行人重识别数据集汇总
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了行人重识别数据集汇总相关的知识,希望对你有一定的参考价值。
文章目录
- 摘要
- VIPeR数据集
- ETH1,2,3数据集
- QMUL iLIDS
- GRID
- CAVIAR4ReID
- 3DPeS
- PRID2011
- V47
- WARD
- SAIVT-Softbio
- CUHK01
- CUHK02
- CUHK03
- RAiD
- iLIDS-VID
- MPR Drone
- HDA Person Dataset
- Shinpuhkan Dataset
- CASIA Gait Database B
- Market1501
- PKU-Reid
- PRW
- MARS
- DukeMTMC-reID/DukeMTMC4ReID
- P-DukeMTMC-reID 遮挡行人数据集
- Airport
- MSMT17
- RPIfield
- LPW
- PKU Sketch-ReID
- ThermalWorld
- SYSU-30k 数据集
- PETA 远距离行人识别数据集
摘要
汇总了一些REID的数据集,几乎涵盖了所有的数据集。如果有缺少的欢迎留言补充。
我将能下载到的数据集放在了网盘里,链接如下:
链接:https://pan.baidu.com/s/1hQ4PKvtAhAvoZiXbcIu93w 提取码:o3iy
VIPeR数据集
VIPeR数据集包括632个行人的1264张图像,每个行人有两张图像,采集自摄像头a和摄像头b. 每张图像都调整为了128x48的大小。
该数据集的特点为视角和光照的多样性。
官方网站:https://vision.soe.ucsc.edu/node/178/

下载链接
百度网盘下载地址:
链接: https://pan.baidu.com/s/1PI5QFlwJbtDhHM8cLwQ_gw 提取码: fm35
链接:https://pan.baidu.com/s/1XgdC0MuX1QNtQI81hdb3Xg 提取码:e80b
ETH1,2,3数据集
与其他数据集从多台相机收集图像不同,ETHZ从一个移动的相机收集图像。虽然视点方差比较小,但它确实有相当大的光照方差、尺度方差和遮挡。

下载链接
下载链接:https://homepages.dcc.ufmg.br/~william/datasets.html
QMUL iLIDS
介绍
QMUL iLIDS基于iLIDS MCTS的数据集,是一个在机场繁忙时候通过监控系统中多个摄像头收集到的数据集。几乎每个ID(identity)都有从两个无重叠(区域)的摄像头拍摄的四幅图像。该数据集具有严重遮挡和姿势差异的场景。
采样了119个人479张图像。图片大小:128*64。每个人平均有4个张图像。有大的照明 改变和遮挡。

下载链接
下载地址:http://www.eecs.qmul.ac.uk/~jason/data/i-LIDS_Pedestrian.tgz
链接:https://pan.baidu.com/s/1MiREr8An0y5keSst3vtUSw 提取码:s1qx
GRID
QMUL地下再识别(GRID)数据集包含250个行人图像对。每一对都包含两张从不同视角看到的同一个体的图像。所有的图像都是从安装在一个繁忙的地铁站的8个不相交的摄像头视图中捕捉到的。旁边的图显示了该站的每个相机视图的快照和数据集中的样本图像。由于姿势的变化,颜色,灯光的变化,数据集是具有挑战性的;以及低空间分辨率造成的图像质量差。
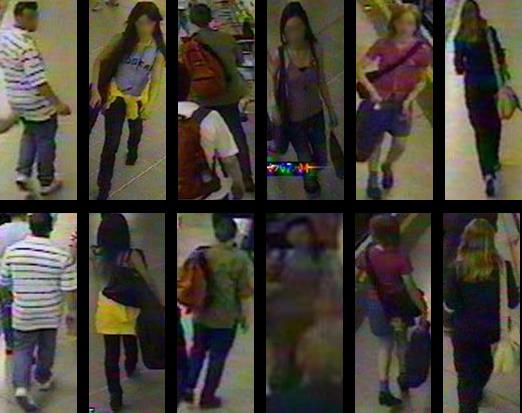
有两个文件夹:
-
文件夹“probe”包含在一个视图中捕获的250个探测图像。
-
文件夹’gallery’包含250张在其他视图中捕获的探测的真实匹配图像。此外,总共有775个图像不属于任何探测器。在交叉验证期间,这些额外的图像应该被视为测试集中的固定部分。
下载链接
下载地址:http://personal.ie.cuhk.edu.hk/~ccloy/downloads_qmul_underground_reid.html
CAVIAR4ReID
该数据集由两个视场重叠的监控摄像机采集的购物中心多目标跟踪数据集CAVIAR中提取。在72个身份中,有50个拥有两个摄像头拍摄的图像,其余22个只有一个摄像头拍摄的图像。每个标识的图像都经过精心选择,以使分辨率方差最大化。

