在线阅读网站|基于Springboot+Vue开发实现小说阅读网站
Posted 编程指南针
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在线阅读网站|基于Springboot+Vue开发实现小说阅读网站相关的知识,希望对你有一定的参考价值。
作者主页:编程指南针
作者简介:Java领域优质创作者、CSDN博客专家 、掘金特邀作者、多年架构师设计经验、腾讯课堂常驻讲师
主要内容:Java项目、毕业设计、简历模板、学习资料、面试题库、技术互助
收藏点赞不迷路 关注作者有好处
文末获取源码
项目编号:BS-PT-086
前言:
随着互联网的到来,人们对网络的使用不单单是停留在简单的浏览网页,更多的是得寻找精神上的需求,在这种情况下,人们阅读名著的方式也逐渐发生了改变。而且随着现在人们的工作节奏的加快,人们整块时间减少,碎片化时间增多。在信息社会链接下,我们从互联网接收更多的信息内容。通过开发新颖的名著阅读网站,我们可以实现书籍的信息传播,让用户只在有网络的情况下就可以享受书籍带来的丰富内容。今天,阅读名著也是大量互联网用户的爱好。名著内容多样,可以满足用户对不同情节的追求,并根据用户的喜好选择内容。随之,数字阅读行业热潮到来,渐渐名著网站出现在人们的视线中。
传统的小说网站的特点,前台页面过于复杂以及很多与阅读小说无关的广告弹窗。导致用户点击想看的小说却常常点击到广告,充斥着许多与小说主题、小说内容无关的元素。本身此小说网站就是为了让用户在碎片化的时间里阅读,而现在大多数的网站中观看小说都需要繁琐的注册账号以及观看广告解锁下一章内容。导致违背了小说网站的快捷性和快速获取阅读内容的初衷。
本名著阅读网站的特点,既包含了小说网站的多样性和丰富性,而且剔除了无关阅读的弹窗和繁琐的验证注册等麻烦的流程。对于用户想快速阅读自己想看的内容,只需要利用游客的身份登录即可快速看到名著内容。且本网站包含了名著上传的功能,让用户不仅可以自由阅读的情况下,还可以化身为作者上传自己编写的名著。本网站还包含了分类和搜索功能,可以让用户快捷的找到自己想阅读的名著。假如是不经常在网上看书的游客用户也没有关系,本网站包含热门名著的排行榜,而排行版是根据名著的收藏人数数量实时变化的,让用户不用麻烦的找书本,就可以阅读到当下最受欢迎的名著读本。
