如何在windows下安装hadoop
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在windows下安装hadoop相关的知识,希望对你有一定的参考价值。
1、安装Cygwin下载cygwin的setup.exe,双击运行:
选择从Internet安装:
设置安装目录:
设置安装包目录:
设置“Internet Connection”的方式,选择“Direct Connection”:
选择一个下载站点:
“下一步”之后,可能会弹出下图的“Setup Alert”对话框,直接“确定”即可
在“Select Packages”对话框中,必须保证“Net Category”下的“OpenSSL”被安装:
如果还打算在eclipse 上编译Hadoop,则还必须安装“Base Category”下的“sed”:
“Devel Category”下的subversion 建议安装:
下载并安装:
当下载完后,会自动进入到“setup”的对话框:
在上图所示的对话框中,选中“Create icon on Desktop”,以方便直接从桌面上启动
Cygwin,然后点击“完成”按钮。至此,Cgywin 已经安装完成。
2、配置环境变量
需要配置的环境变量包括PATH 和JAVA_HOME:将JDK 的bin 目录、Cygwin 的bin 目录
以及Cygwin 的usr\bin(sbin)目录都添加到PATH 环境变量中;JAVA_HOME 指向JRE 安装目录。
3、windows系统上运行hadoop集群,伪分布式模式安装步骤:
①启动cygwin,解压hadoop安装包。通过cygdrive(位于Cygwin根目录中)可以直接映射到windows下的各个逻辑磁盘分区。例如hadoop安装包放在分区D:\下,则解压的命令为$ tar -zxvf /cygdrive/d/hadoop-0.20.2.tar.gz,解压后可使用ls命令查看,如下图:
默认的解压目录为用户根目录,即D:\cygwin\home\lsq(用户帐户)。
②编辑conf/hadoop-env.sh文件,将JAVA_HOME变量设置为java的安装目录。例如java安装在目录C:\Program Files\java\jdk1.6.0_13,如果路径没空格,直接配置即可。存在空格,需将Program Files缩写成Progra_1,如下图:
③依次编辑conf目录下的core-site.xml、mapred-site.xml和hdfs-site.xml文件,如下图:
④安装配置SSH
点击桌面上的Cygwin图标,启动Cygwin,执行ssh-host-config命令,然后按下图上的选择输入:
当提示Do you want to use a different name?输入yes,这步是配置安装的sshd服务,以哪个用户登录,默认是cyg_server这个用户,这里就不事先新建cyg_server这个用户,用当前本机的超管本地用户:chenx,后续根据提示,2次输入这个账户的密码
出现Host configuration finished. Have fun! 一般安装顺利完成。如下图:
输入命令$ net start sshd,启动SSH,如下图:
注:sshd服务安装完之后,不会默认启动,如果启动报登录失败,不能启动,可在服务属性-Log On窗口手工修改,在前述的过程之中,cygwin不会校验密码是否正确,应该只是校验了2次的输入是否一致,然后再手工启动。不知道为什么,sshd服务如果选择local system的登录方式,后续会有问题,所以sshd服务最好设置成当前的登录用户。
⑤配置ssh登录
执行ssh-keygen命令生成密钥文件
输入如下命令:
cd ~/.ssh
ls -l
cat id_rsa.pub >> authorized_keys
完成上述操作后,执行exit命令先退出Cygwin窗口,如果不执行这一步操作,下面的操作可能会遇到错误。接下来,重新运行Cygwin,执行ssh localhost命令,在第一次执行ssh localhost时,会有“are you sure you want to continue connection<yes/no>?”提示,输入yes,然后回车即可。当出现下图提示,即顺利完成该步:
⑥hadoop运行
格式化namenode
打开cygwin窗口,输入如下命令:
cd hadoop-0.20.2
mkdir logs
bin/hadoop namenode –format
启动Hadoop
在Cygwin 中,进入hadoop 的bin 目录,
运行./start-all.sh 启动hadoop;
