创建EXT模式中的数据库对象
(1)用HAWQ管理员用户授予dwtest用户在dw库中创建外部表的权限
psql -d dw -h hdp3 -c "grant all on protocol pxf to dwtest"如果不授予相应权限,创建外部表时会报以下错误:
ERROR: permission denied for external protocol pxf
(2)创建HAWQ外部表
-- 设置模式查找路径
set search_path to ext;
-- 建立客户外部表
create external table customer
(
customer_number int,
customer_name varchar(30),
customer_street_address varchar(30),
customer_zip_code int,
customer_city varchar(30),
customer_state varchar(2)
)
location ('pxf://mycluster/data/ext/customer?profile=hdfstextsimple')
format 'text' (delimiter=e',');
comment on table customer is '客户外部表';
comment on column customer.customer_number is '客户编号';
comment on column customer.customer_name is '客户姓名';
comment on column customer.customer_street_address is '客户地址';
comment on column customer.customer_zip_code is '客户邮编';
comment on column customer.customer_city is '客户所在城市';
comment on column customer.customer_state is '客户所在省份';
-- 建立产品外部表
create external table product
(
product_code int,
product_name varchar(30),
product_category varchar(30)
)
location ('pxf://mycluster/data/ext/product?profile=hdfstextsimple')
format 'text' (delimiter=e',');
comment on table product is '产品外部表';
comment on column product.product_code is '产品编码';
comment on column product.product_name is '产品名称';
comment on column product.product_category is '产品类型';
-- 建立销售订单外部表
create external table sales_order
(
order_number int,
customer_number int,
product_code int,
order_date timestamp,
entry_date timestamp,
order_amount decimal(10 , 2 )
)
location ('pxf://mycluster/data/ext/sales_order?profile=hdfstextsimple')
format 'text' (delimiter=e',', null='null');
comment on table sales_order is '销售订单外部表';
comment on column sales_order.order_number is '订单号';
comment on column sales_order.customer_number is '客户编号';
comment on column sales_order.product_code is '产品编码';
comment on column sales_order.order_date is '订单日期';
comment on column sales_order.entry_date is '登记日期';
comment on column sales_order.order_amount is '销售金额';说明:
- 外部表结构与MySQL里的源表完全对应,其字段与源表相同。
- PXF外部数据位置指向前面(四.6)创建的HDFS目录。
- 文件格式使用逗号分隔的简单文本格式,文件中的'null'字符创代表数据库中的NULL值。下一篇说明的数据初始装载时会看到,为了让EXT的数据文件尽可能的小,Sqoop使用了压缩选项,而hdfstextsimples属性的PXF外部表能自动正确读取Sqoop缺省的gzip压缩文件。
4. 创建RDS模式中的数据库对象
-- 设置模式查找路径
set search_path to rds;
-- 建立客户原始数据表
create table customer
(
customer_number int,
customer_name varchar(30),
customer_street_address varchar(30),
customer_zip_code int,
customer_city varchar(30),
customer_state varchar(2)
);
comment on table customer is '客户原始数据表';
comment on column customer.customer_number is '客户编号';
comment on column customer.customer_name is '客户姓名';
comment on column customer.customer_street_address is '客户地址';
comment on column customer.customer_zip_code is '客户邮编';
comment on column customer.customer_city is '客户所在城市';
comment on column customer.customer_state is '客户所在省份';
-- 建立产品原始数据表
create table product
(
product_code int,
product_name varchar(30),
product_category varchar(30)
);
comment on table product is '产品原始数据表';
comment on column product.product_code is '产品编码';
comment on column product.product_name is '产品名称';
comment on column product.product_category is '产品类型';
-- 建立销售订单原始数据表
create table sales_order
(
order_number int,
customer_number int,
product_code int,
order_date timestamp,
entry_date timestamp,
order_amount decimal(10 , 2 )
)
partition by range (entry_date)
( start (date '2016-01-01') inclusive
end (date '2018-01-01') exclusive
every (interval '1 month') );
;
comment on table sales_order is '销售订单原始数据表';
comment on column sales_order.order_number is '订单号';
comment on column sales_order.customer_number is '客户编号';
comment on column sales_order.product_code is '产品编码';
comment on column sales_order.order_date is '订单日期';
comment on column sales_order.entry_date is '登记日期';
comment on column sales_order.order_amount is '销售金额';说明:
- RDS模式中的表是HAWQ内部表。
- RDS模式中表数据来自EXT表,并且是原样装载,不需要任何转换,因此其表结构与EXT中的外部表一致。
- HAWQ支持row和parquet两种数据存储格式。如果单纯从性能方面考虑,似乎parquet列格式更适合数据仓库应用。这里使用缺省的row格式,只因为注意到文档中这样一句话:“HAWQ does not support using ALTER TABLE to ADD or DROP a column in an existing Parquet table.”。我还没遇到哪个数据库表创建完后就再也不用增删字段的情况。关于行列存储的选择,参见“大数据存取的选择:行存储还是列存储?”
