❤️数据科学-PandasNumpyMatplotlib秘籍之精炼总结
Posted Super__Tiger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️数据科学-PandasNumpyMatplotlib秘籍之精炼总结相关的知识,希望对你有一定的参考价值。
前言:

先感受一下数据科学的魅力,上图是在Smart Dubai 2017 GITEX科技周展台上推出Smart Decision-Making Platform(智能决策平台),于10月8日至12日在迪拜世界贸易中心举行。游客可以通过一个“沉浸式的空间”将数据可视化,让他们了解迪拜的未来。让参观者可以在现场查阅观看全市数据,这意味着迪拜将成为了世界上第一个与公众分享实时实时数据的城市,同时还可以预测未来十年的发展。
最近,很多小伙伴在后台私信我,咨询有没有数据处理及可视化的相关系统教程?我的回复是,这些库只是工具,无需花费很长的时间牢记这些命令的使用,学习一遍之后整理好笔记即可,遗忘之时再查找这些笔记使用即可。
本文是博主本人结合自己的使用经验以及各大博主的分享精炼汇总而成,耗时进半个月的时候,翻阅博客和参考资料无数,最后精选了最实用、常用、好用的“Pandas、Numpy、Matplotlib”三大神兵利器的方法使用攻略。

文章目录
- 前言:
- Pandas精炼总结
- 1.属性值中存在缺失,将变量转换成Pandas可操作类型数据的方法
- 2.为数据表格添加颜色特性,实现更好可视化的方法
- 3.Pandas中数值实现函数映射转换的方法
- 4.属性值中出现长列表或字符串形式的数据,实现分割处理的方法
- 5.DataFrame数据之间拼接的方法
- 6.DataFrame数据转置的方法
- 7.统计属性的数值分布频率的方法
- 8.Pandas替换异常值的方法
- 9.Pandas筛选数据的方法
- 10.DataFrame数据之间合并的方法
- 11.Pandas删除重复项的方法
- 12.Pandas数据排序的方法
- 13.Pandas数据采样的方法
- 14.Pandas判断和删除缺失值的方法
- 15.Pandas指定条件下值替换的方法
- Numpy精炼总结
- Matplotlib精炼总结
Pandas精炼总结
1.属性值中存在缺失,将变量转换成Pandas可操作类型数据的方法
当某个属性数据中存在空值(NaN),则该属性数据类型为object,使用convert_dtypes()将Series转换为支持的dtypes。
1.convert_dtypes()处理DataFrame类型数据,示例如下:
# dataframe 变量类型自动转换
df = pd.DataFrame(
"a": pd.Series([1, 2, 3], dtype=np.dtype("int32")),
