内核解读之内存管理CPU体系架构UMA和NUMA
Posted 奇妙之二进制
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内核解读之内存管理CPU体系架构UMA和NUMA相关的知识,希望对你有一定的参考价值。
文章目录
内存和cpu有着密不可分的联系,学习内存管理,先了解下cpu的架构。
1. SMP(UMA) 体系架构
CPU 计算平台体系架构分为 SMP 体系架构和 NUMA 体系架构等,下图为 SMP 体系架构:
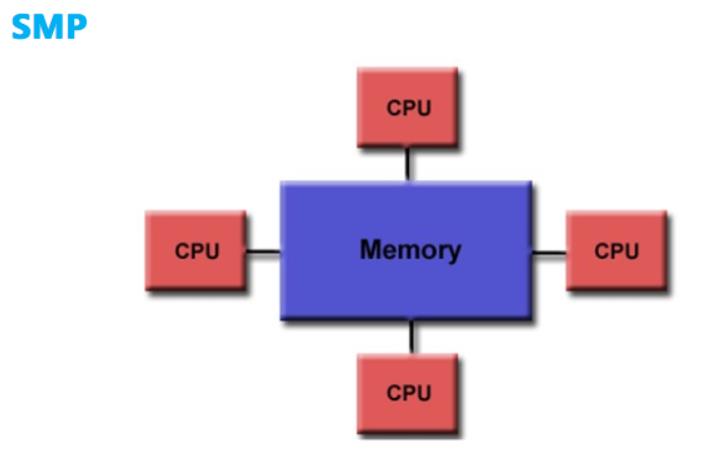
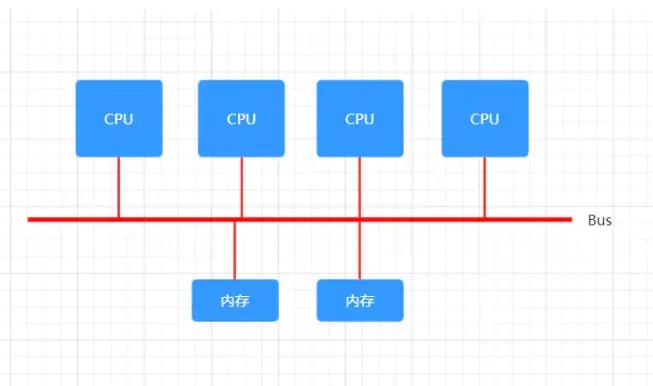
SMP(Sysmmetric Multi-Processor System,对称多处理器系统),它由多个具有对称关系的处理器组成。所谓对称,即处理器之间没有主从之分,。SMP 架构使得一台计算机不再由单个 CPU 组成。
SMP 的结构特征就是「多处理器共享一个集中式存储器」,每个处理器访问存储器所需的时间一致,工作负载能够均匀的分配到所有可用处理器上,极大地提高了整个系统的数据处理能力。但是,如果多个处理器同时请求访问共享资源时,就会引发资源竞争,需要软硬件实现加锁机制来解决这个问题。所以,SMP 又称为 UMA(Uniform Memory Access,一致性存储器访问),其中,一致性指的就是在任意时刻,多个处理器只能为内存的每个数据保存或共享一个唯一的数值。
因此,这样的架构设计无法拥有良好的处理器数量扩展性,因为共享内存的资源竞态总是存在的,处理器利用率最好的情况只能停留在 2 到 4 颗。
2. NUMA 体系架构