- 为了保持查询弹性使用资源和更好的数据本地化,使用缺省的随机数据分布策略,而没有使用哈希分布。关于HAWQ表数据的存储与分布,参见“用HAWQ轻松取代传统数据仓库(七) —— 存储分布”。
- RDS是实际上是原始业务数据的副本,维度数据量小,可以覆盖装载全部数据,而事实数据量大,需要追加装载每天的新增数据。因此事实表采取分区表,每月数据一分区,以登记日期作为分区键,预创建2017年一年的分区。
5. 创建TDS模式中的数据库对象
-- 设置模式查找路径
set search_path to tds;
-- 建立客户维度表
create table customer_dim (
customer_sk bigserial,
customer_number int,
customer_name varchar(50),
customer_street_address varchar(50),
customer_zip_code int,
customer_city varchar(30),
customer_state varchar(2),
isdelete boolean default false,
version int,
effective_date date
);
comment on table customer_dim is '客户维度表';
comment on column customer_dim.customer_sk is '客户维度代理键';
comment on column customer_dim.customer_number is '客户编号';
comment on column customer_dim.customer_name is '客户姓名';
comment on column customer_dim.customer_street_address is '客户地址';
comment on column customer_dim.customer_zip_code is '客户邮编';
comment on column customer_dim.customer_city is '客户所在城市';
comment on column customer_dim.customer_state is '客户所在省份';
comment on column customer_dim.isdelete is '是否删除';
comment on column customer_dim.version is '版本';
comment on column customer_dim.effective_date is '生效日期';
-- 建立产品维度表
create table product_dim (
product_sk bigserial,
product_code int,
product_name varchar(30),
product_category varchar(30),
isdelete boolean default false,
version int,
effective_date date
);
comment on table product_dim is '产品维度表';
comment on column product_dim.product_sk is '产品维度代理键';
comment on column product_dim.product_code is '产品编码';
comment on column product_dim.product_name is '产品名称';
comment on column product_dim.product_category is '产品类型';
comment on column product_dim.isdelete is '是否删除';
comment on column product_dim.version is '版本';
comment on column product_dim.effective_date is '生效日期';
-- 建立订单维度表
create table order_dim (
order_sk bigserial,
order_number int,
isdelete boolean default false,
version int,
effective_date date
);
comment on table order_dim is '订单维度表';
comment on column order_dim.order_sk is '订单维度代理键';
comment on column order_dim.order_number is '订单号';
comment on column order_dim.isdelete is '是否删除';
comment on column order_dim.version is '版本';
comment on column order_dim.effective_date is '生效日期';
-- 建立日期维度表
create table date_dim (
date_sk int,
date date,
month smallint,
month_name varchar(9),
quarter smallint,
year smallint
);
comment on table date_dim is '日期维度表';
comment on column date_dim.date_sk is '日期维度代理键';
comment on column date_dim.date is '日期';
comment on column date_dim.month is '月份';
comment on column date_dim.month_name is '月份名称';
comment on column date_dim.quarter is '季度';
comment on column date_dim.year is '年份';
-- 建立销售订单事实表
create table sales_order_fact (
order_sk bigint,
customer_sk bigint,
product_sk bigint,
order_date_sk bigint,
year_month int,
order_amount decimal(10 , 2 )
)
partition by range (year_month)
( partition p201601 start (201601) inclusive ,
partition p201602 start (201602) inclusive ,
partition p201603 start (201603) inclusive ,