下载链接
下载地址:https://lorisbaz.github.io/caviar4reid.html
3DPeS
3DPeS数据集由8台不重叠的户外摄像机采集。虽然提供了原始视频,但研究人员总是使用选定的快照来测试人的重识别算法。它具有三维环境模型和所有相机的校准数据。在视频序列中,只提供每个标识的第一个出现帧的边界框。
不同于iLIDS和PRID,它提供了完整的监控视频序列:提供了6个视频对集合,15 帧/s,分辨率704*576。一共193个行人。

下载链接
下载地址:http://www.openvisor.org/3dpes.asp
PRID2011
PRID数据集有摄像机A的385条轨迹和摄像机b的749条轨迹,其中只有200人出现在两个摄像机中。该数据集还有一个单镜头版本,由随机选择的快照组成。有些轨迹没有很好地同步,这意味着人可能会在连续的帧之间“跳跃”。

下载链接
- 下载链接:https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/PRID11/
- 网盘链接:链接: https://pan.baidu.com/s/1SduF0ArzFzq9LICQudTRMw 提取码: ywn6
V47
V47数据集采用两个视野重叠的室内摄像机采集。每个身份都有两个不同的方向(向内和向外),并在几个不同的视角中被捕捉到。

Wang, S.M., Lewandowski, M., Annesley, J. and Orwell, J. (2011) Re-identification of pedestrians with variable occlusion and scale. In: IEEE International Conference on Computer Vision (ICCV);
WARD
这个数据集是用三个不重叠的相机收集的。每个身份在每个相机中都有几个图像。

Martinel, N., & Micheloni, C. (2012, June). Re-identify people in wide area camera network. In 2012 IEEE computer society conference on computer vision and pattern recognition workshops (pp. 31-36). IEEE.
下载链接
https://github.com/iN1k1/CVPR2012/tree/master/toolbox/Datasets
链接:https://pan.baidu.com/s/16qJ6iRjovayZ2JrzUAbnMQ 提取码:kuz7
SAIVT-Softbio
SAIVT-SoftBio数据库包含一组8个监控摄像头捕捉到的152个行人的多摄像头序列集合。该数据库为人员再检测任务提供了一个具有挑战性和现实的测试平台,并可免费下载。

Bialkowski, Alina, Denman, Simon, Lucey, Patrick, Sridharan, Sridha, & Fookes, Clinton B. (2012) A database for person re-identification in multi-camera surveillance networks. In Proceedings of the 2012 International Conference on Digital Image Computing Techniques and Applications (DICTA 12), IEEE, Esplanade Hotel, Fremantle, WA, pp. 1-8.
下载链接
1、https://data.researchdatafinder.qut.edu.au/dataset/saivt-soft-biometric
2、链接:https://pan.baidu.com/s/1hy9M-st9l7fFNpCFjak9gQ 提取码:pzm8
CUHK01
CUHK01数据集包含来自每个摄像机的每个身份的两个图像。该数据集具有一对不相交的相机,并且该数据集的图像质量相对较好。
971个身份,3884个图像,手动裁剪。2个视角,view A 主要捕获人的正面和背面,view B捕获侧面。每个人有4张图像,每个视角下有2张图像。

