机器学习聚类算法
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习聚类算法相关的知识,希望对你有一定的参考价值。
目录
1 认识聚类算法
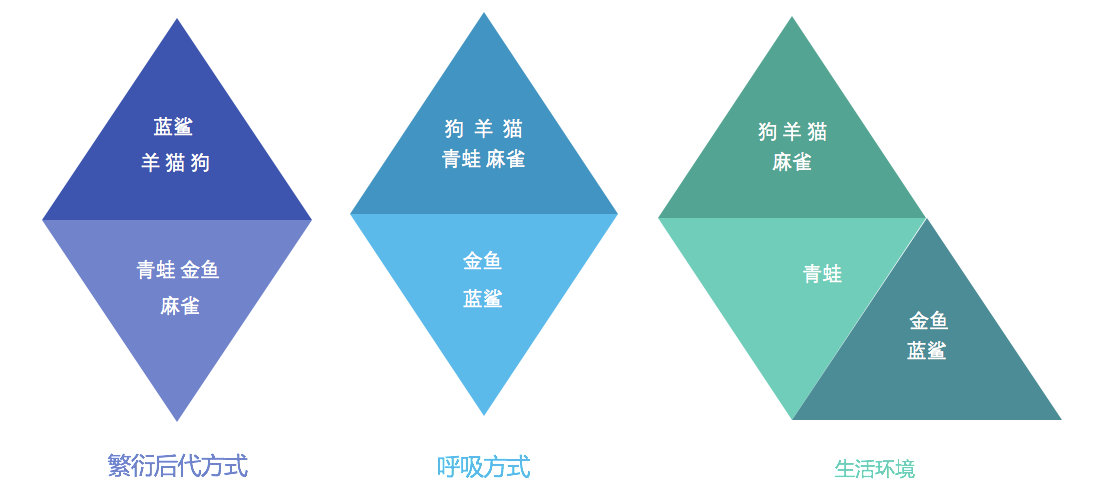
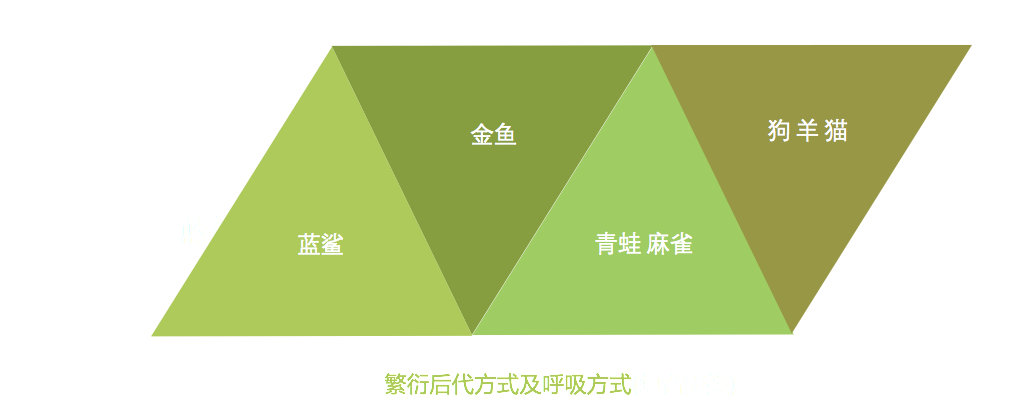
使用不同的聚类准则,产生的聚类结果不同。
1.1 聚类算法在现实中的应用
- 用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别
- 基于位置信息的商业推送,新闻聚类,筛选排序
- 图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段

1.2 聚类算法的概念
聚类算法:
一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
1.3 聚类与分类最大的区别
聚类算法是无监督的学习算法,而分类算法属于监督的学习算法。
1.4 小结
- 聚类算法分类【了解】
- 粗聚类
- 细聚类
- 聚类的定义【了解】
- 一种典型的无监督学习算法,
- 主要用于将相似的样本自动归到一个类别中
- 计算样本和样本之间的相似性,一般使用欧式距离
2 聚类算法api初步使用
2.1 api介绍
- sklearn.cluster.KMeans(n_clusters=8)
- 参数:
- n_clusters:开始的聚类中心数量
- 整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数。
