对比HiveSpark和Impala,为什么选HAWQ | HAWQ实战系列
Posted 偶数科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对比HiveSpark和Impala,为什么选HAWQ | HAWQ实战系列相关的知识,希望对你有一定的参考价值。
我们一直希望为大家带来一手又接地气的技术干货,在分享一些原创内容的同时,也欢迎大家投稿。作为HAWQ实战系列的第二篇,本次我们邀请到了HAWQ资深专家王雪迎老师谈一谈选择数据仓库时的心得。
作者简介:
王雪迎,20多年的数据库、数据仓库、大数据相关工作。图书《Hadoop构建数据仓库实践》、《HAWQ数据仓库与数据挖掘实战》、《SQL机器学习库——MADlib技术解析》作者,曾担任DBA、数据架构师等职位。
时光荏苒,Hadoop成为Apache顶级项目至今已有十年。当时在新兴的大数据领域,Hadoop可以说是风头无两,甚至被许多大数据从业者奉为圭臬。传统数据库开发人员或DBA也开始跃跃欲试,希望在新的平台上继续使用SQL解决实际问题。在这样的背景下,作为其生态圈重要组成部分的SQL-on-Hadoop涌现出大量产品。
近年来我曾尝试过Hive、Spark SQL、Impala等几种SQL-on-Hadoop产品,进行了一系列ETL、CDC、多维数据仓库、OLAP实验。从数据库的角度看,我个人的总体感觉是这些产品与传统的DBMS相比,功能不够完善,性能差距较大,以至于在使用它们时总是感到顾此失彼、捉襟见肘,很难找到一个相对完备的Hadoop数据仓库解决方案。
然而,这种情况在2017年遇到HAWQ后有所改变。作为SQL-on-Hadoop家族的后起之秀,HAWQ性能表现尤为突出。更为关键的是HAWQ与SQL的兼容性非常好,甚至支持存储过程,这是我以往所接触过的产品中从未有过的。如果只用一句话说明HAWQ与其它相关产品的区别,那就是HAWQ是一个真正的分布式数据库。对于传统数据库使用者而言,通过HAWQ转向大数据平台的学习成本应该是很低的。这里就以我个人的实践体验,简述几种常用SQL-on-Hadoop产品的不足,以及HAWQ的可行性。
一、常用SQL-on-Hadoop产品的不足
1. Hive
Hive是最老牌的一款Hadoop数据仓库产品,能够部署在所有Hadoop发行版本上。它在MapReduce计算框架上封装一个SQL语义层,极大简化了MR程序的开发。直到现在,Hive依然以其稳定性赢得大量用户。
但是Hive的缺点也很明显——速度太慢。随着技术的不断进步,Hive的执行引擎也从MapReduce一种,发展出Hive on Spark、Hive on Tez等。特别是运行在Tez框架上的Hive,其性能有了长足改进。但是即便如此,Hive的速度还是比较适合后台批处理应用场景,而不适合交互式即席查询和联机分析。
2. Spark SQL
Spark SQL是Hadoop中另一个著名的SQL引擎,正如名字所表示的,它以Spark作为底层计算框架,实际上是一个Scala程序语言的子集。Spark基本的数据结构是RDD,一个分布于集群节点的只读数据集合。传统的MapReduce框架强制在分布式编程中使用一种特定的线性数据流处理方式。MapReduce程序从磁盘读取输入数据,把数据分解成键/值对,经过混洗、排序、归并等数据处理后产生输出,并将最终结果保存在磁盘。Map阶段和Reduce阶段的结果均要写磁盘,这大大降低了系统性能。也是由于这个原因,MapReduce大都被用于执行批处理任务。