W. Li, R. Zhao and X. Wang, “Human Reidentification with Transferred Metric Learning” in Proceedings of Asian Conference on Computer Vision (ACCV) 2012.
下载链接
链接:https://pan.baidu.com/s/1WVQlkm2tIzIO0KskxCrScg
提取码:lz5z
CUHK02
CUHK02是CUHK01的扩展数据集。除了CUHK01中的相机对外,它还有四个相机对设置。
1816个身份,7264个图像,手动裁剪。取自5个不同的户外camera对,共1816人。5个camera对分别有971,306,107,193,239人,大小160*60. 每个人在每个摄像机下的不同时间内取两张图片。大多数人都有负重(背包,手提包,皮带包,行李)。

W. Li and X. Wang, “Locally Aligned Feature Transforms across Views” in Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) 2013.
下载链接
http://www.ee.cuhk.edu.hk/~xgwang/CUHK_identification.html
CUHK03
CUHK03是第一个大到足以进行深度学习的人物再识别数据集。它提供了从可变形零件模型(DPM)中检测到的边界框和手动标记。对于这个数据集,人员检测质量相对较好。
测试协议:
CUHK-03的测试协议有两种。
-
第一种为旧的版本(参考文献[1], 即数据集的出处 ),参见数据集中的’testsets’测试协议。具体地说,即随机选出100个行人作为测试集,1160个行人作为训练集,100个行人作为验证集(这里总共1360个行人而不是1467个,这是因为实验中没有用到摄像头组pair 4和5的数据),重复二十次。这种测试协议是single-shot setting.
-
第二种测试协议(参考文献[2] )类似于Market-1501,它将数据集分为包含767个行人的训练集和包含700个行人的测试集。在测试阶段,我们随机选择一张图像作为query,剩下的作为gallery,这样的话,对于每个行人,有多个ground truth在gallery中。(新测试协议可以参考这里)
下载链接
Google Drive:
https://drive.google.com/file/d/0BxJeH3p7Ln48djNVVVJtUXh6bXc/edit?usp=sharing
Baidu Cloud Disk ( password: rhjq ):
http://pan.baidu.com/s/1mgklxSc
链接:https://pan.baidu.com/s/1x0gwsUZ57KJGbchDVskZuQ
提取码:xqlk
RAiD
作为一个相对较新的发布的数据集,RAiD保证每个身份在所有四个不重叠的摄像机中都有图像。由于两个摄像头在室内,另外两个在室外,照明差异相当大。每个身份的图像以跟踪的方式收集,但顺序并不总是一致的。

Das, A., Chakraborty, A., & Roy-Chowdhury, A. K. (2014, September). Consistent re-identification in a camera network. In European Conference on Computer Vision (pp. 330-345). Springer International Publishing.
下载链接
https://cs-people.bu.edu/dasabir/raid.php
链接:https://pan.baidu.com/s/1_eZlGN32PxY4S_ubOO9Pvg
提取码:j4ui
iLIDS-VID
iLIDS-VID数据集涉及在公共开放空间中的两个不相交的摄像机视图中观察到的300个不同的行人。包含两个版本:基于静态图像(参见名为“ILIDS-VID \\ images”的文件夹)和基于图像序列(参见名为“ILIDS-VID \\ sequences”的文件夹)。
取自监控航空接站大厅,从2个不相交摄像机创建该数据集。随机为300个人采样了600个视频,每人有来自两个视觉的一对视频。每个视频有23~192帧,平均73帧。相似的衣服、光照和视觉改变,复杂的背景和严重的遮挡,很具挑战性。



