行人重识别多个数据集格式统一为market1501格式
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了行人重识别多个数据集格式统一为market1501格式相关的知识,希望对你有一定的参考价值。
文章目录
market1501数据集介绍
2015年,论文 Person Re-Identification Meets Image Search 提出了 Market 1501 数据集,现在 Market 1501 数据集已经成为行人重识别领域最常用的数据集之一。
数据库中常见的缺点有:
- 数据库规模小(图片少)
- 摄像头个数少(一般为两个)
- 行人身份较少
- 每个身份的query只有一个
- 图片均为手动标记的完美图片,缺乏实际性
针对以上种种问题,创立了Market1501:
- 1501个身份
- 6个摄像头
- 32668张图片
- DPM检测器代替手工框出行人
- 500K张干扰图片
- 每一个身份有多个query
- 每一个query平均对应14.8个gallery
Market 1501 的行人图片采集自清华大学校园的 6 个摄像头,一共标注了 1501 个行人。其中,751 个行人标注用于训练集,750 个行人标注用于测试集,训练集和测试集中没有重复的行人 ID,也就是说出现在训练集中的 751 个行人均未出现在测试集中。
- 训练集:751 个行人,12936 张图片
- 测试集:750 个行人,19732 张图片
- query 集:750 个行人,3368 张图片。query 集的行人图片都是手动标注的图片,从 6 个摄像头中为测试集中的每个行人选取一张图片,构成 query 集。测试集中的每个行人至多有 6 张图片,query 集共有 3368 张图片。
网络模型训练时,会用到训练集;测试模型好坏时,会用到测试集和 query 集。此时测试集也被称作 gallery 集。因此实际用到的子集为,训练集、gallery 集 和 query 集。
数据集结构
Market 1501 包括以下几个文件夹:
- bounding_box_test 是测试集,包括 19732 张图片。
- bounding_box_train 是训练集,包括 12936 张图片。
- gt_bbox 是手工标注的训练集和测试集图片,包括 25259 张图片,用来区分 “good” “junk” 和 “distractors” 图片。
- query 是待查找的图片集,在 bounding_box_test 中实现查找。这些图片是手动绘制生成的。而 gallery 是通过 DPM 检测器生成的。
- gt_query 是一些 Matlab 格式的文件,里面记录了 “good” 和 “junk” 图片的索引,主要被用来评估模型。
数据集命名规则
以图片 0012_c4s1_000826_01.jpg 对数据集命名进行说明。

- 0012 是行人 ID,Market 1501 有 1501 个行人,故行人 ID 范围为 0001-1501
- c4 是摄像头编号(camera 4),表明图片采集自第4个摄像头,一共有 6 个摄像头
- s1 是视频的第一个片段(sequece1),一个视频包含若干个片段
- 000826 是视频的第 826 帧图片,表明行人出现在该帧图片中
- 01 代表第 826 帧图片上的第一个检测框,DPM 检测器可能在一帧图片上生成多个检测框
格式转化
1、创建数据集文件夹
新建1_makedir.py,插入代码:
import os
def make_market_dir(dst_dir='./'):
market_root = os.path.join(dst_dir, 'market1501')
train_path = os.path.join(market_root, 'bounding_box_train')
query_path = os.path.join(market_root, 'query')
test_path = os.path.join(market_root, 'bounding_box_test')
if not os.path.exists(train_path):
os.makedirs(train_path)
if not os.path.exists(query_path):
os.makedirs(query_path)
if not os.path.exists(test_path):
os.makedirs(test_path)
if __name__ == '__main__':
make_market_dir(dst_dir='./reID')
运行后就可以得到文件夹!