"b": pd.Series(["x", "y", "z"], dtype=np.dtype("O")),
"c": pd.Series([True, False, np.nan], dtype=np.dtype("O")),
"d": pd.Series(["h", "i", np.nan], dtype=np.dtype("O")),
"e": pd.Series([10, np.nan, 20], dtype=np.dtype("float")),
"f": pd.Series([np.nan, 100.5, 200], dtype=np.dtype("float")),
)
print(df.dtypes)
dfn = df.convert_dtypes()
print(dfn.dtypes)
2.convert_dtypes()处理Series变量类型数据,示例如下:
# Series 变量类型自动转换
s = pd.Series(["a", "b", np.nan])
print(s.dtypes)
sn = s.convert_dtypes()
print(sn.dtypes)
2.为数据表格添加颜色特性,实现更好可视化的方法
pandas可通过添加颜色条件,让表格数据凸显出统计特性。
import pandas as pd
df = pd.read_csv("test.csv")
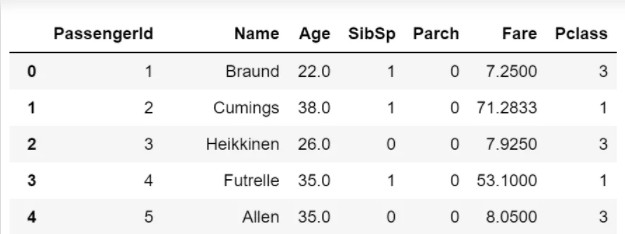
1.Fare变量值呈现条形图,以清楚看出各个值得大小比较,可直接使用bar,示例如下:
df.style.bar("Fare",vmin=0)
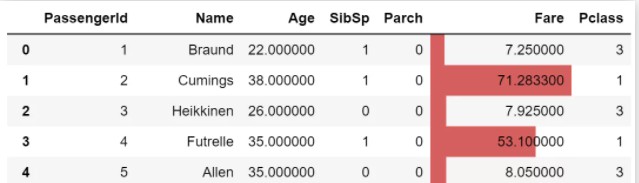
2.让Age变量呈现背景颜色的梯度变化,以体验映射的数值大小,那么可直接使用background_gradient,深颜色代表数值大,浅颜色代表数值小,示例如下:
df.style.background_gradient("Greens",subset="Age")
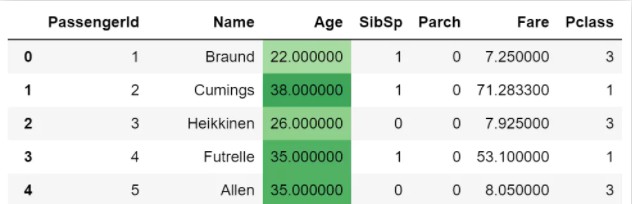
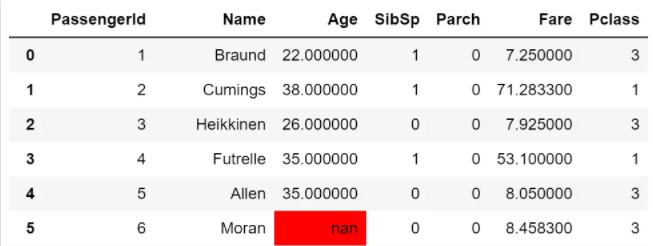
3.让所有缺失值都高亮出来,可使用highlight_null,示例如下:
df.style.highlight_null()
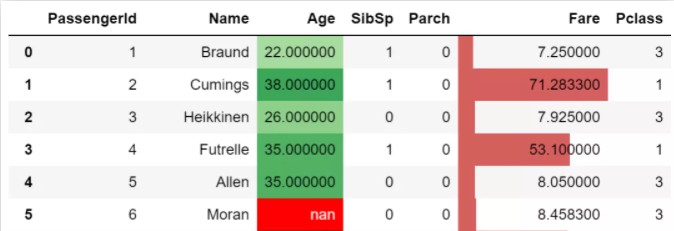
4.pandas的style条件格式,组合用法非常简单,示例如下:
df.style.bar("Fare",vmin=0).background_gradient("Greens",subset="Age").highlight_null()
3.Pandas中数值实现函数映射转换的方法
使用pd.transform(func,axis)函数:
func是指定用于处理数据的函数,它可以是普通函数、字符串函数名称、函数列表或轴标签映射函数的字典。axis是指要应用到哪个轴,0代表列,1代表行。
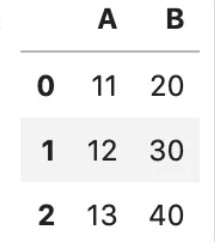
1.func=“普通函数”,示例如下:
df = pd.DataFrame('A': [1,2,3], 'B': [10,20,30] )
def plus_10(x):
return x+10
df.transform(plus_10)
# df.transform(lambda x: x+10) 等价写法
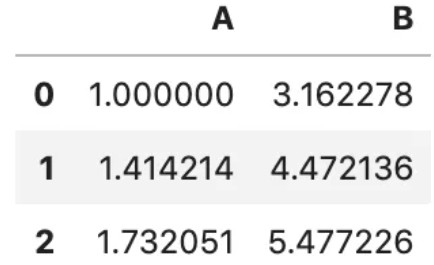
2.func=“内置的字符串函数”,示例如下:
df = pd.DataFrame('A': [1,2,3], 'B': [10,20,30] )
df.transform('sqrt')
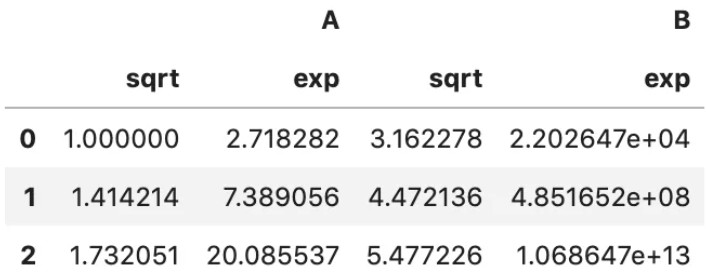
3.func=“多个映射函数”,示例如下:
df = pd.DataFrame('A': [1,2,3], 'B': [10,20,30] )
df.transform([np.sqrt, np.exp])
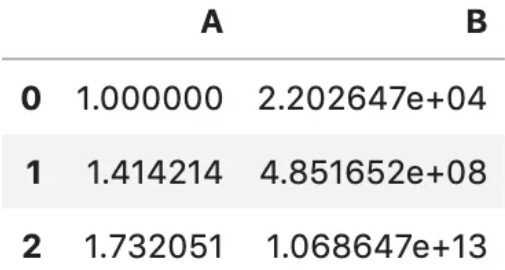
4.func=“指定轴位置的映射函数”,示例如下:
df = pd.DataFrame('A': [1,2,3], 'B': [10,20,30] )
df.transform(
'A': np.sqrt,
'B': np.exp,
)
4.属性值中出现长列表或字符串形式的数据,实现分割处理的方法
工作中,比如用户画像的数据中也会遇到,客户使用的app类型就会以这种长列表的形式或者以逗号隔开的字符串形式展现出来。

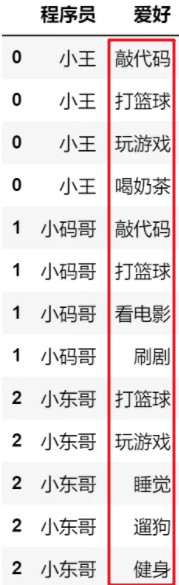
1.使用explode()这个方法即可,一般我们会在后面跟一个去重的方法,explode()支持列表、元组、Series和numpy的ndarray类型数据,示例如下:
df.explode('爱好').drop_duplicates()
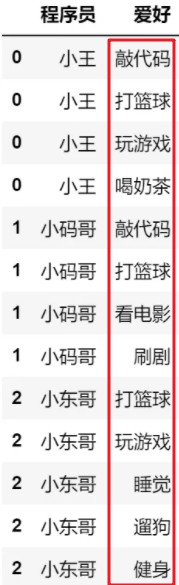
2.当长数据不是explode能够处理的数据类型时,使用Series.str.split()分割字符串的方法将其转换为列表格式后处理,然后再进行explode即可,示例如下:

df["爱好"] = df["爱好"].str.split()

df.explode('爱好').drop_duplicates()
5.DataFrame数据之间拼接的方法
源数据如下:
df1 = pd.DataFrame(
'name':['A','B','C','D'],
'math':[60,89,82,70],