Wang, T., Gong, S., Zhu, X., & Wang, S. (2016). Person Re-Identification by Discriminative Selection in Video Ranking.
下载链接
链接:https://pan.baidu.com/s/1dhMb80E-LM9A61Qnt8XfBA
提取码:zp1t
MPR Drone
MPR是由飞行的无人机在室内和室外环境中收集行人重识别数据集。由于它只有一个摄像头,所以作者在原论文中提出了三种不同类型的评价实验。所有的行人检测都是通过Piotr Dollar工具箱中的金字塔特征检测得到的。它有两个子数据集。数据集01已经被标记了113610次检测。数据集02提供数据集01的原始帧数据。
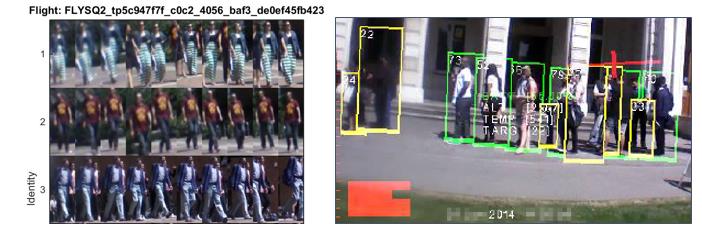
Layne, R., Hospedales, T. M., & Gong, S. (2014, September). Investigating Open-World Person Re-identification Using a Drone. In European Conference on Computer Vision (pp. 225-240). Springer International Publishing.
下载地址
无
HDA Person Dataset
HDA数据集是一个多摄像机高分辨率图像序列数据集,用于高分辨率监控研究。在一个典型的室内办公场景中,在繁忙时间(午餐时间),在30分钟内同时记录了18个摄像头(包括VGA、HD和全高清分辨率),涉及80多人。在当前版本(v1.1)中,有13个摄像头已经被完全标记。

Figueira, D., Taiana, M., Nambiar, A., Nascimento, J., & Bernardino, A. (2014, September). The hda+ data set for research on fully automated re-identification systems. In European Conference on Computer Vision (pp. 241-255). Springer International Publishing.
下载地址
http://vislab.isr.ist.utl.pt/hda-dataset/
Shinpuhkan Dataset
Shinpuhkan数据集最初是为了测试多摄像机跟踪方法而创建的。每个人在每个摄像头中有多个不同方向的轨迹。每个标识总共有86个带注释的tracklet。与其他传统的re-id数据集相比,该数据集的图像质量较好。

Kawanishi, Y., Wu, Y., Mukunoki, M., & Minoh, M. (2014). Shinpuhkan2014: A multi-camera pedestrian dataset for tracking people across multiple cameras. In 20th Korea-Japan Joint Workshop on Frontiers of Computer Vision (Vol. 5, p. 6).
下载链接
http://www.mm.media.kyoto-u.ac.jp/en/datasets/shinpuhkan/
CASIA Gait Database B
CASIA数据集创建于2005年,最初用于测试步态识别算法。2015年,Liu等人利用该数据集测试了一种基于步态的人物再识别算法。这个数据集是由11个摄像头在0到180度的不同视角下重叠收集的。每个身份也会改变衣服和携带条件。不提供边界框,而是给出原始视频帧和每帧的轮廓。
数据集B中的视频文件名格式为‘xxx-mm-nn-ttt.avi’格式的,
-
Xxx:主题编号,001到124。
-
Mm:行走状态,可以是’nm’(正常),‘cl’(穿着外套)或’bg’(背着包)。
-
神经网络:序号。
-
Ttt:视角,可以是’000’,‘018’,…,“180”。