partition p201604 start (201604) inclusive ,
partition p201605 start (201605) inclusive ,
partition p201606 start (201606) inclusive ,
partition p201607 start (201607) inclusive ,
partition p201608 start (201608) inclusive ,
partition p201609 start (201609) inclusive ,
partition p201610 start (201610) inclusive ,
partition p201611 start (201611) inclusive ,
partition p201612 start (201612) inclusive ,
partition p201701 start (201701) inclusive ,
partition p201702 start (201702) inclusive ,
partition p201703 start (201703) inclusive ,
partition p201704 start (201704) inclusive ,
partition p201705 start (201705) inclusive ,
partition p201706 start (201706) inclusive ,
partition p201707 start (201707) inclusive ,
partition p201708 start (201708) inclusive ,
partition p201709 start (201709) inclusive ,
partition p201710 start (201710) inclusive ,
partition p201711 start (201711) inclusive ,
partition p201712 start (201712) inclusive
end (201801) exclusive );
comment on table sales_order_fact is '销售订单事实表';
comment on column sales_order_fact.order_sk is '订单维度代理键';
comment on column sales_order_fact.customer_sk is '客户维度代理键';
comment on column sales_order_fact.product_sk is '产品维度代理键';
comment on column sales_order_fact.order_date_sk is '日期维度代理键';
comment on column sales_order_fact.year_month is '年月分区键';
comment on column sales_order_fact.order_amount is '销售金额';说明:
- TDS模式中的表是HAWQ内部表。
- 比源库多了一个日期维度表。数据仓库可以追踪历史数据,因此每个数据仓库都有日期时间相关的维度表。
- 为了捕获和表示数据变化,除日期维度表外,其它维度表比源表多了代理键、是否删除标志、版本号和版本生效日期四个字段。日期维度一次性生成数据后就不会改变,因此除了日期本身相关属性,只增加了一列代理键。
- 事实表由维度表的代理键和度量属性构成。目前只有一个销售订单金额的度量值。
- 由于事实表数据量大,事实表采取分区表。事实表中冗余了一列年月,作为分区键。之所以用年月做范围分区,是考虑到数据分析时经常使用年月分组进行查询和统计,这样可以有效利用分区消除提高查询性能。与rds.sales_order不同,这里显式定义了2017一年的分区。
- 出于同样的考虑,与RDS一样,TDS表也使用row存储格式和随机数据分布策略。
6. 装载日期维度数据
日期维度在数据仓库中是一个特殊角色。日期维度包含时间概念,而时间是最重要的,因为数据仓库的主要功能之一就是存储历史数据,所以每个数据仓库里的数据都有一个时间特征。本例中创建一个HAWQ的函数,预装载日期数据。
-- 生成日期维度表数据的函数
create or replace function fn_populate_date (start_dt date, end_dt date)
returns void as
$$
declare
i int:=1;
v_date date:= start_dt;
v_datediff int:= end_dt - start_dt;
begin
truncate table date_dim;
insert into date_dim(date_sk, date, month, month_name, quarter, year)
values(i, v_date, extract(month from v_date), to_char(v_date,'mon'), extract(quarter from v_date), extract(year from v_date));
while i <= v_datediff
loop
insert into date_dim(date_sk, date, month, month_name, quarter, year)
select date_sk + i, date + i,
extract(month from date+i),
to_char(date+i,'mon'),
extract(quarter from date+i),
extract(year from date+i)
from date_dim where date +i <= end_dt;
i := i*2;
end loop;
analyze date_dim;
end;
$$
language plpgsql;
-- 执行函数生成日期维度数据
select fn_populate_date(date '2000-01-01', date '2020-12-31');
-- 查询生成的日期
select min(date_sk) min_sk, min(date) min_date, max(date_sk) max_sk, max(date) max_date, count(*) c from date_dim;结果如图16所示。
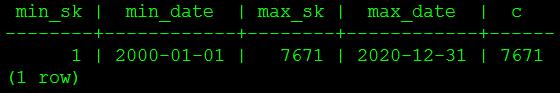
图16
以上是关于HAWQ实践——搭建示例模型(MySQLHAWQ)的主要内容,如果未能解决你的问题,请参考以下文章
基于CentOS-7+ Ambari 2.7.0 + HDP 3.0搭建HAWQ数据仓库之一 —— MariaDB 安装配置