'physics':[66, 95,83,66],
'chemistry':[61,91,77,70]
)
df2 = pd.DataFrame(
'name':['E','F','G','H'],
'math':[66,95,83,66],
'physics':[60, 89,82,70],
'chemistry':[90,81,78,90]
)
1.默认情况下,它是沿axis=0垂直连接的,并且默认情况下会保留df1和df2原来的索引。
pd.concat([df1,df2])
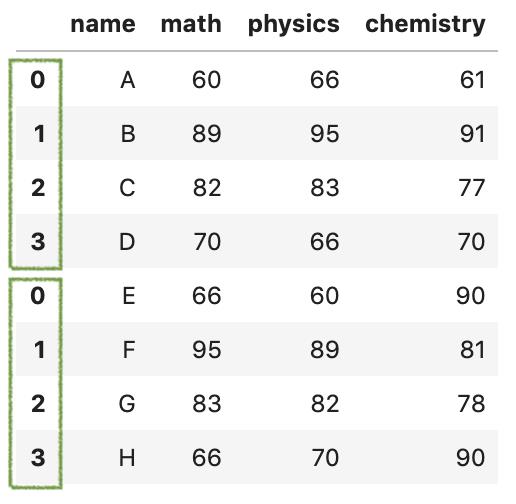
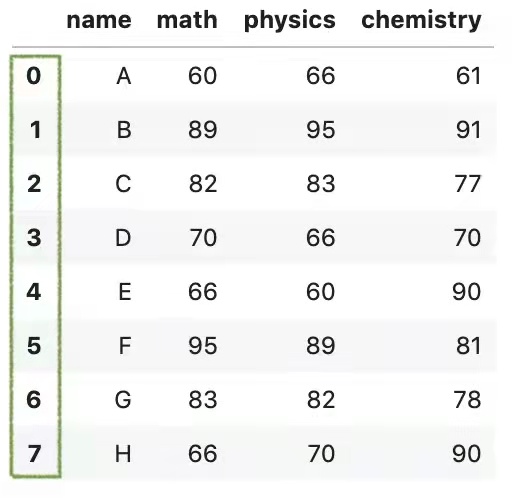
2.可以通过设置参数ignore_index=True,这样索引就可以从0到n-1自动排序了。
pd.concat([df1,df2],ignore_index = True)
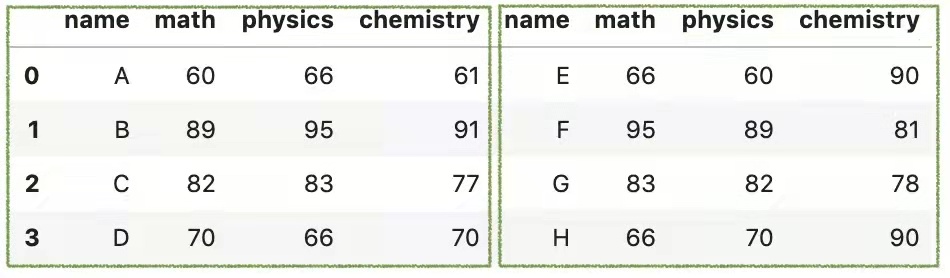
3.如果想要沿水平轴连接两个DataFrame,可以设置参数axis=1。
pd.concat([df1,df2],axis = 1)
4.可以通过设置参数verify_integrity=True,将此设置True为时,如果存在重复的索引,将会报错。
pd.concat([df1,df2], verify_integrity=True)

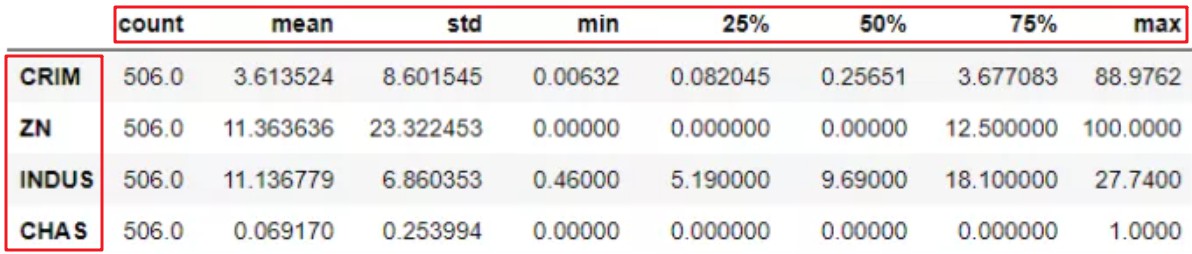
6.DataFrame数据转置的方法
dataframe都有的一个简单属性,实现转置功能。它在显示describe时可以很好的搭配。
boston.describe().T.head(10)
7.统计属性的数值分布频率的方法
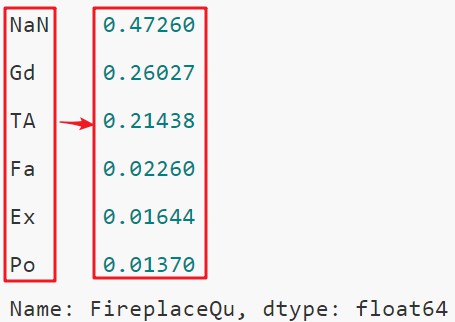
在数据探索的时候,value_counts是使用很频繁的函数,它默认是不统计空值的,但空值往往也是我们很关心的。如果想统计空值,可以将参数dropna设置为False。
ames_housing = pd.read_csv("data/train.csv")
print(ames_housing["FireplaceQu"].value_counts(dropna=False, normalize=True))
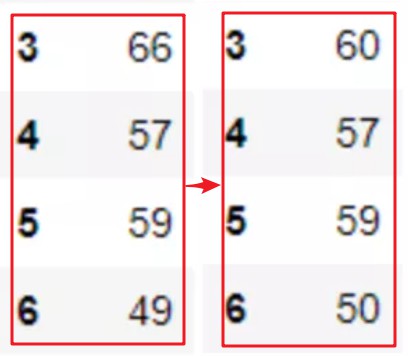
8.Pandas替换异常值的方法
异常值检测是数据分析中常见的操作。使用clip函数可以很容易地找到变量范围之外的异常值,并替换它们。
age.clip(50, 60)
9.Pandas筛选数据的方法
源数据如下:
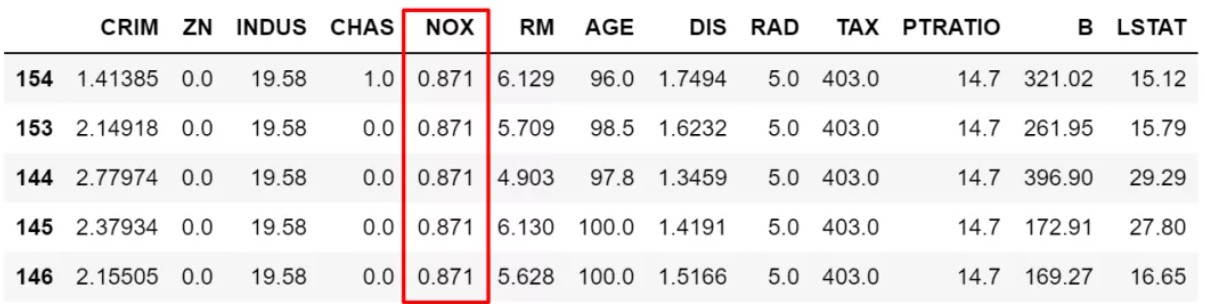
1.直接在dataframe的[]中写筛选的条件或者组合条件,示例如下:
# 筛选出大于NOX这变量平均值的所有数据,然后按NOX降序排序。
df[df['NOX']>df['NOX'].mean()].sort_values(by='NOX',ascending=False).head()
#筛选出大于NOX这变量平均值且CHAS属性值=1的所有数据,然后按NOX降序排序。
df[(df['NOX']>df['NOX'].mean())& (df['CHAS'] ==1)].sort_values(by='NOX',ascending=False).head()
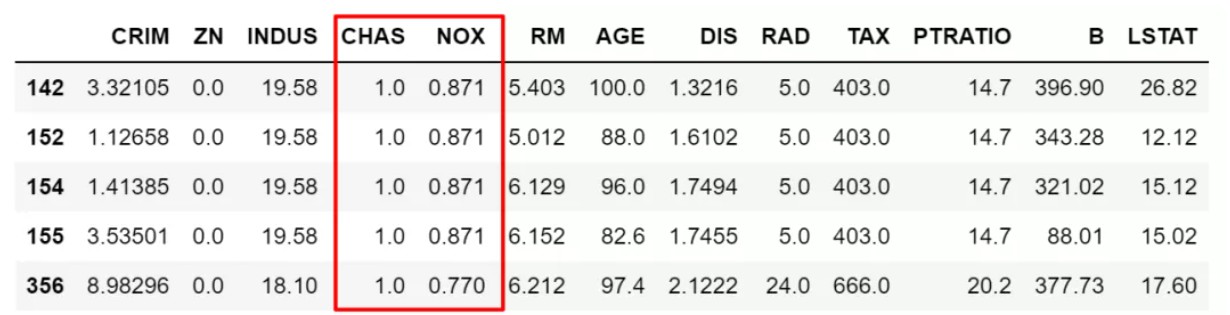
2.loc按标签值(列名和行索引取值)访问,iloc按数字索引访问,均支持单值访问或切片查询,loc还可以指定返回的列变量,示例如下:
# 按df['NOX']>df['NOX'].mean()条件筛选出数据,并筛选出指定CHAS变量,然后赋值=2
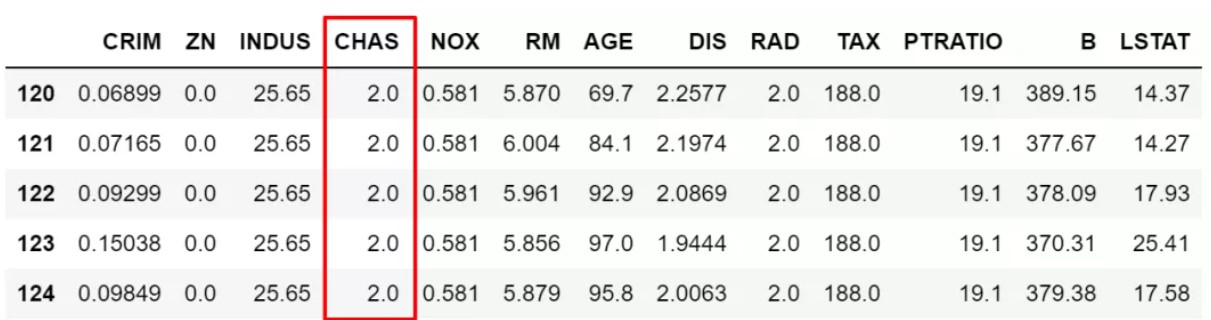
df.loc[(df['NOX']>df['NOX'].mean()),['CHAS']] = 2
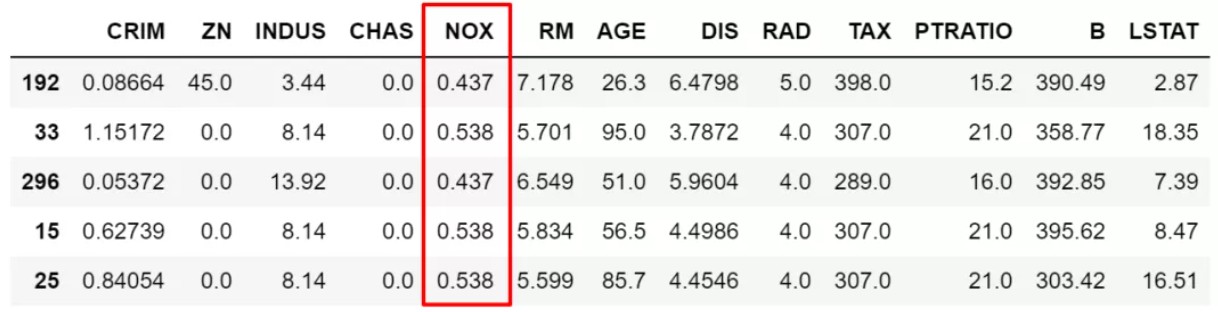
3.需要锁定某些具体的值的,这时候就需要isin了。比如我们要限定NOX取值只能为0.538,0.713,0.437中时,示例如下:
df.loc[df['NOX'].isin([0.538,0.713,0.437]),:].sample(5)
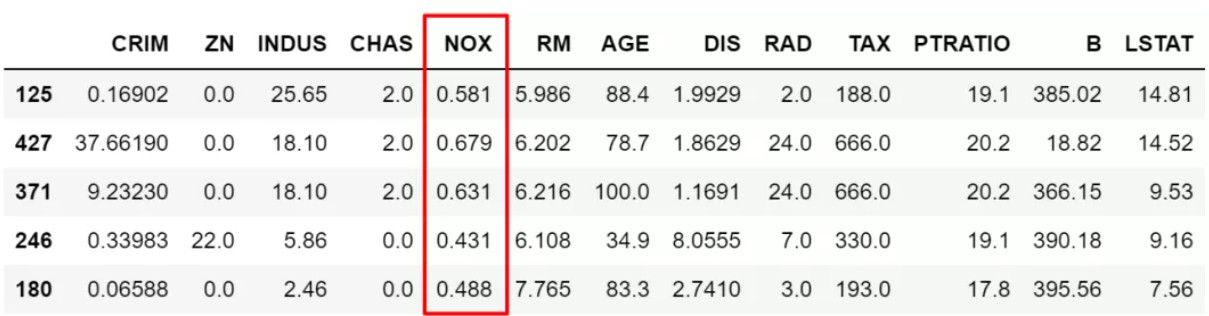
# 也可以做取反操作,在筛选条件前加`~`符号
df.loc[~df['NOX'].isin([0.538,0.713,0.437]),:].sample(5)
4.pandas里实现字符串的模糊筛选,可以用.str.contains()来实现,示例如下:
train.loc[train['Name'].str.contains('Mrs|Lily'),:].head()

10.DataFrame数据之间合并的方法
merge():对于拥有相同的键的两个DataFrame对象,需要将其进行有效的拼接,整合到一个对象。
def merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
主要参数介绍:
- left:DataFrame对象;
- right:DataFrame对象;
- how:
连接方式,inner或outer,默认是outer; - on:
指定用于连接的键,必须存在于左右两个DataFrame中; - left_on:左侧DataFrame中用于连接键的列名,当左右对象列名不同但含义相同时使用;
- right_on:右侧DataFrame中用于连接键的列名;