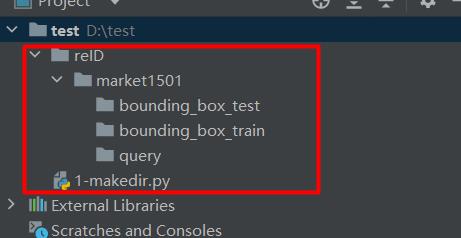
2、抽取market1501数据集
将market1501数据集放到目录,如下图:
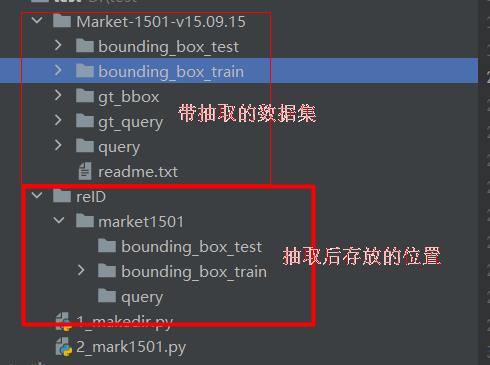
新建2_mark1501.py,插入代码:
import re
import os
import shutil
def extract_market(src_path, dst_dir):
img_names = os.listdir(src_path)
# 定义正则表达式,数字_c数字
pattern = re.compile(r'([-\\d]+)_c(\\d)')
for img_name in img_names:
# 判断是否是jpg格式的图片
if '.jpg' not in img_name:
continue
print(img_name)
# pid: 每个人的标签编号 1
# _ : 摄像头号 2
pid, _ = map(int, pattern.search(img_name).groups())
print(pid)
# 去掉没用的图片
if pid == 0 or pid == -1:
continue
shutil.copy(os.path.join(src_path, img_name), os.path.join(dst_dir, img_name))
if __name__ == '__main__':
src_train_path = './Market-1501-v15.09.15/bounding_box_train'
src_query_path = './Market-1501-v15.09.15/query'
src_test_path = './Market-1501-v15.09.15/bounding_box_test'
# 将整个market1501数据集作为训练集
dst_train_dir = r'./reID/market1501/bounding_box_train'
dst_test_dir = r'./reID/market1501/bounding_box_test'
extract_market(src_train_path, dst_train_dir)
extract_market(src_query_path, dst_train_dir)
extract_market(src_test_path, dst_test_dir)
抽取后的结果:
3、抽取CUHK03数据集
ID从1502开始,一共1467个不同ID的行人
import re
import os
import shutil
def extract_cuhk03(src_path, dst_dir):
img_names = os.listdir(src_path)
pattern = re.compile(r'([-\\d]+)_c(\\d)_([\\d]+)')
for img_name in img_names:
if '.png' not in img_name and '.jpg' not in img_name:
continue
print(img_name)
# pid: 每个人的标签编号 1
# camid : 摄像头号 2
pid, camid, fname = map(int, pattern.search(img_name).groups())
# 这里注意需要加上前面的market1501数据集的最后一个ID 1501
# 在前面数据集的最后那个ID基础上继续往后排
pid += 1501
dst_img_name = str(pid).zfill(6) + '_c' + str(camid) + '_CUHK' + str(fname) + '.jpg'
shutil.copy(os.path.join(src_path, img_name), os.path.join(dst_dir, dst_img_name))
if __name__ == '__main__':
src_train_path = './cuhk03-np/detected/bounding_box_train'
src_query_path = './cuhk03-np/detected/query'
src_test_path = './cuhk03-np/detected/bounding_box_test'
dst_dir = './reID/market1501/bounding_box_train'
dst_test_dir = './reID/market1501/bounding_box_test'
extract_cuhk03(src_train_path, dst_dir)
extract_cuhk03(src_query_path, dst_dir)
extract_cuhk03(src_test_path, dst_test_dir)
两个数据集的训练集加起来有2万张了图片,测试集有1.8万张图片,接下来就不在增加测试集的数据了。
4、抽取MSMT17数据集
训练集包含1041个行人共32621个包围框,而测试集包括3060个行人共93820个包围框。
数据集选择用MSMT17V1,链接:
https://pan.baidu.com/s/19-cKxL_UVKNHc7kqqp0GVg
提取码:yf3z
import re
import os
import shutil
def msmt2market(dir_path, dst_dir, prev_pid):
img_names = os.listdir(dir_path)
pattern = re.compile(r'([-\\d]+)_c([-\\d]+)_([\\d]+)')
for img_name in img_names:
# 判断是否是jpg格式的图片
if '.jpg' not in img_name:
continue
print(img_name)
# pid: 每个人的标签编号 1
# _ : 摄像头号 2
pid, camid, fname = map(int, pattern.search(img_name).groups())
print(pid)
# 去掉没用的图片
if pid == -1:
continue
pid_new = pid + 1 + prev_pid
dst_img_name = str(pid_new).zfill(6) + '_c' + str(camid) + '_MSMT' + str(fname) + '.jpg'
print(dst_img_name)
shutil.copy(os.path.join(dir_path, img_name),os.path.join(dst_dir, dst_img_name))
if __name__ == '__main__':
src_train_path = './MSMT17/bounding_box_train'
src_query_path = './MSMT17/query'
src_test_path = './MSMT17/bounding_box_test'
dst_dir = './reID/market1501/bounding_box_train'
msmt2market(src_train_path, dst_dir, 2968)
msmt2market(src_query_path, dst_dir, 4009)
msmt2market(src_test_path, dst_dir, 4009)
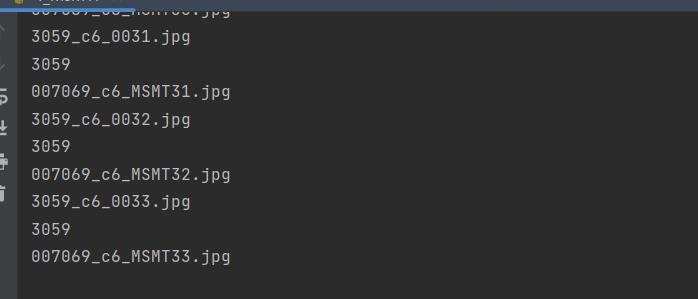
导入完成后id增加到了7069。
5、抽取viper数据集
viper数据集一共有1264张图片, ID从007070到007943一共1467个不同ID的行人
新建脚本5_viper.py,插入代码:
import re
import os
import shutil
def extract_viper(src_path, dst_dir, camid=1):
img_names = os.listdir(src_path)
pattern = re.compile(r'([\\d]+)_([\\d]+)')
for img_name in img_names:
if '.bmp' not in img_name:
continue
print(img_name)
pid, fname = map(int, pattern.search(img_name).groups())
# 这里注意需要加上前面的数据集的最后一个ID 7069
# 由于viper数据集ID是从0开始,因此需要+1
pid += 7069 + 1
print(pid)
dst_img_name = str(pid).zfill(6) + '_c' + str(camid) + '_viper' + str(fname) + '.jpg'
shutil.copy(os.path.join(src_path, img_name), os.path.join(dst_dir, dst_img_name))
if __name__ == '__main__':
src_cam_a = './VIPer/cam_a'
src_cam_b = './VIPer/cam_b'
dst_dir = './reID/market1501/bounding_box_train'
extract_viper(src_cam_a, dst_dir, camid=1)
extract_viper(src_cam_b, dst_dir, camid=2)
导入完成后,id为7943。
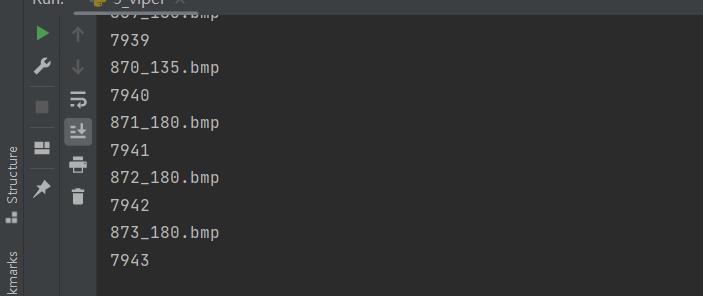
6、抽取prid 2011
PRID数据集有摄像机A的385条轨迹和摄像机b的749条轨迹,其中只有200人出现在两个摄像机中。该数据集还有一个单镜头版本,由随机选择的快照组成。有些轨迹没有很好地同步,这意味着人可能会在连续的帧之间“跳跃”。
import re
import os
import shutil
def extract_prid(src_path, dst_dir, prevID, camid=1):
pattern = re.compile(r'person_([\\d]+)')
pid_container = set()
sub_dir_names = os.listdir(src_path) # ['person_0001', 'person_0002',...