一,项目简介
在线名著网站主要给用户提供多种类型的名著进行阅读,用户可以根据自己的喜好,自行根据名著分类去查找自己喜欢阅读的书籍。同时还具有成为作者的机会,用户可以申请成为作者进行名著的编写。还可以根据名著章节的阅读量来获取该网站的虚拟币。本网站包含前后端功能,用户使用前台来阅读书籍,以及书籍的编写。后端管理员可以管理用户人员,审核名著,审核作者,提现审核,广告管理以及名著管理。
登录模块:用户的登录注册可以使用手机号或者邮箱号,来获取验证码,进行账号的登录注册验证。退出登录。
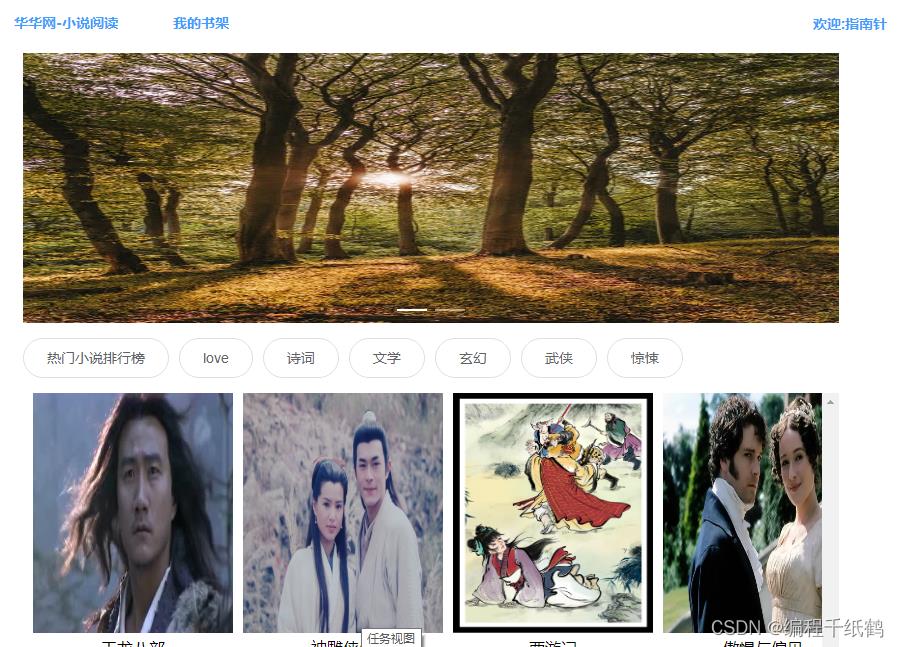
名著阅读模块:用户可以使用分类和搜索框的功能快速的找到自己想阅读的书本,根据名著的收藏量来查看热门名著的排行榜进行阅读。
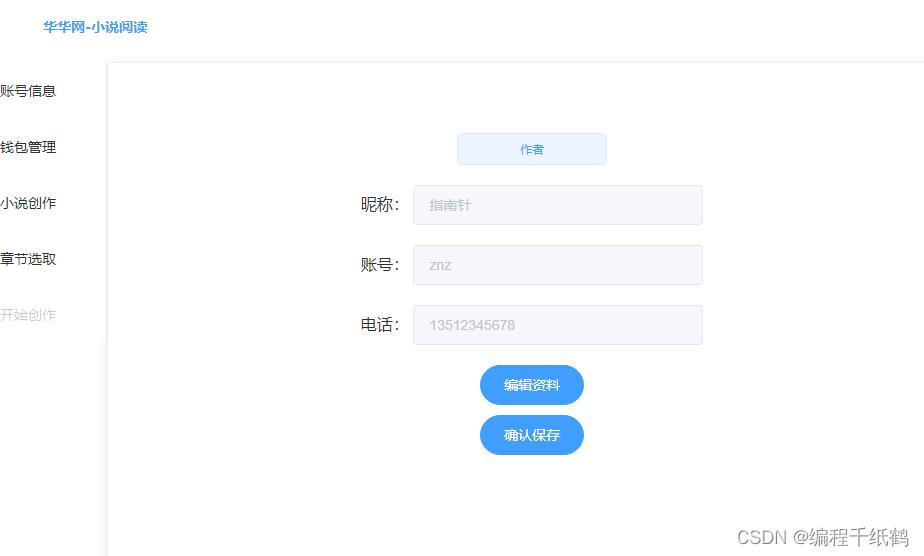
个人中心模块:有用户个人信息的增删改查,以及用户到作者身份的转变。和钱包的管理,作者可以根据自己名著章节的点击量获取网站的虚拟币、有查看余额、提现的功能。
名著新增模块:作者身份可以编写名著,可以自定义名著的名字,和投放的名著分类。可以编写章节在添加相应的内容进行发布。
名著审核模块:在作者完成作品进行发布之后,后台管理员需要进行审核,审核通过才可以在前台页面查看名著的内容。
作者审核:用户申请成为作者后,后台管理员需要进行审核,审核通过用户才可以转变成作者的身份。
提现管理:作者提现金额后,需要后台审核通过,金额才会提现成功。在未提现成功之前,提现的金额部分都会处于冻结状态。直到通过提现审核才恢复。
广告管理:对于主页面的轮播图中的广告内容进行增删改查操作。
用户管理:对用户信息的增删改查。
名著管理:对名著的删改查。
二,环境介绍
语言环境:Java: jdk1.8
数据库:mysql: mysql5.7
应用服务器:Tomcat: tomcat8.5.31
开发工具:IDEA或eclipse
后台开发:Springboot+Mybatis
前台开发:Vue+ElementUI
三,系统展示
系统首页
详情信息