下载地址
http://www.cbsr.ia.ac.cn/english/Gait%20Databases.asp
Market1501
介绍
2015年,论文 Person Re-Identification Meets Image Search 提出了 Market 1501 数据集,现在 Market 1501 数据集已经成为行人重识别领域最常用的数据集之一。
数据库中常见的缺点有:
- 数据库规模小(图片少)
- 摄像头个数少(一般为两个)
- 行人身份较少
- 每个身份的query只有一个
- 图片均为手动标记的完美图片,缺乏实际性
针对以上种种问题,创立了Market1501:
- 1501个身份
- 6个摄像头
- 32668张图片
- DPM检测器代替手工框出行人
- 500K张干扰图片
- 每一个身份有多个query
- 每一个query平均对应14.8个gallery
Market 1501 的行人图片采集自清华大学校园的 6 个摄像头,一共标注了 1501 个行人。其中,751 个行人标注用于训练集,750 个行人标注用于测试集,训练集和测试集中没有重复的行人 ID,也就是说出现在训练集中的 751 个行人均未出现在测试集中。
- 训练集:751 个行人,12936 张图片
- 测试集:750 个行人,19732 张图片
- query 集:750 个行人,3368 张图片。query 集的行人图片都是手动标注的图片,从 6 个摄像头中为测试集中的每个行人选取一张图片,构成 query 集。测试集中的每个行人至多有 6 张图片,query 集共有 3368 张图片。
网络模型训练时,会用到训练集;测试模型好坏时,会用到测试集和 query 集。此时测试集也被称作 gallery 集。因此实际用到的子集为,训练集、gallery 集 和 query 集。
数据集结构
Market 1501 包括以下几个文件夹:
- bounding_box_test 是测试集,包括 19732 张图片。
- bounding_box_train 是训练集,包括 12936 张图片。
- gt_bbox 是手工标注的训练集和测试集图片,包括 25259 张图片,用来区分 “good” “junk” 和 “distractors” 图片。
- query 是待查找的图片集,在 bounding_box_test 中实现查找。这些图片是手动绘制生成的。而 gallery 是通过 DPM 检测器生成的。
- gt_query 是一些 Matlab 格式的文件,里面记录了 “good” 和 “junk” 图片的索引,主要被用来评估模型。
数据集命名规则
以图片 0012_c4s1_000826_01.jpg 对数据集命名进行说明。

- 0012 是行人 ID,Market 1501 有 1501 个行人,故行人 ID 范围为 0001-1501
- c4 是摄像头编号(camera 4),表明图片采集自第4个摄像头,一共有 6 个摄像头
- s1 是视频的第一个片段(sequece1),一个视频包含若干个片段
- 000826 是视频的第 826 帧图片,表明行人出现在该帧图片中
- 01 代表第 826 帧图片上的第一个检测框,DPM 检测器可能在一帧图片上生成多个检测框
下载链接
链接:https://pan.baidu.com/s/1FEdmKO5MNEiHE3R5Loc3fg 提取码:xdej
PKU-Reid
与其他现代re-id数据集相比,PKU-Reid数据集相对较小。这个数据集的主要特点是它在两个不相交的摄像头中从所有八个方向捕捉人的外观。

