用HAWQ轻松取代传统数据仓库 —— 存储分布
Posted wzy0623
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用HAWQ轻松取代传统数据仓库 —— 存储分布相关的知识,希望对你有一定的参考价值。
在HAWQ中创建一个表时,应该预先对数据如何分布、表的存储选项、数据导入导出方式和其它HAWQ特性做出选择,这些都将对数据库性能有极大影响。理解有效选项 的含义以及如何在数据库中使用它们,将有助于做出正确的选择。一、数据存储模型
create table的with子句用于设置表的存储选项。例如:
db1=# create table t1 (a int) with
db1-# (appendonly=true,
db1(# blocksize=8192,
db1(# orientation=row,
db1(# compresstype=zlib,
db1(# compresslevel=1,
db1(# fillfactor=50,
db1(# oids=false);
CREATE TABLEdb1=# create table sales
db1-# (id int, year int, month int, day int,region text)
db1-# distributed by (id)
db1-# partition by range (year)
db1-# subpartition by range (month)
db1-# subpartition template (
db1(# start (1) end (13) every (1),
db1(# default subpartition other_months )
db1-# subpartition by list (region)
db1-# subpartition template (
db1(# subpartition usa values ('usa') with
db1(# (appendonly=true,
db1(# blocksize=8192,
db1(# orientation=row,
db1(# compresstype=zlib,
db1(# compresslevel=1,
db1(# fillfactor=50,
db1(# oids=false),
db1(# subpartition europe values ('europe'),
db1(# subpartition asia values ('asia'),
db1(# default subpartition other_regions)
db1-# ( start (2002) end (2010) every (1),
db1(# default partition outlying_years);
...
CREATE TABLE1. APPENDONLY
因为HDFS上文件中的数据只能追加,不允许修改或删除,所以该选项只能设置为TRUE,设置为FALSE会报错:
db1=# create table t1(a int) with (appendonly=true);
CREATE TABLE
db1=# create table t2(a int) with (appendonly=false);
ERROR: tablespace "dfs_default" does not support heap relation2. BLOCKSIZE
设置表中每个数据块的字节数,值在8192到2097152之间,而且必须是8192的倍数,缺省值为32768。该属性必须与appendonly=true一起使用,并且只支持行存储模型:
db1=# create table t1(a int) with (blocksize=8192);
ERROR: invalid option 'blocksize' for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (appendonly=true,blocksize=8192);
CREATE TABLE
db1=# create table t2(a int) with (appendonly=true,blocksize=8192,orientation=parquet);
ERROR: invalid option 'blocksize' for parquet table
db1=# create table t2(a int) with (appendonly=true,blocksize=8192,orientation=row);
CREATE TABLE3. bucketnum
设置一个哈希分布表使用的哈希桶数,有效值为大于0的整数,而且不要大于default_hash_table_bucket_number配置参数。缺省值为segment节点数 * 6。推荐在创建哈希分布表时显式指定该值。该属性在建表时指定,表创建以后不能修改bucketnum的值。
db1=# create table t1(a int) with (bucketnum=1) distributed by (a);
CREATE TABLE4. ORIENTATION
该参数设置数据存储模型,有效值为row(缺省值)和parquet,分别指的是面向行和列的存储格式。此选项只能与appendonly=true一起使用。
db1=# create table t1(a int) with (orientation=parquet);
ERROR: invalid option "orientation" for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (orientation=parquet,appendonly=true);
CREATE TABLEdb1=# create table t1(a int) with (orientation=column,appendonly=true);
ERROR: Column oriented tables are deprecated. Not support it any more.5. COMPRESSTYPE
该属性指定使用的压缩算法,有效值为ZLIB、SNAPPY或GZIP。缺省值ZLIB的压缩率更高但速度更慢。Parquet表仅支持SNAPPY和GZIP。该选项只能与appendonly=true一起使用。
db1=# create table t1(a int) with (compresstype=zlib);
ERROR: invalid option 'compresstype' for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (compresstype=zlib,appendonly=true);
CREATE TABLE
db1=# create table t2(a int) with (compresstype=zlib,appendonly=true,orientation=parquet);
ERROR: parquet table doesn't support compress type: 'zlib'
db1=# create table t2(a int) with (compresstype=snappy,appendonly=true,orientation=parquet);
CREATE TABLE6. COMPRESSLEVEL
有效值1-9,数值越大压缩率越高。如果不指定,缺省值为1 。该选项只对zlib和gzip有效,并且只能与appendonly=true一起使用。
db1=# create table t1(a int) with (compresstype=snappy,compresslevel=1);
ERROR: invalid option 'compresslevel' for compresstype 'snappy'.