在线阅读


个人中心
后台管理
小说审核

作者审核

提现审核

广告管理

用户管理

小说管理

评论管理

分类管理

四,核心代码展示
package com.hua.controller;
import ch.qos.logback.core.joran.util.beans.BeanUtil;
import cn.hutool.core.util.StrUtil;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.hua.handler.Result;
import com.hua.mapper.TypeMapper;
import com.hua.mapper.UserMapper;
import com.hua.pojo.*;
import com.hua.service.NovelService;
import com.hua.service.TypeService;
import com.hua.service.UserService;
import com.hua.service.impl.AuthorToexamineServiceImpl;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.servlet.ModelAndView;
import javax.annotation.Resource;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
@RestController
//@Controller
@RequestMapping("/novel")
//@ConditionalOnMissingBean(AuthorToexamineServiceImpl.class) //当缺失这个AuthorToexamineServiceImpl的时候,条件成立 ->NovelController ->bean
//@Conditional mybatis plus springdatasource
public class NovelController
@Resource
private NovelService novelService;
@Resource
private UserService userService;
@Autowired
private TypeMapper typeMapper;
@Autowired
private UserMapper userMapper;
/**
* 条件分页查询Novel
* @param pageNum
* @param pageSize
* @param search
* @return
*/
@GetMapping
/**
* @RequestParam用于将请求参数区数据映射到功能处理方法的参数上。defaultValue:默认值,表示如果请求中没有同名参数时的默认值
*
*/
@ResponseBody
public Result<?> NovelFindPage(@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize,
@RequestParam(defaultValue = "") String search)
//mybatis-plus中的构造器,创建一个构造器
LambdaQueryWrapper<Novel> wrapper=new LambdaQueryWrapper<Novel>();
//StuUtil工具类内置了很多方法,isNotBlamk判断字符串是否为空
// if (StrUtil.isNotBlank(search))
//where "novelName" like "123" limit 2,5 1
wrapper.like(StrUtil.isNotBlank(search),Novel::getNovelName,search);
//
//TODO
Page<NovelVO> resPage = new Page<>(pageNum,pageSize);
//limit
Page<Novel> page = novelService.page(new Page<>(pageNum, pageSize), wrapper);
//DO=>VO
BeanUtils.copyProperties(page,resPage,"records");
//TODO 把DO records也给赋值给VO
List<Novel> records = page.getRecords();
// records.stream().map()
List<NovelVO> list = records.stream().map((item)->
NovelVO novelVO = new NovelVO();
BeanUtils.copyProperties(item,novelVO);
//根据分类id查询分类名称
Type type = typeMapper.selectById(novelVO.getTypeId());
novelVO.setTypeName(type.getTypeName());
User user = userMapper.selectById(novelVO.getUserId());
novelVO.setNickName(user.getNickName());
return novelVO;
).collect(Collectors.toList());
resPage.setRecords(list);
resPage.setTotal(page.getTotal());
return Result.success(resPage);
@DeleteMapping
//Delete为删除,removeByIds为批量删除
public Result<?> NovelDelete(@RequestBody Set<String> ids)
novelService.removeByIds(ids);
return Result.success();
//新增一条小说的数据
@PostMapping("addNovel")
public Result<?> addNovel(@RequestBody Novel novel)
novelService.save(novel);
return Result.success();
//根据用户id查询多行数据
@PostMapping("/selectNovel/userId")
public Result<?> selectUser(@PathVariable String userId)
LambdaQueryWrapper<Novel> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(Novel::getUserId,userId);
List<Novel> list = novelService.list(wrapper);
return Result.success(list);
//根据用户id查询多行数据,点击量全部相加
@PostMapping("/selectNovelDjl/userId")
public Result<?> selectNovelDjl(@PathVariable String userId)