可以执行./hadoop fs -ls /命令,查看hadoop 的根目录;
可以执行jps 查看相关进程;
如下图:(如果显示和下图类似,一般hadoop安装/启动成功) 参考技术A 下载cygwin的setup.exe,双击运行:
选择从Internet安装:
设置安装目录:
设置安装包目录:
设置“Internet Connection”的方式,选择“Direct Connection”:
选择一个下载站点:
“下一步”之后,可能会弹出下图的“Setup Alert”对话框,直接“确定”即可
在“Select Packages”对话框中,必须保证“Net Category”下的“OpenSSL”被安装:
如果还打算在eclipse 上编译Hadoop,则还必须安装“Base Category”下的“sed 参考技术B 第一步:修改Ghost镜像安装分区位置。启动到Windows 7,运行GHost Explorer,打开之前备份好的Ghost镜像文件,本例为e:Ghost目录下的Sys.gho。将该镜像文件根目录下的boot.ini、ntldr、ntdetect.com这三个系统文件提取到Windows 7系统所在的C盘的根目录下。接着打开文件夹选项的查看选项卡以显示所有具有隐藏属性的系统文件,再去掉系统文件boot.ini的只读属性,并用记事本打开,将文本中字符串Partition(1)中的1替换为2(2表示.gho格式的XP系统镜像将要将被恢复到D盘,若为3,则表示E盘,依此类推),最后保存对系统文件boot.ini所做的修改即可。
第二步:添加XP菜单启动项。在Windows 7系统下,先安装配刊光盘附带的EasyBcd汉公版,运行后单击EasyBCD主界面左边的添加/删除(项目)按钮,然后单击版本右边的下拉箭头,选择Windows NT/2K/XP/2K3选项。接着在磁盘右边的文本框内输入c:,在改名右边的文本框内输入自己喜欢的文字(c处所示的早期版本的Windows)。最后分辊单击图1所示界面中的添加和保存按钮,添加一个启动XP的菜单选项。
第三步:用电脑迷光盘的WinPE光盘启动,恢复XP系统。运行WinPE系统下的无损分区软件WinPM7.0,接着右击win+r 7所在的C盘分区,选择隐藏,将该分区隐藏。再运行Ghost,将自己早已备份的XP镜像文件恢复到图2中D盘所在的分区。完成XP系统镜像的恢复操作后,启动WinPE并运行WinPm 7.0。最后再一次右击C盘分区,选择显现,显示已经隐藏的C盘分区即可。
经过以上操作,重新启动系统时,就可以看到那个很经典的双启动菜单了,选择其中的一个菜单项,就可以顺利地登录到XP或Windows7.在利用GHost镜像安装XP之前,隐藏Windows 7所在的C盘分区这一步必不可少,否则之前提前备份的Ghost版本的XP往往无法安装成功。
通过安装盘安装XP
若是之前没有XP的Ghost备份,又想在Windows 7系统下安装XP,使用XP的安装盘也行。
先将XP的安装盘放入光驱,接着执行安装XP的操作,将XP操作系统安装到C盘以外的任意一个分区。安装完毕后,暂时只能登录XP,这是由于WIndows 7引导信息被XP安装程序覆盖。大家再根据上边第2步所介绍的方法,为XP一个启动菜单即可。完成上述操作后,登录XP并运行EasyBcd,然后单击管理引导项目按钮,再勾选新出现的重新设置Windows Vista引导项目单选框并单击写入按钮即可。
在XP操作系统中运行Easybcd时,必须保证XP操作系统中已经提前安装了Microsoft .Net Framework 2.0环境。
PS:在双系统中如何删除XP系统
在XP+Windows 7双系统中删除XP也非常容易:在Windows 7系统下先格式化XP所在分区,然后显示所有具有隐藏属性的系统文件并删除C盘根目录下的Boot.ini、Ntldr、Ntdetect.com这三个系统文件,接着运行Easybcd,选中早期版本的Windows,然后单击删除和保存按钮即可恢复Windows 7单系统. 参考技术C Hadoop三种安装模式:单机模式,伪分布式,真正分布式
一 单机模式standalone
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
二 伪分布模式安装
tar xzvf hadoop-0.20.2.tar.gz
Hadoop的配置文件:
conf/hadoop-env.sh 配置JAVA_HOME
core-site.xml 配置HDFS节点名称和地址
hdfs-site.xml 配置HDFS存储目录,复制数量
mapred-site.xml 配置mapreduce的jobtracker地址
配置ssh,生成密匙,使到ssh可以免密码连接
(RSA算法,基于因数不对称加密:公钥加密私钥才能解密,私钥加密公钥才能解密)