下载链接
链接: https://pan.baidu.com/s/1-XPCWH_acnEkP-jrt6Gs6w 提取码: 4szc
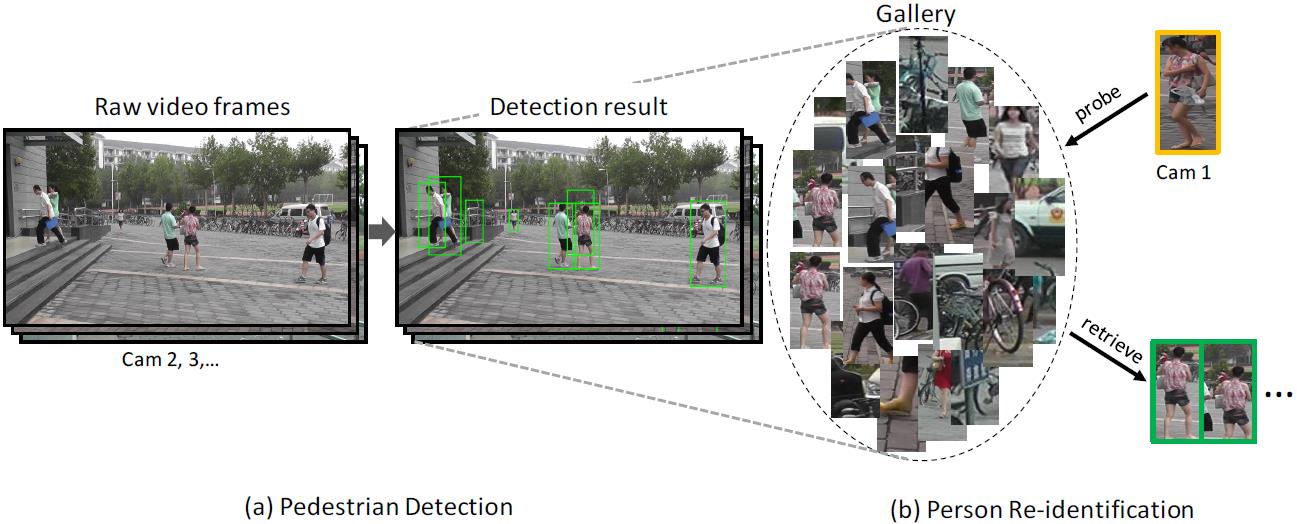
PRW
PRW (Person Re-identification in The Wild)数据集是对Maretk1501数据集的扩展。作者没有只提供边界框,而是发布了带有注释的完整帧。因此,可以评估不同的人探测器的影响。
Zheng, L., Zhang, H., Sun, S., Chandraker, M., & Tian, Q. (2016). Person Re-identification in the Wild. arXiv preprint arXiv:1604.02531.
下载链接
链接:https://pan.baidu.com/s/16B8XJfQSe-CClfOjLxwGLg
提取码:gm65
Large scale person search
与PRW数据集类似,人物搜索数据集是具有全帧访问和大量标记边界框的大型数据集。它旨在模拟真实的人物搜索场景。因此,为了测试这个数据集,需要一个可靠的人员检测器。为了使数据集更加困难,画廊部分包括手持相机和电影的帧。此外,还释放了两个子集,即低分辨率子集和遮挡子集,以评估这些因素的影响。

Xiao, T., Li, S., Wang, B., Lin, L., & Wang, X. (2016). End-to-End Deep Learning for Person Search. arXiv preprint arXiv:1604.01850.
下载链接
http://www.ee.cuhk.edu.hk/~xgwang/PS/dataset.html
MARS
MARS(运动分析和再识别集)数据集是Market1501数据集的扩展版本。这是第一个基于视频的大规模人物重新识别数据集。因为所有的边界框和轨迹小函数都是自动生成的,所以它包含干扰,而且每个标识可能有多个轨迹小函数。预先计算的深度特征也可以在网站上找到。

Zheng, L., Bie, Z., Sun, Y., Wang, J., Su, C., Wang, S., & Tian, Q. (2016, October). Mars: A video benchmark for large-scale person re-identification. In European Conference on Computer Vision (pp. 868-884). Springer International Publishing.
下载链接
链接:https://pan.baidu.com/s/1nqUU6BJ10ypwfMG2yQDwtA 提取码:woy6
http://www.liangzheng.com.cn/Project/project_mars.html
DukeMTMC-reID/DukeMTMC4ReID
DukeMTMC数据集是一个大规模的重标记多目标多摄像头跟踪数据集。总共有超过2700人在8个摄像头中被贴上了独特的身份标签。随着对所有信息(全帧,帧级地面真相,校准信息等)的访问,这个数据集有很多潜力。基于发布的训练验证集,创建两个re-id扩展数据集。关键的区别在于生成边界框的方式。DukeMTMC-reID直接使用手动标记的地面真相,而DukeMTMC4ReID采用Doppia作为人探测器。
下载链接
链接: https://pan.baidu.com/s/1-uE4coVJs3LTVAhKWAHu3Q 提取码: k3s3
P-DukeMTMC-reID 遮挡行人数据集
P-DukeMTMC-reID 是一个遮挡行人数据集。该数据集是从 DukeMTMC-reID dataset 中人工挑选出来的。P-DukeMTMC-reID 数据集中,12,927 张图像(665 个身份)用于训练,2,163 张图像(634 个标识)用于查询,图库集包含 9,053 个图像。