for sub_dir_name in sub_dir_names: # 'person_0001'
img_names_all = os.listdir(os.path.join(src_path, sub_dir_name))
# 这里我就只取首尾两张,防止重复太多了
img_names = [img_names_all[0], img_names_all[-1]]
for img_name in img_names: # '0001.png'
if '.png' not in img_name:
continue
print(img_name)
# parent.split('\\\\')[-1] : person_0001
pid = int(pattern.search(sub_dir_name).group(1))
pid += prevID
print(pid)
dst_img_name = str(pid).zfill(6) + '_c' + str(camid) + '_prid' + img_name.replace('.png', '.jpg')
print(dst_img_name)
# shutil.copy(os.path.join(src_path, sub_dir_name, img_name), os.path.join(dst_dir, dst_img_name))
if __name__ == '__main__':
src_cam_a = './prid_2011/multi_shot/cam_a'
src_cam_b = './prid_2011/multi_shot/cam_b'
dst_dir = './reID/market1501/bounding_box_train'
extract_prid(src_cam_a, dst_dir, 7943)
extract_prid(src_cam_b, dst_dir, 8328)
导入prid2011之后,id为9077
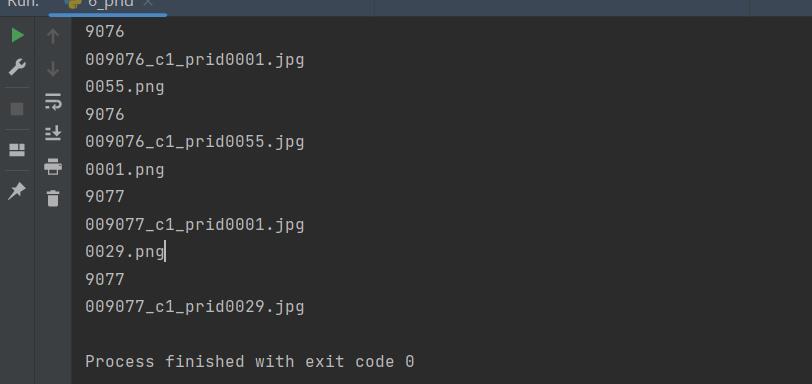
7、抽取i-LIDS-VID数据集
导入i-LIDS-VID数据集后,id为9396
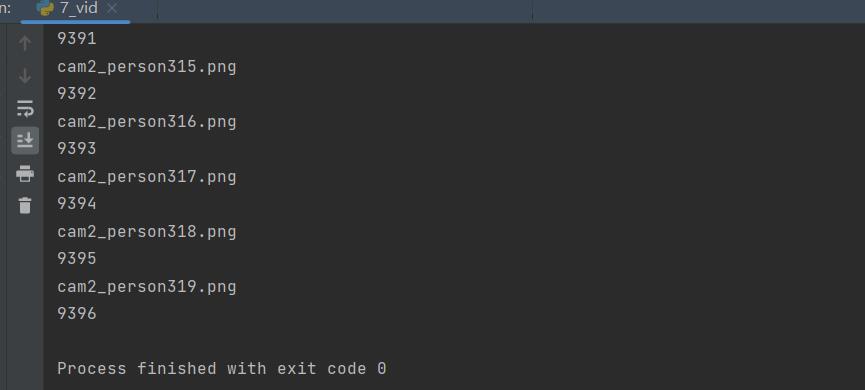
8、抽取GRID数据集
QMUL地下再识别(GRID)数据集包含250个行人图像对。每一对都包含两张从不同视角看到的同一个体的图像。所有的图像都是从安装在一个繁忙的地铁站的8个不相交的摄像头视图中捕捉到的。旁边的图显示了该站的每个相机视图的快照和数据集中的样本图像。由于姿势的变化,颜色,灯光的变化,数据集是具有挑战性的;以及低空间分辨率造成的图像质量差。
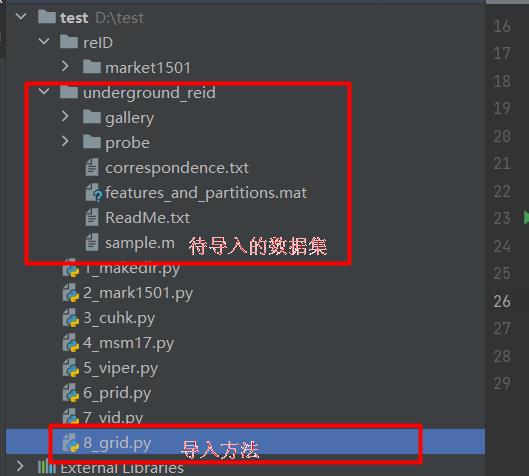
新建8_grid.py脚本,插入代码:
import re
import os
import shutil
def extract_grid(src_path, dst_dir, camid=1):
img_names = os.listdir(src_path)
pattern = re.compile(r'([\\d]+)_')
pid_container = set()
for img_name in img_names:
if '.jpeg' not in img_name:
continue
print(img_name)
pid = int(pattern.search(img_name).group(1))
if pid == 0:
continue
pid += 9396
print(pid)
dst_img_name = str(pid).zfill(6) + '_c' + str(camid) + '_grid' + '.jpg'
shutil.copy(os.path.join(src_path, img_name), os.path.join(dst_dir, dst_img_name))