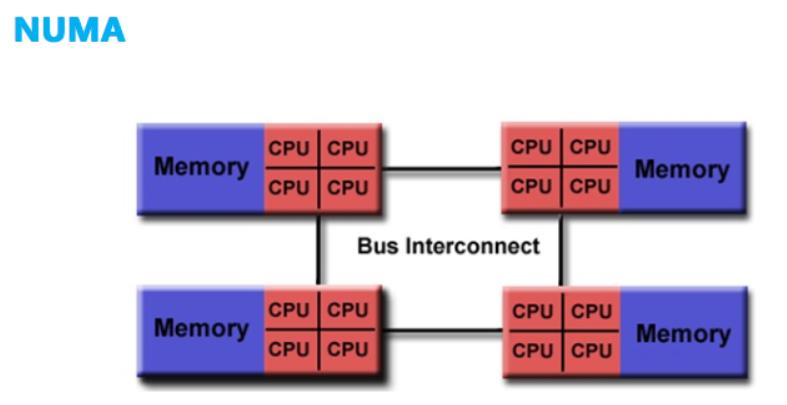
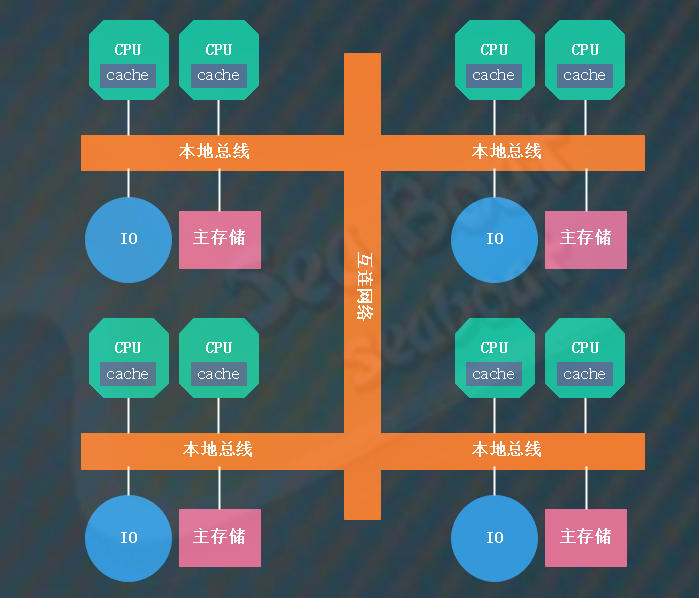
计算机系统中,处理器的处理速度要远快于主存的速度,所以限制计算机计算性能的瓶颈在存储器带宽上。SMP 架构因为多处理器访问存储器的竞争,所以处理器可能会时刻对数据访问感到饥饿。
NUMA(Non-Uniform Memory Access,非一致性存储器访问)架构优化了 SMP 架构扩展性差以及存储器带宽窄的问题。
从上图可以看出,主要的区别在于 NUMA 架构采用了分布式存储器,将处理器和存储器划分为不同的节点(NUMA Node),每个节点都包含了若干的处理器与内存资源。多节点的设计有效提高了存储器的带宽和处理器的扩展性。
另一方面,NUMA 节点的处理器可以访问到整体存储器。按照节点内外,内存被分为节点内部的本地内存以及节点外部的远程内存。当处理器访问本地内存时,走的是内部总线,当处理器访问远程内存时,走的是主板上的 QPI 互联模块。访问前者的速度要远快于后者,NUMA(非一致性存储器访问)因此而得名。
3. NUMA 结构基本概念
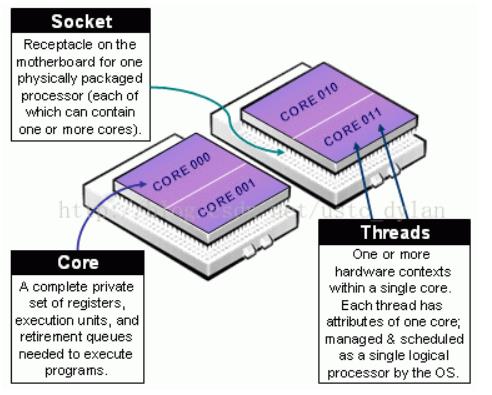
- Socket:表示一颗物理 CPU 的封装(物理 CPU 插槽),简称插槽。为了避免将逻辑处理器和物理处理器混淆,Intel 将物理处理器称为插槽。
- Core: 物理 CPU 封装内的独立的一组程序执行的硬件单元,比如寄存器,计算单元等。
- Thread: 使用超线程技术虚拟出来的逻辑 Core,需要 CPU 支持。为了便于区分,逻辑 Core 一般被写作 Processor。在具有 Intel 超线程技术的处理器上,每个内核可以具有两个逻辑处理器,这两个逻辑处理器共享大多数内核资源(如内存缓存和功能单元)。此类逻辑处理器通常称为 Thread 。