LambdaQueryWrapper<Novel> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(Novel::getUserId,userId);
List<Novel> list = novelService.list(wrapper);
Integer zongDjl=0;
for (Novel novel : list)
Integer novelHits = novel.getNovelHits();
zongDjl=novelHits+zongDjl;
return Result.success(zongDjl);
//根据分类id查询数据
@PostMapping("/selectImgName/typeId")
public Result<?> selectImgName(@PathVariable String typeId)
LambdaQueryWrapper<Novel> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(Novel::getTypeId,typeId);
List<Novel> list = novelService.list(wrapper);
return Result.success(list);
//根据小说id查询内容
@PostMapping("/selectTitle/novelId")
public Result<?> selectNovel(@PathVariable String novelId)
Novel byId = novelService.getById(novelId);
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User::getUserId,byId.getUserId());
String nickName = userService.getOne(wrapper).getNickName();
byId.setUserId(nickName);
return Result.success(byId);
根据小说id查询内容,(点击量加1)
@PostMapping("/selectJiaNovelHits/novelId")
public Result<?> selectJiaNovelHits(@PathVariable String novelId)
Novel byId = novelService.getById(novelId);
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User::getUserId,byId.getUserId());
// 设置点击量加1
int novelHits = byId.getNovelHits();
novelHits++;
byId.setNovelHits(novelHits);
novelService.updateById(byId);
String nickName = userService.getOne(wrapper).getNickName();
byId.setUserId(nickName);
return Result.success(byId);
//查询出点击量最高的6位
@PostMapping("/selectMaxHits")
public Result<?> selectMaxHits()
LambdaQueryWrapper<Novel> wrapper = new LambdaQueryWrapper<>();
wrapper.orderByDesc(Novel::getNovelHits);
List<Novel> list = novelService.list(wrapper );
return Result.success( list.subList(0,6));
@PutMapping
//put为更新
public Result<?> novelUpdate(@RequestBody Novel novel)
novelService.updateById(novel);
return Result.success(novel);
package com.hua.controller;
import cn.hutool.core.util.StrUtil;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.hua.handler.Result;
import com.hua.pojo.Novel;
import com.hua.service.NovelService;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
import java.util.Set;
@RestController
@RequestMapping("/novelToexamine")
public class NovelToexamineController
@Resource
private NovelService novelToexamineService;
@GetMapping
//Get为查询
public Result<?> novelToexamineFindPage(@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize,
@RequestParam(defaultValue = "") String search)
LambdaQueryWrapper<Novel> wrapper= Wrappers.<Novel>lambdaQuery();
if (StrUtil.isNotBlank(search))
wrapper.like(Novel::getNovelId,search);
Page<Novel> page = novelToexamineService.page(new Page<>(pageNum, pageSize), wrapper);
return Result.success(page);
@PutMapping
//put为更新
public Result<?> novelToexamineUpdate(@RequestBody Novel novelToexamine )
novelToexamineService.updateById(novelToexamine);
return Result.success();
@DeleteMapping
//Delete为删除,removeByIds为批量删除
public Result<?>WithdrawalDelete(@RequestBody Set<String> ids)
novelToexamineService.removeByIds(ids);
return Result.success();
package com.hua.controller;
import cn.hutool.core.util.StrUtil;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.hua.handler.Result;
import com.hua.pojo.User;
