机器学习算法笔记7. 基于信息论的网络
Posted tostq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法笔记7. 基于信息论的网络相关的知识,希望对你有一定的参考价值。
【机器学习算法笔记】7. 基于信息论的网络
根据最大互信息原则作为网络的最优化目标函数。
7.1 最大互信息原则(相关)
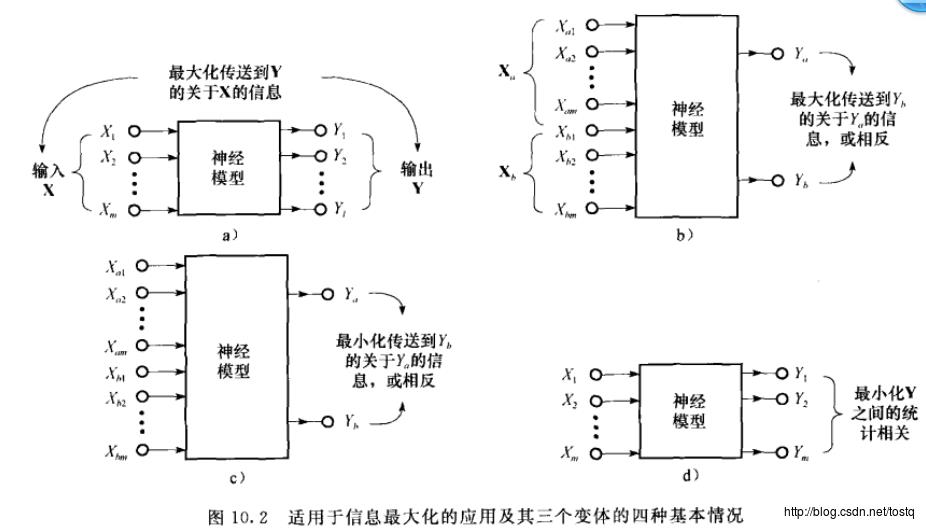
(a)

(b)

(c)

(d)
7.2 信息论相关定义
7.2.1 信息量
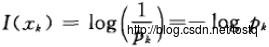
7.2.2 熵(微分熵)
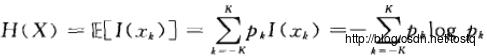
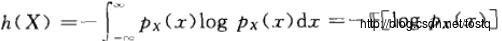
最大熵原则:当根据不完整的信息作为依据进行推断时,应该由满足分布限制条件的具有最大熵的概率分布推得。

7.2.3 互信息
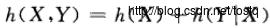
上面分别表示X,Y的联合熵(联合不确定性)等于X的熵(不确定性)加上给定X,Y的条件熵(给定X时Y的不确定性),而互信息量(如下)表示:X,Y间的相互不确定性
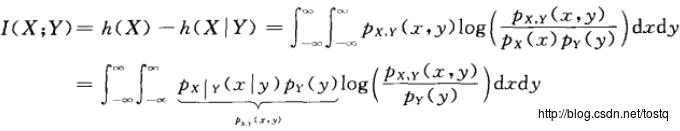
7.2.4 相对熵(KL散度)
KL散度( Kullback–Leibler divergence),又称相对熵(relative entropy),是描述两个概率分布P和Q差异的一种方法。
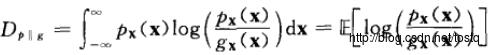
可以看出:互信息量是判断两个信息量之间独立程度
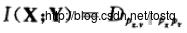
不相关指的是不线性相关,也就是协方差或者Pearson的线性相关系数为0
即Cov(X,Y)=E(XY)-EXEY=0 或者说 EXY=EXEY
独立就是两个随机变量相互独立,等价于f(x,y)=g(x)h(y),即联合密度函数等于两个边缘密度的乘积。
相对熵是非对称的,这意味着D(P||Q) ≠ D(Q||P)。特别的,在信息论中,D(P||Q)表示当用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布。
7.2.5 负熵
负熵定义:某信号假设是高斯分布的信息量,减少真实的信息量
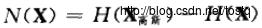
7.2.6 熵增益
熵增益是用于描述某种分类方法造成熵的减少程度:
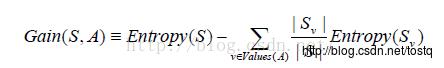
公式中的第二项是S按照属性A进行分类后,整体所具有的信息熵。value(A)表示A中具有的所有属性的值,计算各个属性值下的信息熵Sv在乘上Sv所含的样本数比例,相加得到按A分类后的信息熵。两者相减即为信息增益Gain(S,A)。
从信息增益的公式就可以看出,当第二项的值很小的时候,即按照A属性划分后,整体的熵很小时(说明分类较好),信息增益就会很大,这个时候我们说,按照A属性来进行划分,使得整体熵显著变小了!信息增益就表示了按照属性A划分后整体熵的降低值。最开始的最优分类属性便是采取信息增益来度量,将最大的选为最优的分类属性。
7.2.7 增益比率
当一个属性的值过多且没有实际分类价值时,他的信息增益会特别大,如日期属性年月日,如果将其划入分类的话,分类效果极其之差,当在验证数据上进行验证时,几乎无法进行分类。
所以定义信息增益比率来避免这种情况,如下:
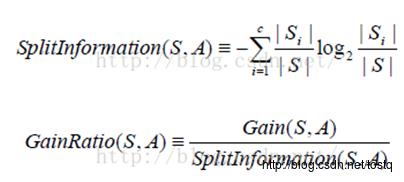
公式中Si跟信息增益中的Si意思一样,仍是属于i的样例个数。当属性的分类过多时,他的splitInformation会变大,以此来平衡。但是他也存在一个问题:即,当S中某个分类Si的样例过多,其他属性值下分类过少时,即Si→S时,会使得Split→0,所以最后大家想了一个折中的办法:先依次计算所有属性的Gain,然后仅对那些Gain值超过平均值的计算GainRatio。
7.3 独立分量分析(ICA)
7.3.1 盲源分离的问题
独立分量分析主要是为了解决一个盲源分离的问题:Y=WX
从一个随机信号S源和混合器A都是未知的,我们已知的是观测值X