下载链接
链接:https://pan.baidu.com/s/1AhOsfekmQnwn9KufA3FcWg
提取码:j1ht
Airport
该数据集是使用来自一个中型机场室内监控网络的6个摄像头的视频创建的。这些摄像头覆盖了一个中央安检检查站区域和三个大厅的不同部分。每台相机有768 × 432像素,以每秒30帧的速度拍摄视频。从每个摄像头收集了从早上8点到晚上8点长达12小时的视频。假设每个目标人群在网络上花费的时间是有限的,每个长视频被随机分成40个5分钟长的视频片段。每个视频剪辑然后通过一个原型端到端重新识别系统组成的自动人检测和跟踪算法。

Karanam, S., Gou, M., Wu, Z., Rates-Borras, A., Camps, O., & Radke, R. J. (2018). IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018.
官方地址:
https://alert.northeastern.edu/transitioning-technology/alert-datasets/alert-airport-re-identification-dataset/
MSMT17
介绍
CVPR2018会议上,提出了一个新的更接近真实场景的大型数据集MSMT17,即Multi-Scene Multi-Time,涵盖了多场景多时段。数据集采用了安防在校园内的15个摄像头网络,其中包含12个户外摄像头和3个室内摄像头。为了采集原始监控视频,在一个月里选择了具有不同天气条件的4天。每天采集3个小时的视频,涵盖了早上、中午、下午三个时间段。因此,总共的原始视频时长为180小时。
基于Faster RCNN作为行人检测器,三位人工标注员用了两个月时间查看检测到的包围框和标注行人标签。最终,得到4101个行人的126441个包围框。和其它数据集的对比以及统计信息如下图所示。
目录结构
MSMT17
├── bounding_box_test
├── 0000_c1_0002.jpg
├── 0000_c1_0003.jpg
├── 0000_c1_0005.jpg
├── bounding_box_train
├── 0000_c1_0000.jpg
├── 0000_c1_0001.jpg
├── 0000_c1_0002.jpg
├── query
├── 0000_c1_0000.jpg
├── 0000_c1_0001.jpg
├── 0000_c14_0030.jpg
评估协议
按照训练-测试为1:3的比例对数据集进行随机划分,而不是像其他数据集一样均等划分。这样做的目的是鼓励高效率的训练策略,由于在真实应用中标注数据的昂贵。
最后,训练集包含1041个行人共32621个包围框,而测试集包括3060个行人共93820个包围框。对于测试集,11659个包围框被随机选出来作为query,而其它82161个包围框作为gallery.
测试指标为CMC曲线和mAP. 对于每个query, 可能存在多个正匹配。
论文链接:https://arxiv.org/pdf/1711.08565.pdf
下载链接
- https://www.pkuvmc.com/publications/msmt17.html
- 链接:https://pan.baidu.com/s/19-cKxL_UVKNHc7kqqp0GVg
提取码:yf3z - MSMT17_v2数据集:
链接: https://pan.baidu.com/s/1GmOuIrrr3Le3oHNpLWYYaw 提取码: i37k
RPIfield
RPIfield是一个重新识别数据集,它为每个人提供了明确的时间戳信息,从而帮助评估基于它们在由越来越多的候选人(其中一些人可能在很长一段时间内多次返回)填充的动态图库上的时间性能的重新识别算法。
Zheng, Meng and Karanam, Srikrishna and Radke, Richard J. “RPIfield: A New Dataset for Temporally Evaluating Person Re-Identification.” CVPR Workshops (2018)
下载链接
链接:https://pan.baidu.com/s/1udVyNT-VRyLBd8sZA-WpJw 提取码:ckhp
LPW
LPW 全称 Labeled Pedestrian in the Wild,是一个行人检测数据集。该数据集包含三个不同的场景,共 2,731 名行人,其中每一个行人图片由 2 到 4 台摄像机拍摄。 LPW 的显着特征是:包含 7,694 个 tracklets,超过 590,000 个图像。