- left_index:
使用左侧DataFrame的行索引作为连接键(配合right_on); - right_index:使用右侧DataFrame的行索引作为连接键(配合left_on);
- sort:
对其按照连接键进行排序;
源数据为:
df1 = pd.DataFrame(np.random.randint(10, size=(3, 3)), columns=['A', 'B', 'C'])
df2 = pd.DataFrame(np.random.randint(10, size=(2, 2)), columns=['A', 'B'])
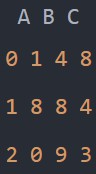
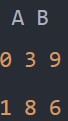
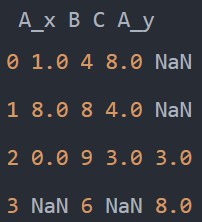
pd.merge(df1, df2, how='outer', on='B')
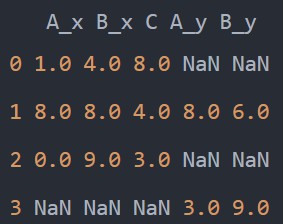
pd.merge(df1, df2, how='outer', left_on='B', right_on='A')
11.Pandas删除重复项的方法
1.drop_duplicates():删除对象dataframe中重复的行,重复通过参数subset指定。
def drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
主要参数介绍:
- subset:指定的键(列),
默认为所有的列(即每行全部相同); - keep:
删除重复项,除了第1个(first)或者最后一个(last); - inplace:是否直接对原来的对象进行修改,默认为False,生成一个拷贝`;
- ignore_index:是否重建索引;
df1 = pd.DataFrame(np.random.randint(10, size=(3, 3)), columns=['A', 'B', 'C'])
df1.drop_duplicates('A')
2.unique():相比于drop_duplicates方法,unique()只针对于Series对象,类似于Set。 通常是对dataframe中提取某一键,变成Series,再去重,统计个数。
print(len(df1['A'].unique().tolist()))
12.Pandas数据排序的方法
sort_values():按照某个键进行排序。 查看相同键时行的某些变化,如例子中在A相同时B、C的变化。
def sort_values(by, axis=0, ascending=True, kind='quicksort', na_position='last', ignore_index=False)
主要参数介绍:
- by:字符串或字符串列表,
指定按照哪个键/索引进行排序; - axis:指定排序的轴;
- ascending:升序或降序,
默认为升序; - kind:
指定排序方法,‘quicksort’, ‘mergesort’, ‘heapsort; - ignore_index:是否重建索引;
df1.sort_values(by='A')
13.Pandas数据采样的方法
sample():对对象进行采样。 当dataframe对象数据量太大,导致做实验过满时,可以抽取一部分进行实验,提高效率。
def sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
主要参数介绍:
- n:指定采样的数量;
- frac:指定采样的比例,与n只能选择其中一个;
- replace:
允许或不允许对同一行进行多次采样; - weights:
采样的权重,默认为“None”将导致相同的概率权重; - random_state:类似于seed作用;
- axis:
指定采样的轴,默认为行;
df1.sample(n=3)
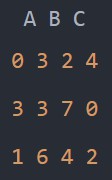
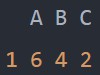
df1.sample(frac=0.1)
14.Pandas判断和删除缺失值的方法
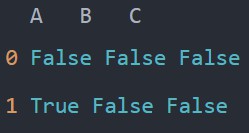
1.isna():isna方法返回一个布尔对象,每个元素是否为NaN。
df1.isna()
2.isnull():当数据量很大时,上述很难观察到某列是否存在缺失,此时可以用isnull()方法 。
df1.isnull().all() # 某列是否全部为NaN
df1.isnull().any() # 某列是否出现NaN
3.dropna():dropna方法删除含缺失值的行或列。
def dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
主要参数介绍:
- axis:指定轴;
- how:
参数为any时,行或列(axis决定)出现NaN时,就进行删除;为all时,行或列全为NaN时才进行删除; - thresh:阈值,要求不为NAN的个数;
- subset:
指定键(列)进行判断NAN删除; - inplace:
是否更改原对象;
df1.dropna(以上是关于❤️数据科学-PandasNumpyMatplotlib秘籍之精炼总结的主要内容,如果未能解决你的问题,请参考以下文章
❤️数据科学-PandasNumpyMatplotlib秘籍之精炼总结
❤️数据科学-PandasNumpyMatplotlib秘籍之精炼总结
从❤️庄周梦蝶❤️的寓言故事中感悟出一个科学真理:真假之间只相差一个 e^(iπ)