我们需要估计分离矩阵W,使输出Y的各个分量尽可能地统计独立(即互信息量最大),这是在非监督的情况下进行的,而且用于分离S的仅有信息是包含在观测向量X中的。
对于独立分量分析是将随机向量分解为尽可能统计独立的线性分量。
7.3.2 盲源分离的必要条件
各个源必须是非高斯的,最多允许有一个源是高斯的,这是由于高斯源的线性组合也是高斯的。
同PCA的区别:
PCA是建立在各信号是不相关的情况下,所以PCA不需要假设最多允许有一个源是高斯的;而ICA是建立在输出信号各分量是独立情况,只有假设最多允许有一个源是高斯的如果观察到的信号为高斯,才有可能将信号分离。
7.3.3 独立分量分析步骤
所谓的独立分量分析,就是让所输出的Y各个分量之间的互信息量最大,而我们知道两向量之间的互信息量可以用相对熵来表示如下:

而我们要做是让Y各个分量之间相互独立,所以主要是想让各分量的联合分布Y和各分量之间的边缘分布的相对熵最大。
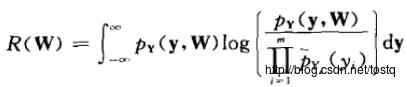
化简为:
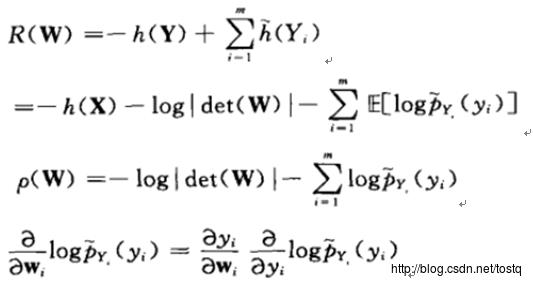
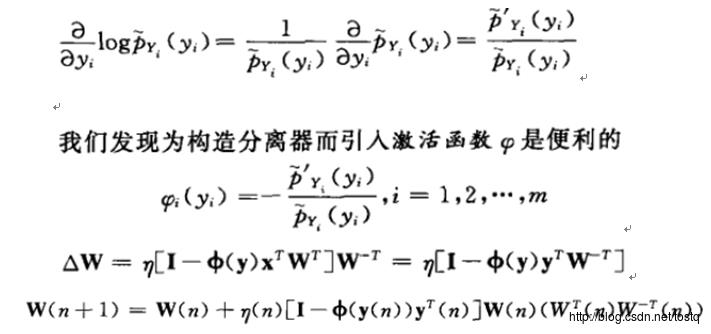
这里的关键在于激活函数的定义,要求边缘分布Py的任意数学描述必须和原始独立分量的真正分布相近。
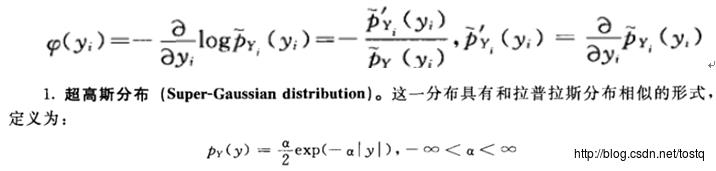
所以对于ICA的来说,关键在于找到原始独立分量的真正分布相近的激活函数定义
7.3.4 FastICA概念
FastICA:不同于前面的ICA(建立在相对熵基础上),FastICA是建立在随机变量非高斯性的概念(通过负熵来定义非高斯程度)
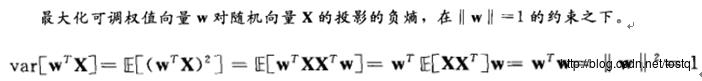
对于负熵,可以近似为,这里V表示高斯分布,U表示输出分量:
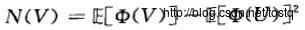
所以要使负熵最小,所以需要
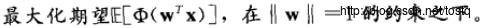
加入正则式对W求导
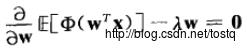
