内核解读之内存管理内存管理三级架构之内存结点node
Posted 奇妙之二进制
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内核解读之内存管理内存管理三级架构之内存结点node相关的知识,希望对你有一定的参考价值。
文章目录
0、概述
结合NUMA的架构,Linux抽象出了三级内存管理架构:内存节点node、内存区域zone和物理页框page。
在NUMA模型中,每个CPU都有自己的本地内存节点(memory node),而且还可以通过QPI总线访问其他CPU下挂的内存节点,只是访问本地内存要比访问其他CPU下的内存的速度高许多,一般经过一次QPI要增加30%的访问时延。
内存节点node是为了解决多处理器内存访问竞争的问题,而内存区域zone是为了解决32位系统内核只有1G的虚拟地址空间,无法管理大于1G的物理内存这个问题,zone按照用途划分成几种类型,比如低端内存区,高端内存区,DMA内存区等。
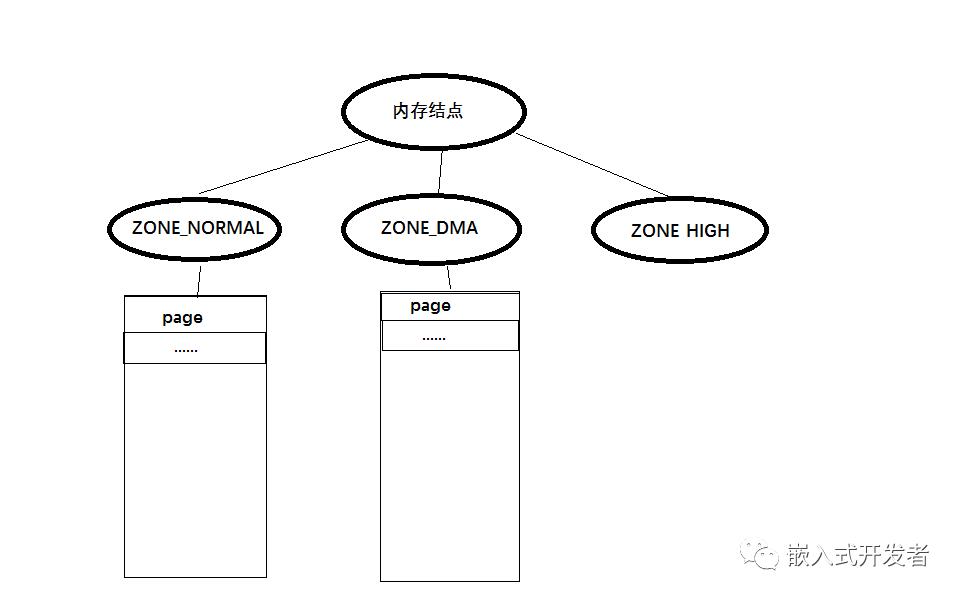
图 内核内存管理三级架构
1、内存节点node
NUMA结构下, 每个处理器与一个本地内存直接相连, 而不同处理器之间则通过总线进行进一步的连接。linux内核把物理内存按照CPU节点划分为不同的node, 每个node作为某个cpu结点的本地内存, 而作为其他CPU节点的远程内存, 而UMA结构下, 则任务系统中只存在一个内存node, 这样对于UMA结构来说, 内核把内存当成只有一个内存node节点的伪NUMA。因此,NUMA和UMA的管理方式便一致了。
Linux内核中使用数据结构pg_data_t来表示内存节点node,我们把它叫做结点描述符。如常用的ARM架构为UMA架构。对于UMA架构只有一个内存节点,对于NUMA架构有多个内存节点。
在numa.h中有如下定义:
#ifdef CONFIG_NODES_SHIFT
#define NODES_SHIFT CONFIG_NODES_SHIFT
#else
#define NODES_SHIFT 0
#endif
#define MAX_NUMNODES (1 << NODES_SHIFT)
CONFIG_NODES_SHIFT是由用户配置的内存节点的数目。可以看到,对于UMA架构,MAX_NUMNODES等于1。
include/linux/mmzone.h:
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data
/*
* node_zones contains just the zones for THIS node. Not all of the
* zones may be populated, but it is the full list. It is referenced by
* this node's node_zonelists as well as other node's node_zonelists.
*/
struct zone node_zones[MAX_NR_ZONES];
/* node_zones是一个数组,包含节点中各内存区(ZONE_DMA, ZONE_DMA32, ZONE_NORMAL...)的描述符。*/
/*
* node_zonelists contains references to all zones in all nodes.
* Generally the first zones will be references to this node's
* node_zones.
*/
struct zonelist node_zonelists[MAX_ZONELISTS]; /* 指定了节点的备用zone列表 */
/*
struct zonelist
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
该结构包含了类型为 struct zoneref 的一个备用列表,由于该备用列表必须包括所有结点的所有内存域,因此由 MAX_NUMNODES * MAX_NZ_ZONES 项组成,外加一个用于标记列表结束的空指针。
/* Maximum number of zones on a zonelist */
#define MAX_ZONES_PER_ZONELIST (MAX_NUMNODES * MAX_NR_ZONES)
/*
* This struct contains information about a zone in a zonelist. It is stored
* here to avoid dereferences into large structures and lookups of tables
*/
struct zoneref
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
;
*/
int nr_zones; /* number of populated zones in this node */ /*指示了节点中zone的数目*/
#ifdef CONFIG_FLATMEM /* means !SPARSEMEM */
struct page *node_mem_map; /* 平铺式内存模式下,物理page数组,linux为每个物理页分配了一个struct page的管理结构体,并形成了一个结构体数组,node_mem_map即为数组的指针;pfn_to_page和page_to_pfn都借助该数组实 */
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif
#if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT)
/*
* Must be held any time you expect node_start_pfn,
* node_present_pages, node_spanned_pages or nr_zones to stay constant.