下载链接
https://liuyu.us/dataset/lpw/index.html
PKU Sketch-ReID
介绍
这个数据集包含200个人,每个人都有一幅素描和两张照片。每个人的照片都是在白天由两台交叉视角相机拍摄的。原始图像(或视频帧)是手动裁剪的,以确保每张照片都包含一个特定的人。所有人的速写由5位艺术家绘制,每个艺术家都有自己的画风。

下载链接
https://www.pkuml.org/resources/pkusketchreid-dataset.html
链接: https://pan.baidu.com/s/1-XPCWH_acnEkP-jrt6Gs6w 提取码: 4szc
ThermalWorld
这是一个具有热彩色图像对的跨模态re-id数据集。提供了像素级注释。

下载链接
http://www.zefirus.org/articles/ee9462fb-befd-4679-9c26-acd551db8583/
https://github.com/vlkniaz/ThermalGAN
SYSU-30k 数据集
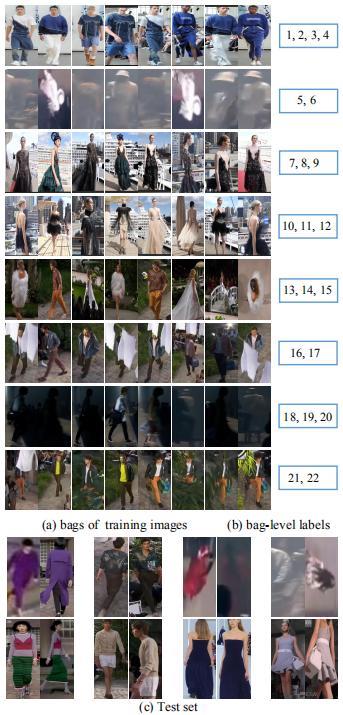
目前没有公开发布的「弱监督」行人重识别数据集。为了填补这个空白,研究者收集了一个新的大规模行人重识别数据 SYSU-30k,为未来行人重识别研究提供了便利。他们从网上下载了许多电视节目视频。考虑电视节目视频的原因有两个:第一,电视节目中的行人通常是跨摄像机视角,它们是由多个移动的摄像机捕捉得到并经过后处理。因此,电视节目的行人识别是一个真实场景的行人重识别问题;第二,电视节目中的行人非常适合标注。在 SYSU-30k 数据集中,每一个视频大约包含 30.5 个行人。
研究者最终共使用的原视频共 1000 个。标注人员利用弱标注的方式对视频进行标注。具体地,数据集被切成 84,930 个袋,然后标注人员记录每个袋包含的行人身份。他们采用 YOLO-v2 进行行人检测。三位标注人员查看检测得到的行人图像,并花费 20 天进行标注。最后,29,606,918(≈30M)个行人检测框共 30,508(≈30k)个行人身份被标注。研究者选择 2,198 个行人身份作为测试集,剩下的行人身份作为训练集。训练集和测试集的行人身份没有交叠。
SYSU-30k 数据集的一些样例如下图所示。可以看到,SYSU-30k 数据集包含剧烈的光照变化(第 2,7,9 行)、遮挡(第 6,8 行)、低像素(第 2,7,9 行)、俯视拍摄的摄像机(第 2,5,6,8,9 行)和真实场景下复杂的背景(第 2-10 行)。
下载链接
论文地址:https://arxiv.org/pdf/1904.03845.pdf
代码、模型和数据集:https://github.com/wanggrun/SYSU-30k
PETA 远距离行人识别数据集
PETA 全称 The PEdes Trian Attribute dataset,是用于远距离识别行人属性的图像数据集。比如远距离识别性别和服装风格。该数据集包含了 8,705 个行人、65 个属性(61 个二类属性和 4 个多类属性)和 19,000 张图像。

下载链接
链接:https://pan.baidu.com/s/1pJJ4OFdYeO-G5UKKIxqBqQ
提取码:a66v
以上是关于行人重识别数据集汇总的主要内容,如果未能解决你的问题,请参考以下文章