cd /root
ssh -keygen -t rsa
cd .ssh
cp id_rsa.pub authorized_keys覆盖公钥,就能免密码连接
启动Hadoop bin/start-all.sh
停止Hadoop bin/stop-all.sh
三 完全分布式模式
1. 配置etc/hosts文件,使主机名解析为IP 或者使用DNS服务解析主机名
2. 建立hadoop运行用户: useradd grid>passwd grid
3. 配置ssh密码连入: 每个节点用grid登录,进入主工作目录,ssh -keygen -t rsa生产公钥,然后将每个节点的公钥复制到同一个文件中,再将这个包含所有节点公钥的文件复制到每个节点authorized_keys目录,这个每个节点之间彼此可以免密码连接
4. 下载并解压hadoop安装包
5. 配置namenode,修改site文件
6. 配置hadoop-env.sh
7. 配置masters和slaves文件
8. 向各个节点复制hadoop
9. 格式化namenode
10.启动hadoop
11.用jps检验各后台进程是否成功启动。
Windows 下 Spark+Hadoop+Scala 安装
整体流程可参考,但文中的版本较低
Spark学习笔记--Spark在Windows下的环境搭建 - 法号阿兴 - 博客园 (cnblogs.com) https://www.cnblogs.com/xuliangxing/p/7279662.html首先需要对应好 三者的版本,本文安装的版本如下
https://www.cnblogs.com/xuliangxing/p/7279662.html首先需要对应好 三者的版本,本文安装的版本如下
Spark
版本:spark-3.1.2-bin-hadoop3.2.tgz
链接:Apache Downloadshttps://www.apache.org/dyn/closer.lua/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz原因:尝试安装3.2.0,发现spark-shell启动后会报错,可参考:Spark安装问题:ERROR SparkContext: Error initializing SparkContext. java.lang.reflect.InvocationTargetException - codedogzlc - 博客园 (cnblogs.com)https://www.cnblogs.com/codedogzlc/p/15432124.html
Hadoop
版本:hadoop-3.2.0.tar.gz
原因:与 Spark 版本后匹配的 Hadoop版本一致
1、hadoop单独启动时招不到JAVA_HOME,参考
(472条消息) Hadoop 找不到 JAVA_HOME 环境变量无法启动问题解决_z69183787的专栏-CSDN博客https://blog.csdn.net/z69183787/article/details/1217921122、其中 Windows 中需要安装 winutils.exe文件,版本需与hadoop版本一一对应,可参考
github下载:
(471条消息) Hadoop3.2.1、Hadoop3.2.0还有之前的版本的winutils.exe和hadoop.dll_九天安属的博客-CSDN博客_hadoop3.2.2 winutilshttps://blog.csdn.net/qq_39238947/article/details/105382308hadoop本机运行 解决winutils.exe的问题 - 我的肉夹馍啊 - 博客园 (cnblogs.com)https://www.cnblogs.com/roujiamo/p/10053674.html
Scala
版本:2.12.0
原因:mvn仓库中会告知对应 Spark 版本 需要安装的 Scala 版本
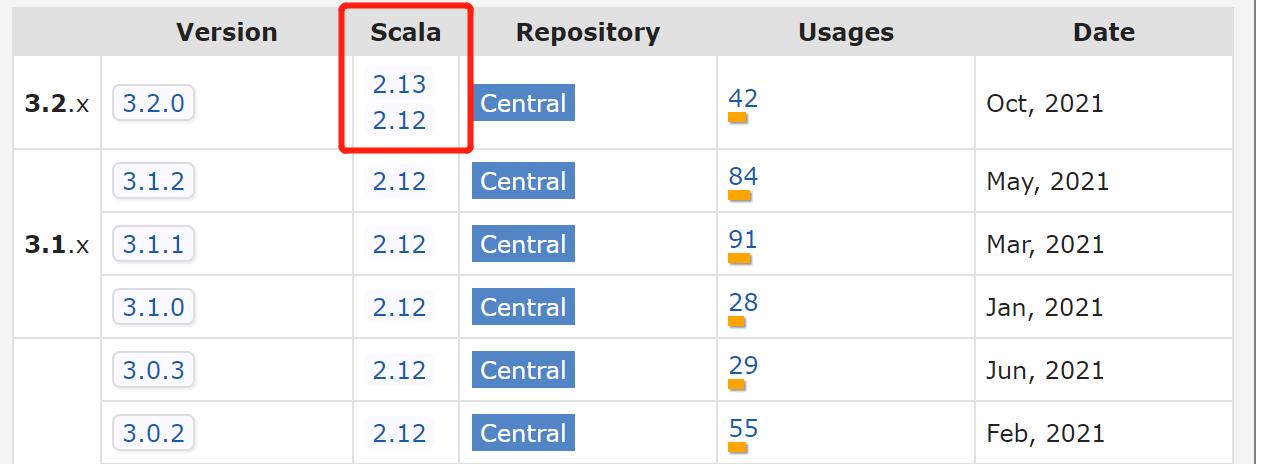
实战
运行example项目,单机下命令如下:
spark-submit --class org.apache.spark.examples.JavaSparkPi --master local[*] C:\\Users\\zhoushun\\Desktop\\Spark\\examples\\jars\\spark-examples_2.12-3.1.2.jar
以上是关于如何在windows下安装hadoop的主要内容,如果未能解决你的问题,请参考以下文章
Ambari方式下安装的Hadoop,请问如何重启Hadoop