wandb不可缺少的机器学习分析工具
Posted 修炼之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了wandb不可缺少的机器学习分析工具相关的知识,希望对你有一定的参考价值。
wandb
wandb全称Weights & Biases,用来帮助我们跟踪机器学习的项目,通过wandb可以记录模型训练过程中指标的变化情况以及超参的设置,还能够将输出的结果进行可视化的比对,帮助我们更好的分析模型在训练过程中的问题,同时我们还可以通过它来进行团队协作
wandb会将训练过程中的参数,上传到服务器上,然后通过登录wandb来进行实时过程模型训练过程中参数和指标的变化

wandb的特点
- 保存模型训练过程中的超参数
- 实时可视化训练过程中指标的变化
- 分析训练过程中系统指标(CPU/GPU的利用率)的变化情况
- 和团队协作开发
- 复现历史结果
- 实验记录的永久保留
- wandb可以很容易的集成到各个深度学习框架中(Pytorch、Keras、Tensorflow等)
wandb的组成模块
wandb主要由四大模块组成,分别是:
- 仪表盘:跟踪实验分析可视化结果
- 报告:保存和分析可复制的实验结果
- Sweeps:通过调节超参数来优化模型
- Artifacts:数据集和模型版本化,流水线跟踪
wandb账号注册
- 安装wandb
pip install wandb
-
注册wandb账号
在使用wandb之前,我们需要先注册一个免费账号 -
拷贝
API keys
在网站上登录wandb,点击Settings
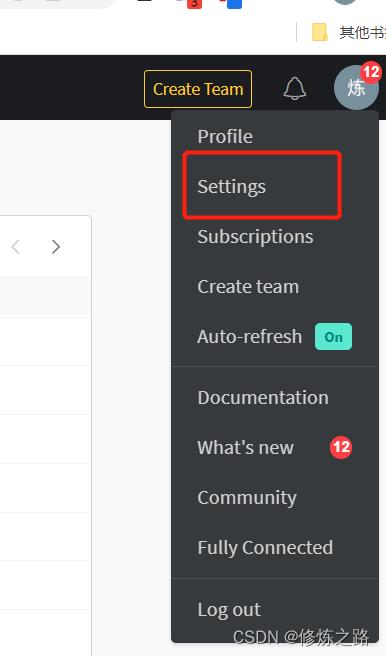
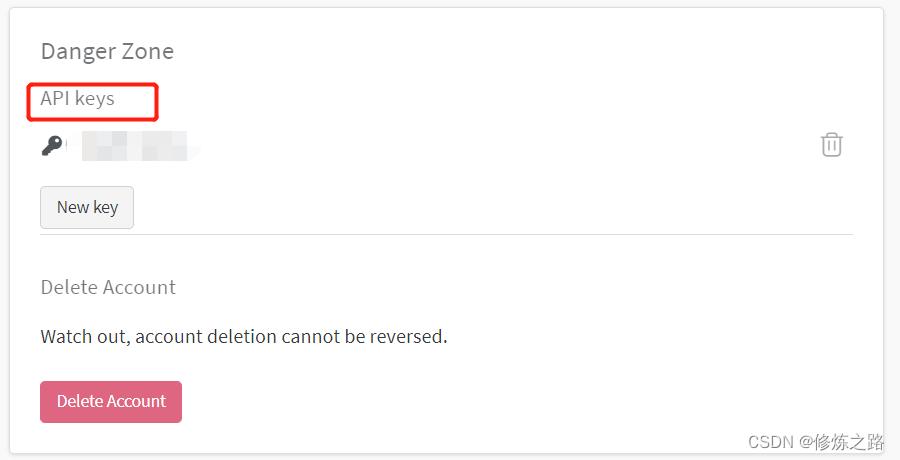
滚动到最下面,找到API Keys进行复制
在torch中嵌入wandb
这部分我们主要介绍如何在torch中使用wandb,这里我们以训练MNIST为例
- 导包
import argparse
import random
import numpy
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import logging
logging.propagate = False
logging.getLogger().setLevel(logging.ERROR)
import wandb
- 登录wandb
wandb.login(key="填入你的API Keys")
- 定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
- 定义训练方法
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
if batch_idx > 20:
break
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
- 定义验证方法
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
best_loss = 1
example_images = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
example_images.append(wandb.Image(
data[0], caption="Pred: Truth: ".format(pred[0].item(), target[0])))