- n_clusters:开始的聚类中心数量
- 方法:
- estimator.fit(x)
- estimator.predict(x)
- estimator.fit_predict(x)
- 计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
- 参数:
2.2 案例
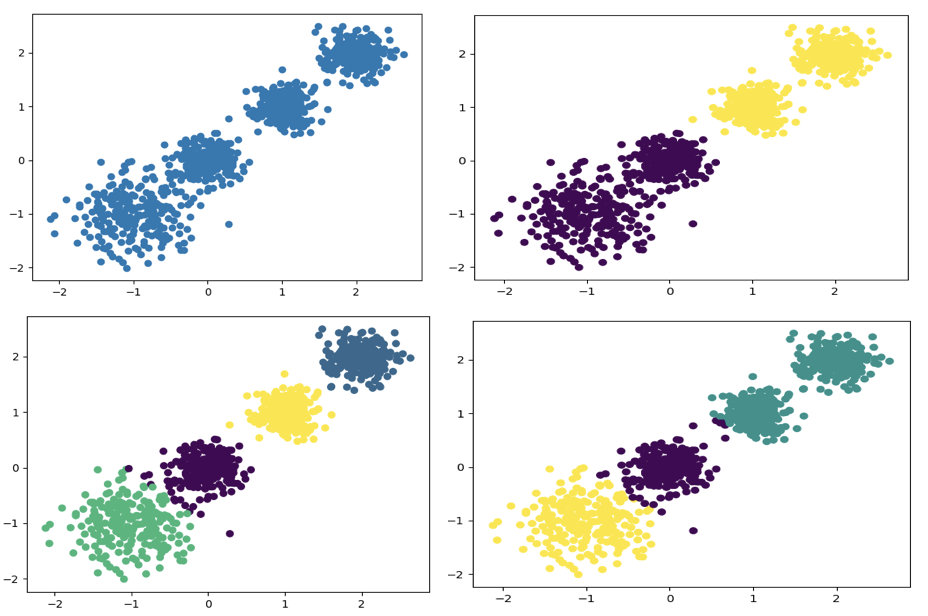
随机创建不同二维数据集作为训练集,并结合k-means算法将其聚类,你可以尝试分别聚类不同数量的簇,并观察聚类效果:

聚类参数n_cluster传值不同,得到的聚类结果不同
2.2.1流程分析
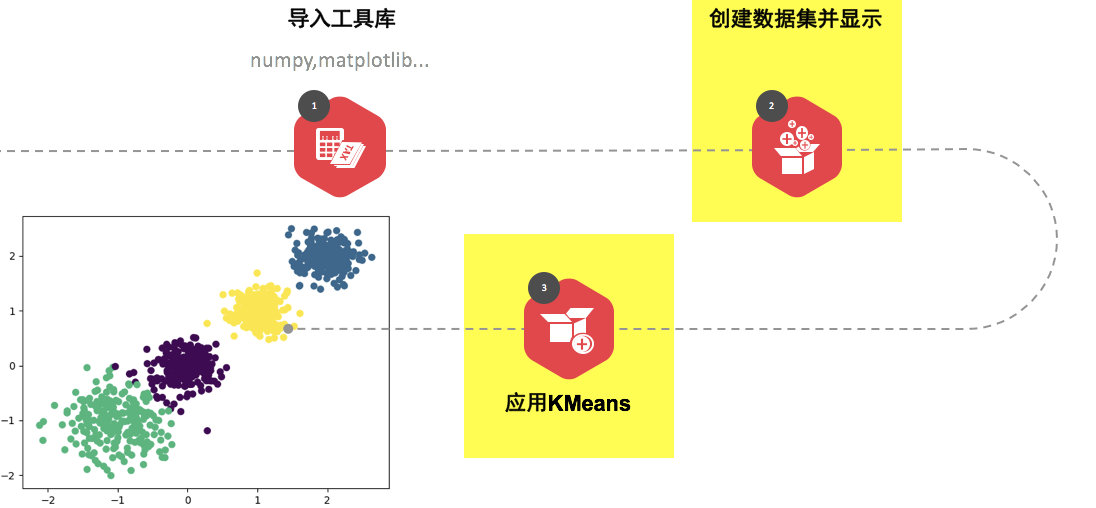
2.2.2 代码实现
1.创建数据集
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabaz_score
# 创建数据集
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共4个簇,
# 簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state=9)
# 数据集可视化
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
2.使用k-means进行聚类,并使用CH方法评估
y_pred = KMeans(n_clusters=2, random_state=9).fit_predict(X)