为了解决MapReduce的性能问题,Spark使用RDD共享内存结构。这种内存操作减少了磁盘I/O,提高了计算速度。Spark宣称其应用的延迟可以比MapReduce降低几个数量级,但是在我们的实际使用中,20TB的数据集合上用Spark SQL做查询要10分钟左右出结果,这个速度纵然是比Hive快了4倍,但显然不足以支撑交互查询和OLAP应用。Spark还有一个问题是需要占用大量内存,当内存不足时,很容易出现OOM错误。
3. Impala
Impala的最大优势在于它的执行速度。官方宣称大多数情况下它能在几秒或几分钟内返回查询结果,而相同的Hive查询通常需要几十分钟甚至几小时完成,因此Impala适合对Hadoop文件系统上的数据进行分析式查询。Impala缺省使用Parquet文件格式,这种列式存储方式对于典型数据仓库场景下的大查询是较为高效的。
Impala的问题主要体现在功能上的欠缺。如不支持Date数据类型,不支持XML和JSON相关函数,不支持covar_pop、covar_samp、corr、percentile、 percentile_approx、histogram_numeric、collect_set等聚合函数,不支持rollup、cube、grouping set等操作,不支持数据抽样(Sampling),不支持ORC文件格式等等。其中分组聚合、取中位数等是数据分析中的常用操作,当前的Impala存在如此多的局限,使它在可用性上大打折扣,实际使用时要格外注意。
二、HAWQ的可行性
前面介绍的几种SQL-on-Hadoop产品在实际应用中都力所不逮,现在看HAWQ是否能取而代之。作为用户,我们从功能与性能两方面的关注点,简单分析一下使用HAWQ在Hadoop上构建分析型数据仓库应用的可行性。
1. 功能
(1)兼容SQL标准
HAWQ从代码级别上可以简单理解成是数据存储在HDFS上的Greenplum数据库,全面兼容SQL标准。它支持内连接、外连接、全连接、笛卡尔连接、相关子查询等所有表连接方式,支持并集、交集、差集等集合操作,并支持递归函数调用。作为一个数据库系统,提供这些功能很好理解。
(2)丰富的函数
除了包含诸多字符串、数字、日期时间、类型转换等常规标量函数以外,HAWQ还包含丰富的窗口函数和高级聚合函数,这些函数经常被用于分析型数据查询。窗口函数包括cume_dist、dense_rank、first_value、lag、last_valueexpr、lead、ntile、percent_rank、rank、row_number等。
高级聚合函数包括median、percentile_cont(expr) within group (order by expr [desc/asc])、percentile_disc (expr) within group (order by expr [desc/asc])、sum(array[])、pivot_sum (label[], label, expr)等。
(3)TPC-DS合规性
TPC-DS针对具有各种操作要求和复杂性的查询定义了99个模板,例如点对点、报告、迭代、OLAP、数据挖掘等。成熟的基于Hadoop的SQL系统需要支持和正确执行多数此类查询,以解决各种不同分析工作场景和使用案例中的问题。
图1所示的基准测试是通过TPC-DS中的99个模板生成的111个查询来执行的。图中显示了4种基于SQL-on-Hadoop常见系统的合规等级,绿色和蓝色分别表示:每个系统可以优化的查询个数;可以完成执行并返回查询结果的查询个数。从图中可以看到,HAWQ完成了所有查询,表现远优于其它系统。HAWQ虽然没有提供update、delete等DML语句,但通过其强大的数据查询功能,可以轻松实现多维数据仓库中渐变维(SCD)的处理需求。
(4)分区表