#通过wandb来记录模型在测试集上的Accuracy和Loss
wandb.log(
"Examples": example_images,
"Test Accuracy": 100. * correct / len(test_loader.dataset),
"Test Loss": test_loss)
- 训练模型
# 定义项目在wandb上保存的名称
wandb.init(project="pytorch-mnist")
wandb.watch_called = False
# 在wandb上保存超参数
config = wandb.config
config.batch_size = 4
config.test_batch_size = 10
config.epochs = 50
config.lr = 0.1
config.momentum = 0.1
config.no_cuda = False
config.seed = 42
config.log_interval = 10
def main():
use_cuda = not config.no_cuda and torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = 'num_workers': 1, 'pin_memory': True if use_cuda else
random.seed(config.seed)
torch.manual_seed(config.seed)
numpy.random.seed(config.seed)
torch.backends.cudnn.deterministic = True
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=config.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=config.test_batch_size, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=config.lr,
momentum=config.momentum)
#记录模型层的维度,梯度,参数信息
wandb.watch(model, log="all")
for epoch in range(1, config.epochs + 1):
train(config, model, device, train_loader, optimizer, epoch)
test(config, model, device, test_loader)
#保存模型
torch.save(model.state_dict(), "model.h5")
#在wandb上保存模型
wandb.save('model.h5')
if __name__ == '__main__':
main()
查看训练的结果
- 登录到wandb的网站上查看训练结果
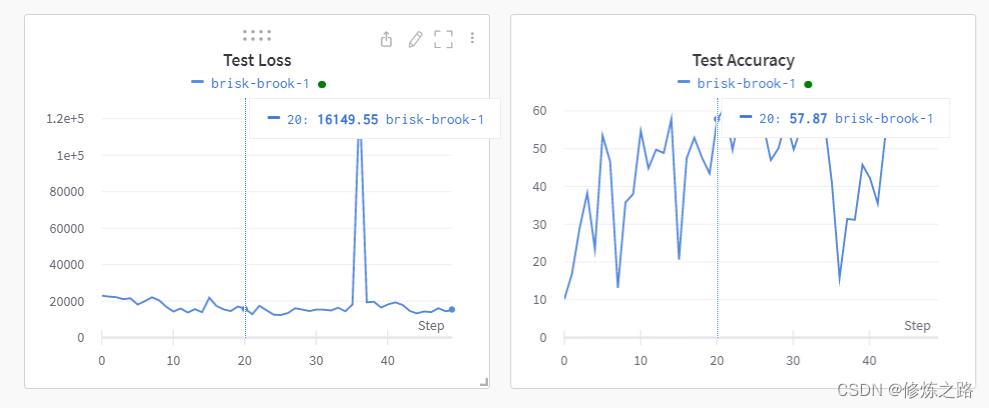
- 查看模型在测试集上
Accuracy和loss的变化
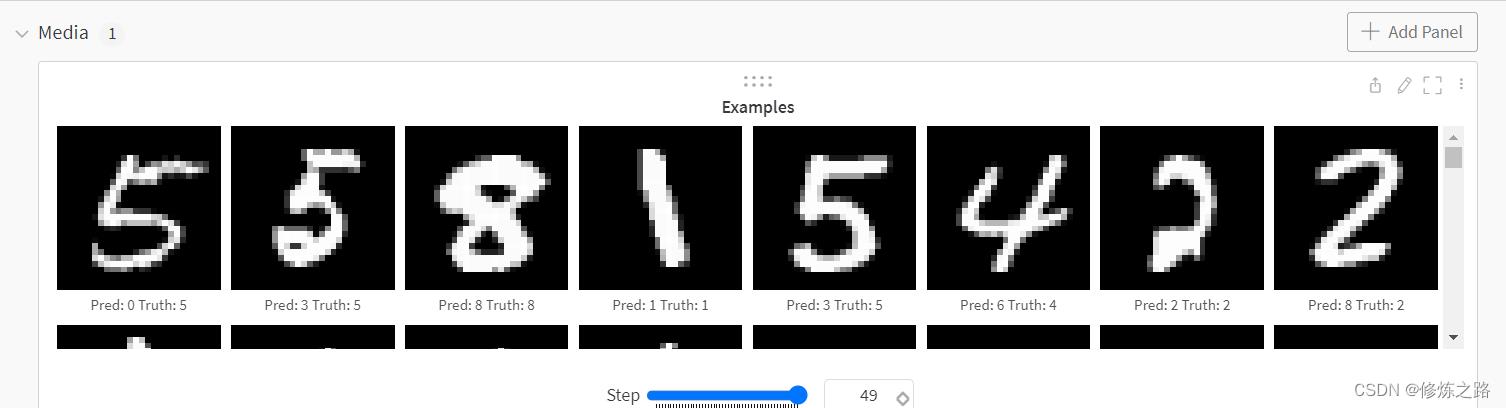
- 查看模型的预测效果
- 查看训练过程中系统参数(GPU和CPU等)的变化情况

参考
以上是关于wandb不可缺少的机器学习分析工具的主要内容,如果未能解决你的问题,请参考以下文章