if __name__ == '__main__':
src_cam_a = './underground_reid/probe'
src_cam_b = './underground_reid/gallery'
dst_dir = './reID/market1501/bounding_box_train'
extract_grid(src_cam_a, dst_dir, camid=1)
extract_grid(src_cam_b, dst_dir, camid=2)
共有9646个ID。
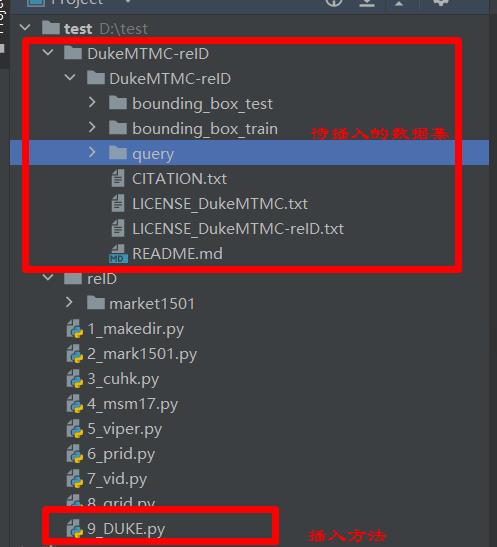
9、抽取DukeMTMC-reID数据集
DukeMTMC-reID的数据规模比较大,格式和CUHK03数据集一致。如下图:
收取数据的代码如下:
import re
import os
import shutil
def extract_duke(src_path, dst_dir):
img_names = os.listdir(src_path)
pattern = re.compile(r'([-\\d]+)_c(\\d)_f([\\d]+)')
for img_name in img_names:
if '.png' not in img_name and '.jpg' not in img_name:
continue
print(img_name)
# pid: 每个人的标签编号 1
# camid : 摄像头号 2
pid, camid, fname = map(int, pattern.search(img_name).groups())
# 这里注意需要加上前面的market1501数据集的最后一个ID 1501
# 在前面数据集的最后那个ID基础上继续往后排
pid += 9646
print( pid, camid, fname)
dst_img_name = str(pid).zfill(6) + '_c' + str(camid) + '_Duke' + str(fname) + '.jpg'
print(dst_img_name)
shutil.copy(os.path.join(src_path, img_name), os.path.join(dst_dir, dst_img_name))
if __name__ == '__main__':
src_train_path = './DukeMTMC-reID/DukeMTMC-reID/bounding_box_train'
src_test_path ='./DukeMTMC-reID/DukeMTMC-reID/bounding_box_test'
src_query_path = './DukeMTMC-reID/DukeMTMC-reID/query'
dst_dir = './reID/market1501/bounding_box_train'
extract_duke(src_train_path, dst_dir)
extract_duke(src_test_path, dst_dir)
完成后,ID为16786。
运行FastReid
将制作好的数据集,替换原来的的market1501数据集。
然后在market1501.py脚本修改如下代码:
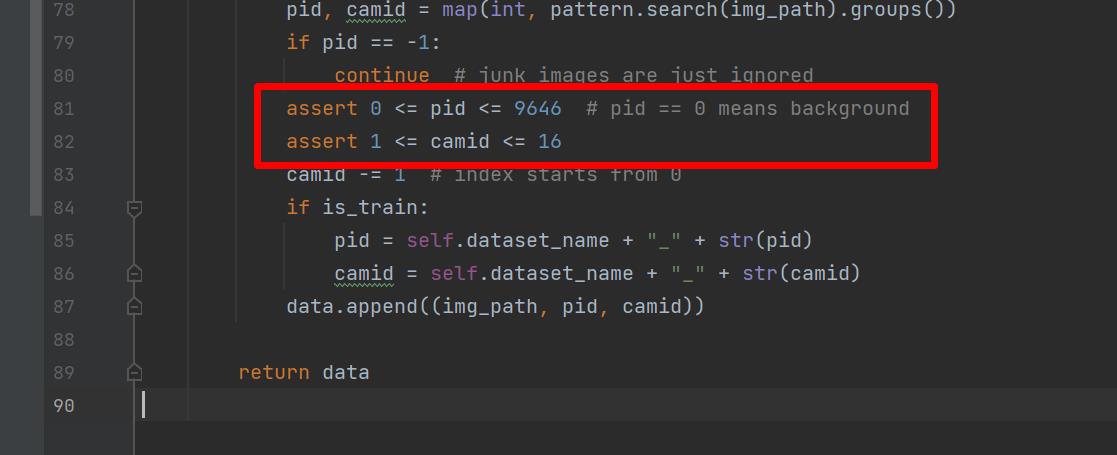
ID改为9646,相机最大是16,所以相机的id<=16。改完之后就可以运行了。

参考文章
https://blog.csdn.net/songwsx/article/details/102987787
以上是关于行人重识别多个数据集格式统一为market1501格式的主要内容,如果未能解决你的问题,请参考以下文章
阅读笔记-Deep learning for person re-identification: A survey and outlook