- Node: 包含有若干个物理 CPU 的组。
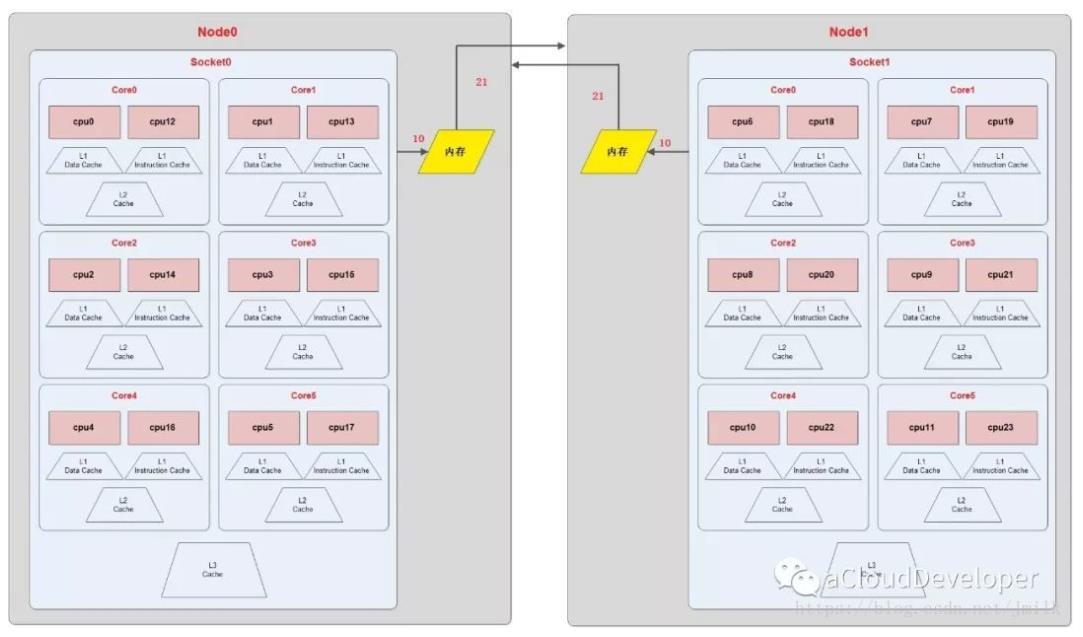
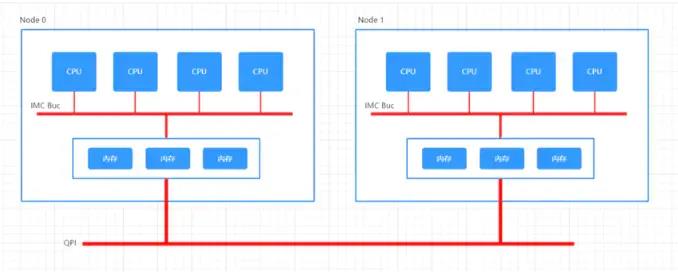
上图的 NUMA Topology 有 2 个 NUMA node,每个 node 有 1 个 socket,即 pCPU, 每个 pCPU 有 6 个 core,1 个 core 有 2 个 Processor,则共有逻辑 cpu processor 24 个。
在 LINUX 命令行中执行 lscpu 即可看到机器的 NUMA 拓扑结构:
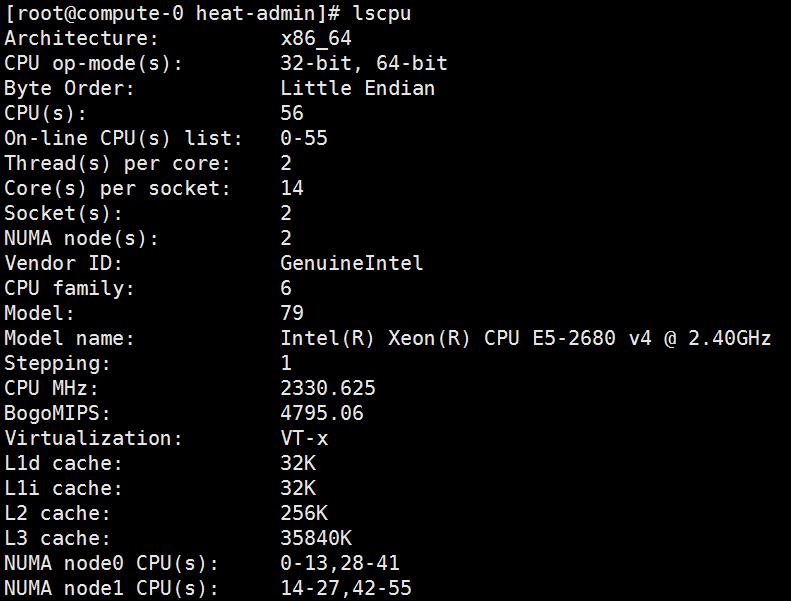
如上图所示,机器有 2 个 node 分配到 2 个 socket 上,每个 socket 有 14 个 core,每个 core 有 2 个 processor, 则共有 56 个 cpu processor。同时,从上图也可看出 NUMA node 0 上的 cpu 分布为 0-13,28-41,而 node 1 上的分布为 14-27, 42-55。
NUMA node 处理器访问本地内存的速度要快于访问远端内存的速度。访问速度与 node 的距离有关系,node 间的距离称为 node distance。
以上是关于内核解读之内存管理CPU体系架构UMA和NUMA的主要内容,如果未能解决你的问题,请参考以下文章
Linux 内核 内存管理物理内存组织结构 ① ( 多处理器体系结构 | SMP/UMA 对称多处理器结构 | NUMA 非一致内存访问结构 )