这里将负熵近似为上面的式子,这里Φ一般定义为非二次性函数,这类函数不能快速增长,使得估计过程更稳定!
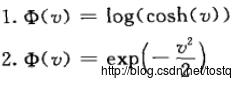
最后我们通过梯度下降法仍然可以解决这个问题。
较普通的ICA算法,FastICA收敛速度快。能通过使用一个非线性函数Φ便能直接找出任何非高斯分布的独立分量。而对于普通ICA算法来说,它们首先必须进行独立分量的概率密度分布函数的估计,然后才相应地进行非线性的选择。
FastICA独立分量可被逐个估计出来,在探索性数据分析里是非常有用的,这类似于做投影追踪,这在仅需要估计几个(不是全部)独立分量的情况下,能极大地减小计算量。
FastlCA算法本质上是一种最小化估计分量互信息的神经网络方法,是利用最大熵原理来近似负熵,并通过一个合适的非线性函数g使其达到最优。
7.4 确定性退火聚类
这里给出一个通过确定性退火算法来聚类

期望畸变:
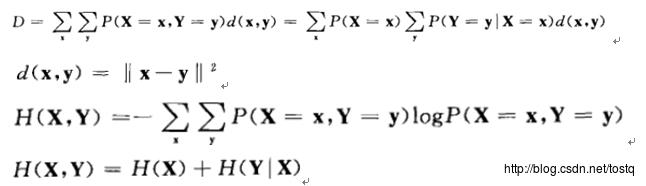
对于信号重建,首先考虑在温度高的时候,多考虑X,Y的互信息量最大,而当温度低时,考虑X,Y的差别缩小(期望畸变)。
H(X)是信源熵,H(Y|X)为给定信源X后重建信号Y的条件熵,而H(X)是独立于聚类的,从而只需要集中在条件熵就可以了:
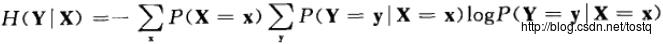
考虑到约束聚类与统计物理学之间的对应,我们可以考虑就联想概率写成如下Gibbs分布
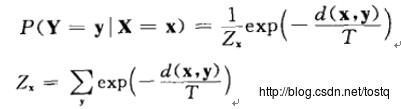
当温度过高时,所有输入向量都联想到聚类(这种联想被为极度模糊),如下,此时我们可以忽略期望畸变项,通过下式可以计算出联想概率。
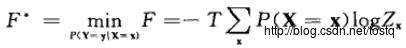
求梯度,最小化条件:

确定性退火的两步迭代:
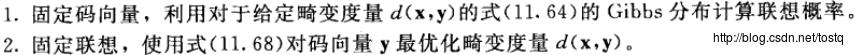
如果我们将联想概率P(Y|X)看成是一个随机变量的期望值,确定性退火的两步迭代也可看作是期望最大(EM)算法的一种形式。
以上是关于机器学习算法笔记7. 基于信息论的网络的主要内容,如果未能解决你的问题,请参考以下文章