import com.hua.service.UserService;
import com.hua.service.WalletService;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
import java.util.List;
import java.util.Set;
@RestController
@RequestMapping("/user")
public class UserController
@Resource
private UserService userService;
@Resource
private WalletService walletService;
@PostMapping
//post为新增
public Result<?> usersave(@RequestBody User user)
//拿一个User类型的查询条件 where
LambdaQueryWrapper<User> usersLambdaQueryWrapper = new LambdaQueryWrapper<>();
//如何查询出数据库中没有该usernam则成功注册,否则用户名重复
User serviceOne = userService.getOne(usersLambdaQueryWrapper.eq(User::getUserName,user.getUserName()));
if (serviceOne == null)
userService.save(user);
return Result.success(user.getUserId());
return Result.error("401","用户名存在请重新设置!");
@PutMapping
//put为更新
public Result<?> userUpdate(@RequestBody User user)
userService.updateById(user);
return Result.success(user);
@GetMapping
//Get为查询
public Result<?> userFindPage(@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize,
@RequestParam(defaultValue = "") String search)
LambdaQueryWrapper<User> wrapper= Wrappers.<User>lambdaQuery();
if (StrUtil.isNotBlank(search))
wrapper.like(User::getNickName,search);
Page<User> page = userService.page(new Page<>(pageNum, pageSize), wrapper);
//您可以使用 getRecords 方法来获取 API 请求中指定的所有用户数据。records里面保存了User表中的所有数据
List<User> records = page.getRecords();
//循环查询
records.forEach(item ->
/**
* selectBanlance的作用是查询出wallet表中的walletId和user表中的的walletId,
* 传入(user表中的walletId)item.getWalletId()
* Long along返回的是wallet表中的余额值
*/
Long aLong = walletService.selectBalance(item.getWalletId());
//由于要使用balance(余额)来替换之前表格中的walletId所以要对aLong进行数据类型转换
item.setWalletId(String.valueOf(aLong));
);
return Result.success(page);
@DeleteMapping
//Delete为删除,removeByIds为批量删除
public Result<?> userDelete(@RequestBody Set<String> ids)
userService.removeByIds(ids);
return Result.success();
//根据id查询单行数据
@PostMapping("/selectUser/userId")
public Result<?> selectUser(@PathVariable String userId)
User byId = userService.getById(userId);
return Result.success(byId);
//查询用户表中所有数据
@GetMapping("/selectUser")
public Result<?> selectUser()
List<User> list = userService.list();
return Result.success(list);
五,项目总结
1.技术要求
在线名著网站系统采用前后端分离的架构思想,极大的简化了系统的复杂结构,同时前端和后端的分离部署,优化了系统的系统,降低前端和后端之间的耦合性,也为后续的二次开发提供良好的开发环境。
通过观察市场类似的系统以及目前流行的技术,同时参考与开源平台上的开源项目,本系统模块设计的编程语言设计采用java作为基础语言,前端基于VUE实现,后端基于SpringBoot的基础上采用SSM框架集实现。
(1)技术实施方案
通过调研,了解在线名著网站系统的内容及其特点,存在和需要解决的主要问题。确定在线名著网站系统的建设目标、意义及功能需求,分析整个系统架构的组成、设计特点、安全特性。对在线名著网站系统的模块进行分析,用UML图给出相应模块的用例图。然后从简到繁一步步完成功能点,首先编写最基础的登陆注册以及退出登录功能,之后完善前端页面。根据前端功能模块一个个完善功能,在实现后台对用户以及名著的管理。以及前后端数据的交互。
(2)系统测试方案
对系统的实验分为三个阶段。第一阶段对单个功能模块进行实验,确认单个功能模块功能完善,功能点可以正常使用。第二阶段对有交互的功能模块进行两两一对的联动实验,确认多个模块之间数据交互、运行正常。第三阶段对整个系统进行细致的实验与测试,在系统搭建完成之后,模拟正常运营的情况下系统是否存在问题与隐患。
2.工作要求
(1)操作可行性:本系统操作简单,设计了良好的用户交换界面与用户引导,操作简洁明了。操作上可行。
(2)技术可行性:本系统使用Java基础语言和成熟的SSM框架集开发,资料文档齐全。并且系统在市场上已经有成熟的同类型系统案例。技术上可行。
(3)经济可行性:本系统需要的是名著的内容资源,名著的初始内容可以引用我国古代的名著内容,这样就不存在内容侵权。以及后期名著内容是用户自主编写就更加不存在搬运侵权的问题了,还可以通过获取点击量来投放广告达到盈利的效果,因此经济上可行。
以上是关于在线阅读网站|基于Springboot+Vue开发实现小说阅读网站的主要内容,如果未能解决你的问题,请参考以下文章
在线阅读网站|基于Springboot+Vue开发实现小说阅读网站
Java项目-基于Springboot+Vue实现在线音乐网站
Java+MySQL 基于Springboot的在线点餐外卖平台网站#毕业设计