hadoop安装
Posted 阿哲小园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop安装相关的知识,希望对你有一定的参考价值。
曾经的学习笔记
1.Hadoop简介:
a) 分布式存储系统HDFS
- 分布式存储系统
- 提供了高可靠性、高扩展性和高吞吐率的数据存储服务
b) 分布式计算框架MapReduce
- 分布式计算框架
- 具有易用编程、高容错性和高扩展性等优点
2.HDFS优点:
a) 高容错性
b) 适合批处理
c) 适合大数据处理
d) 可构建在廉价机器上
3.HDFS的缺点:
a) 低延迟数据访问
b) 小文件存取
c) 并发写入、文件随机修改
4.HDFS架构:
a) NameNode(NN元数据) 保存着 HDFS 的名字空间
- 接受客户端的读写服务
- 保存metadata信息包括
- 文件owership和permissions
- 文件包含那些快
- Block保存在那个datanode
- NameNode的metadata信息在启动后加载到内存
- Metadata存储到磁盘文件名为”fsImage”
- Block位置信息不会保存到fsImage
- Edits记录对metadata的操作日志
b) SecondaryNameNode
- 不是NN的备份(但可以做备份),主要工作是帮助NN合并editslog,减少NN启动时间
- SNN执行合并时机
c) DataNode(存放数据)
5.HDFS文件权限
a) 与Linux文件权限类似,rwx,权限x对于文件忽略,对文件夹表示允许访问
b) HDFS用户认证:
- Simple:只认证用户,不验证密码
- KerBeros:认证用户名跟密码:
- 数据安全,但是速度比较慢
- 每添加一台机器,需要重置用户密码,不利于维护
6.安全模式
7.安装Hadoop:
a) 在Windows下解压hadoop-2.5.2.tar.gz
b) 查看官方文档:\\hadoop-2.5.2\\share\\doc\\hadoop\\index.html
c) 按官方文档搭建伪分布式:Single Node Setup-->Pseudo-Distributed Operation
d) 安装所需要环境yum install -y ssh rsync
e) 把hadoop-2.5.2.tar.gz上传到/usr/local/temp/
f) 解压并移动目录mv -r hadoop-2.5.2 /usr/local/hadoop
g) 修改配置环境 vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh

h) 在/usr/local/hadoop下测试命令:bin/hadoop
i) 搭建伪分布式操作;修改文件内容:
- vim/usr/local/hadoop/etc/hadoop/core-site.xml
|
<configuration> <property> <name> fs.defaultFS </ name> <value> hdfs:// localhost:9000 </ value> </ property> </ configuration> |
- vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
|
<configuration> <property> <name> dfs.replication </ name> <value> 1 </ value> </ property> </ configuration> |
j) 格式化文件系统:bin/hdfs namenode -format
k) 启动NameNode跟datanode守护程序:sbin/start-dfs.sh
8.HDFS安装:
a) 上传tar包,解压并移动到/usr/local/hadoop
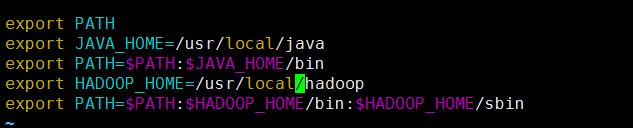
b) 配置用户环境变量:vim ~/.bash_profile,配置java,Hadoop的目录,重新加载配置
c) 进入Hadoop文件夹下修改Hadoop环境配置:vim etc/hadoop/hadoop-env.sh

d) 修改核心配置:vim etc/hadoop/core-site.xml

e) 修改hdfs配置文件:vim etc/hadoop/hdfs-site.xml
f) 配置Hadoop数据存储节点:vim etc/hadoop/sales

g) 设置免密登录:ssh
- 生成公钥:ssh-keygen
- 到~/.ssh目录下拷贝公钥到其他节点:ssh-copy-id -i id_rsa.pub root@node5
h) 拷贝hosts文件到其他所有节点:scp /etc/hosts root@node2:/etc/
i) 在node2节点中监控/etc/hosts:tail -f /etc/hosts
j) 拷贝~/.bash_profile文件到其他所有节点:
scp ~/.bash_profile root@node2:~/.bash_profile
k) 拷贝hadoop文件夹拷贝到其他节点中:
scp -r /usr/local/hadoop root@node2:/usr/local
l) 格式化HDFS: hdfs namenode -format(注意符号)必须在主节点上
m) 在主节点上启动 start-dfs.sh
测试:192.168.189.3:50070浏览器连接
编程:192.168.189.3:9000
如果启动有问题,看日志文件tail -10 /usr/local/hadoop/logs/
9.操作hdfs文件系统
a) hdfs dfs put 上传
b) hadoop-deamon.sh restart datanode重启单个节点
c) stop-dfs.sh
10.导入eclipse的Hadoop插件
11.Java控制hdfs
a) 创建项目
b) 导入jar包
以上是关于hadoop安装的主要内容,如果未能解决你的问题,请参考以下文章