db1=# create table t1(a int) with (compresslevel=1);
ERROR: invalid option 'compresslevel' for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (compresslevel=1,appendonly=true);
CREATE TABLE7. OIDS
缺省值为FALSE,表示不给行赋予对象标识符。建表时不要启用OIDS。首先,通常OIDS对用户应用没有用处。再者,行典型的HAWQ系统中的表都很大,如果为每行赋予一个32位的计数器,不但占用空间,而且可能给HAWQ系统的目录表造成问题。最后,每行节省4字节存储空间也能带来一定的查询性能提升。
8. FILLFACTOR
该选项控制插入数据时页存储空间的使用率,作用类似于Oracle的PCTFREE,为后续的行更新预留空间。取值范围是10到100,缺省值为100,即不为更新保留空间。HAWQ不支持UPDATE和DELETE操作,故该值保持缺省即可。该选项对parquet表无效。
db1=# create table t1(a int) with (fillfactor=100,orientation=parquet);
ERROR: invalid option "orientation" for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (fillfactor=100);
CREATE TABLE9. PAGESIZE与ROWGROUPSIZE
ROWGROUPSIZE:描述Parquet文件中row group的大小,可配置范围为 [1KB,1GB) 默认为8MB。
PAGESIZE:描述parquet文件中每一列对应的page大小,可配置范围为[1KB,1GB),默认为1MB。
这两个选项只对parquet表有效,并且只能与appendonly=true一起使用。PAGESIZE的值应该小于ROWGROUPSIZE,因为行组包含页的元信息。
db1=# create table t1(a int) with (pagesize=1024,rowgroupsize=1024,orientation=parquet);
ERROR: row group size for parquet table must be larger than pagesize. Got rowgroupsize: 1024, pagesize 1024
db1=# create table t1(a int) with (pagesize=1024,rowgroupsize=8096,orientation=parquet);
ERROR: invalid option "orientation" for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (pagesize=1024,rowgroupsize=8096,orientation=row);
ERROR: invalid option 'pagesize' for non-parquet table
db1=# create table t1(a int) with (pagesize=1024,rowgroupsize=8096,orientation=parquet,appendonly=true);
CREATE TABLE二、数据分布策略
首先需要指出的是,这里所说的数据分布策略并不直接决定数据的物理存储位置,数据块的存储位置是由HDFS决定的。这里的数据分布策略概念是从GreenPlum继承来的,存储移植到HDFS上后,数据分布决定了HDFS上数据文件的生成规则,以及在此基础上的资源分配策略。
所有的HAWQ表(除gpfdist外部表)都是分布存储在HDFS上的。HAWQ支持两种数据分布策略,随机与哈希。在创建表时,DISTRIBUTED子句声明HAWQ的数据分布策略。如果没有指定DISTRIBUTED子句,则HAWQ缺省使用随机分布策略。当使用哈希分布时,bucketnum属性设置哈希桶的数量。几何数据类型(Geometric Types)或用户定义数据类型的列不能作为HAWQ的哈希分布键列。哈希桶数影响处理查询时使用的虚拟段的数量。
缺省时,哈希分布表使用的哈希桶数由default_hash_table_bucket_number服务器配置参数的值所指定。可以在会话级或使用建表DDL语句中的bucketnum存储参数覆盖缺省值。
随机分布相对于哈希分布有一些益处。例如,集群扩容后,HAWQ的弹性查询特性,使得在操作随机分布表时能够自动使用更多的资源,而不需要重新分布数据。重新分布大表数据的资源与时间消耗都非常大。而且,随机分布表具有更好的数据本地化,这尤其表现在底层的HDFS因为某个数据节点失效而执行rebalance操作重新分布数据后。在一个大规模Hadoop集群中,增删数据节点后rebalance的情况很常见。
然而,哈希分布表可能比随机分布表快。在HAWQ的TPCH测试中,哈希分布表在很多查询上具有更好的性能。图1是HAWQ提供的一个数据分布性能对比图,其中CO表示列存储格式,AO表示行存储格式。
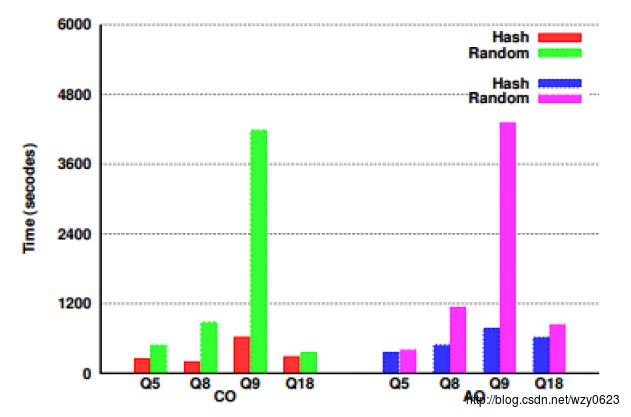
以上是关于用HAWQ轻松取代传统数据仓库 —— 存储分布的主要内容,如果未能解决你的问题,请参考以下文章