* Also synchronizes pgdat->first_deferred_pfn during deferred page
* init.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG
* or CONFIG_DEFERRED_STRUCT_PAGE_INIT.
*
* Nests above zone->lock and zone->span_seqlock
*/
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn; /* 节点第一页帧逻辑编号 */
unsigned long node_present_pages; /* total number of physical pages */ /* 节点中物理页帧总数目 */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */ /* 按照平铺计算的节点物理页帧总数目。由于空洞的存在可能不等于node_present_pages,应该是大于等于node_present_pages。*/
int node_id; /*结点id*/
wait_queue_head_t kswapd_wait; /* kswapd页换出守护进程使用的等待队列 */
wait_queue_head_t pfmemalloc_wait;
/* workqueues for throttling reclaim for different reasons. */
wait_queue_head_t reclaim_wait[NR_VMSCAN_THROTTLE];
atomic_t nr_writeback_throttled;/* nr of writeback-throttled tasks */
unsigned long nr_reclaim_start; /* nr pages written while throttled
* when throttling started. */
#ifdef CONFIG_MEMORY_HOTPLUG
struct mutex kswapd_lock;
#endif
struct task_struct *kswapd; /* Protected by kswapd_lock */ /* 指针指向kswapd内核线程的进程描述符 */
/* 每个结点都有一个内核进程kswapd,它的作用就是将进程或内核持有的,但是不常用的页交换到磁盘上,以腾出更多可用内存。不信你可以ps看一下。*/
int kswapd_order; /* 需要释放的区域的长度,以页阶为单位 */
enum zone_type kswapd_highest_zoneidx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION
int kcompactd_max_order;
enum zone_type kcompactd_highest_zoneidx;
wait_queue_head_t kcompactd_wait;
struct task_struct *kcompactd;
bool proactive_compact_trigger;
#endif
/*
* This is a per-node reserve of pages that are not available
* to userspace allocations.
*/
unsigned long totalreserve_pages;
/* 结点page回收相关 */
#ifdef CONFIG_NUMA
/*
* node reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */
CACHELINE_PADDING(_pad1_);
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* If memory initialisation on large machines is deferred then this
* is the first PFN that needs to be initialised.
*/
unsigned long first_deferred_pfn;
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
struct deferred_split deferred_split_queue;
#endif
#ifdef CONFIG_NUMA_BALANCING
/* start time in ms of current promote rate limit period */
unsigned int nbp_rl_start;
/* number of promote candidate pages at start time of current rate limit period */
unsigned long nbp_rl_nr_cand;
/* promote threshold in ms */
unsigned int nbp_threshold;
/* start time in ms of current promote threshold adjustment period */
unsigned int nbp_th_start;
/*
* number of promote candidate pages at stat time of current promote
* threshold adjustment period
*/
unsigned long nbp_th_nr_cand;
#endif
/* Fields commonly accessed by the page reclaim scanner */
/*
* NOTE: THIS IS UNUSED IF MEMCG IS ENABLED.
*
* Use mem_cgroup_lruvec() to look up lruvecs.
*/
struct lruvec __lruvec;
unsigned long flags; /* 结点标记 */
#ifdef CONFIG_LRU_GEN
/* kswap mm walk data */
struct lru_gen_mm_walk mm_walk;
#endif
CACHELINE_PADDING(_pad2_);
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
#ifdef CONFIG_NUMA
struct memory_tier __rcu *memtier;
#endif
pg_data_t;
在UMA结构的机器中, 只有一个node结点contig_page_data, 此时NODE_DATA直接指向了全局的contig_page_data, 而与node的编号nid无关,其中全局唯一的内存node结点contig_page_data定义在include/linux/mmzone.h:。
#ifndef CONFIG_NUMA
extern struct pglist_data contig_page_data;
static inline struct pglist_data *NODE_DATA(int nid)
return &contig_page_data;
#else /* CONFIG_NUMA */
#include <asm/mmzone.h>
#endif /* !CONFIG_NUMA */
定义了NUMA时,NUMA和平台相关,截取arm64的定义如下:
arch/arm64/include/asm/mmzone.h:
/* SPDX-License-Identifier: GPL-2.0 */
#ifndef __ASM_MMZONE_H
#define __ASM_MMZONE_H
#ifdef CONFIG_NUMA
#include <asm/numa.h>
extern struct pglist_data *node_data[];
#define NODE_DATA(nid) (node_data[(nid)])
#endif /* CONFIG_NUMA */
#endif /* __ASM_MMZONE_H */
以上是关于内核解读之内存管理内存管理三级架构之内存结点node的主要内容,如果未能解决你的问题,请参考以下文章