与传统DBMS系统类似,HAWQ也支持多种分区方法及多级分区,如List分区和Range分区。分区表对查询性能和数据可维护性都有很大帮助。
(5)过程化编程
HAWQ支持内建的SQL、C、Java、Perl、pgSQL、Python、R等多种语言的过程化编程。
(6)原生Hadoop文件格式支持
HAWQ支持HDFS上的AVRO、Parquet、平面文本等多种文件格式,支持snappy、gzip、quicklz、RLE等多种数据压缩方法。与Hive不同,HAWQ实现了schema-on-write(写时模式)数据验证处理,不符合表定义或存储格式的数据是不允许进入到表中的,这点与传统数据库管理系统保持一致。
(7)外部数据整合
HAWQ通过PXF模块提供访问HDFS上的JSON文件、Hive、HBase等外部数据的能力。除了用于访问HDFS文件的PXF协议,HAWQ还提供了gpfdist文件服务器,它利用HAWQ系统并行读写本地文件系统中的文件。
新版的HAWQ使用可插拔外部存储方案替换JAVAPXF,支持CSV、TEXT、ORC,Parquet等外部文件格式,性能高数倍,同时简化了用户安装部署和运维。
2. 性能
(1)基于成本的SQL查询优化器
HAWQ采用基于成本的SQL查询优化器,该查询优化器以针对大数据模块化查询优化器架构的研究成果为基础而设计,能够生成高效的执行计划。
HAWQ 2.4 启用了新的执行器,支持scan,projection,filter,aggregation等基本操作,性能比老版本的HAWQ提升了一个数量级。不支持的操作会fallback到老的执行器。
(2)与Impala的性能比较
同样采用MPP架构,图2是HAWQ提供的TPC-DS性能比较图,可以看到HAWQ平均比Impala快4.55倍。
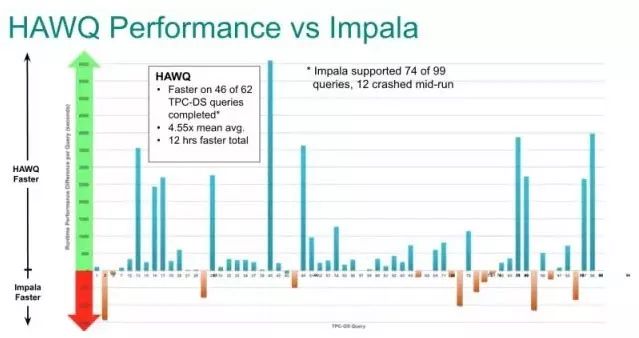
图2 HAWQ与Impala性能比较
(3)与Hive的性能比较
为了取得第一手数据,避免一家之言有失偏颇,我们自己做了HAWQ与Hive查询的性能对比测试。图3是实验环境中HAWQ与Hive查询性能对比图。测试具体的软硬件环境、数据模型、数据量、查询语句等参见“https://blog.csdn.net/wzy0623/article/details/71479539”。
图3 查询执行时间对比图
从图3中的对比可以看到,对于不同查询,HAWQ内部表比Hive onTez快4-50倍。但是同样的查询在HAWQ的PXF外部表上执行速度却天差地别。可见在执行分析型查询时最好使用HAWQ内部表。
三、适合DBA的解决方案
HAWQ最吸引人的地方是它支持SQL过程化编程,这是通过用户自定义函数(user-definedfunctions,UDF)实现的。编写UDF的语言可以是SQL、C、Java、Perl、Python、R和pgSQL。数据库应用开发人员常用的自然是SQL和pgSQL,PL/pgSQL函数可以为SQL语言增加控制结构,执行复杂计算任务,并继承所有PostgreSQL的数据类型(包括用户自定义类型)、函数和操作符。
HAWQ是我所使用过的SQL-on-Hadoop解决方案中唯一支持SQL过程化编程的,Hive、Spark SQL、Impala、Kylin都没有此功能。对于习惯了编写存储过程的DBA来说,这无疑大大提高了HAWQ的易用性。HAWQ的UDF提供以下特性:
给HAWQ内部函数起别名。
返回结果集的表函数。
参数个数可变的函数。
多态数据类型。
HAWQ过程化编程实例请点击左下角“阅读原文”。
更多新闻请点击:
以上是关于对比HiveSpark和Impala,为什么选HAWQ | HAWQ实战系列的主要内容,如果未能解决你的问题,请参考以下文章