# 分别尝试n_cluses=2\\3\\4,然后查看聚类效果
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
# 用Calinski-Harabasz Index评估的聚类分数
print(calinski_harabaz_score(X, y_pred))
2.3 小结
- api:sklearn.cluster.KMeans(n_clusters=8)【知道】
- 参数:
- n_clusters:开始的聚类中心数量
- 方法:
- estimator.fit_predict(x)
- 计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
- estimator.fit_predict(x)
- 参数:
3 聚类算法实现流程
3.1 k-means聚类步骤
- 1、随机设置K个特征空间内的点作为初始的聚类中心
- 2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程
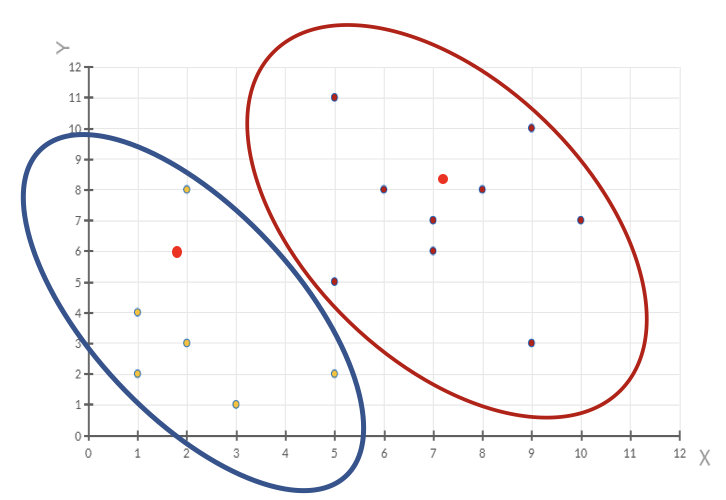
通过下图解释实现流程:

k聚类动态效果图

3.2 案例练习
- 案例:
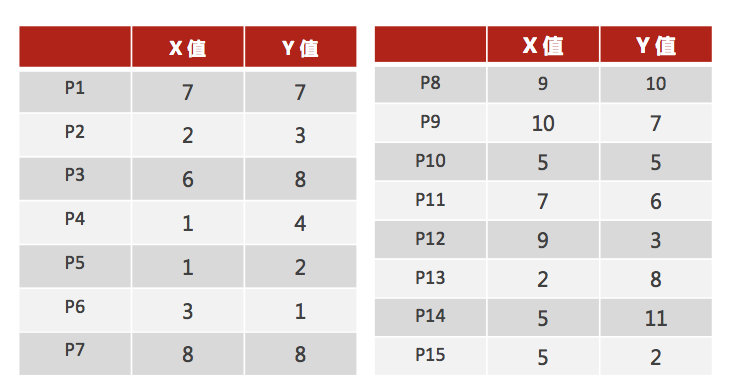
- 1、随机设置K个特征空间内的点作为初始的聚类中心(本案例中设置p1和p2)
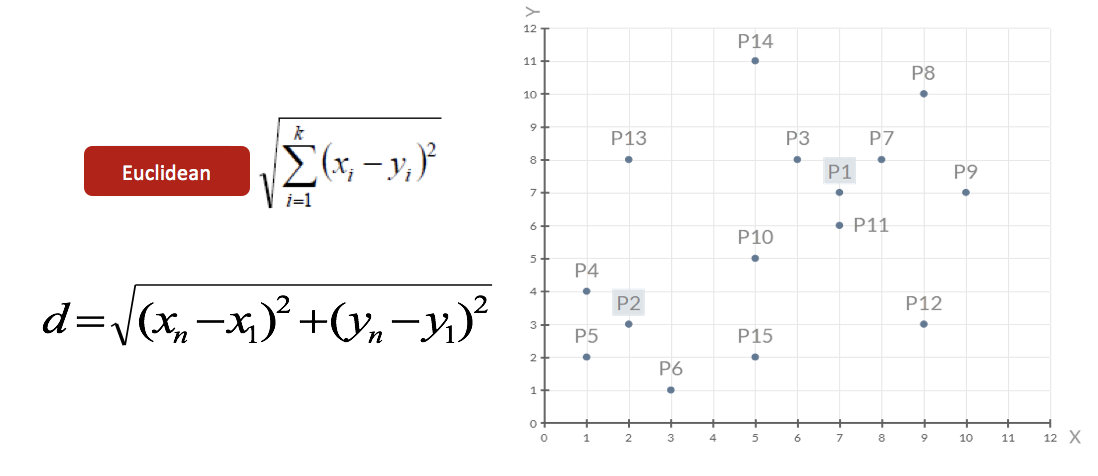
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
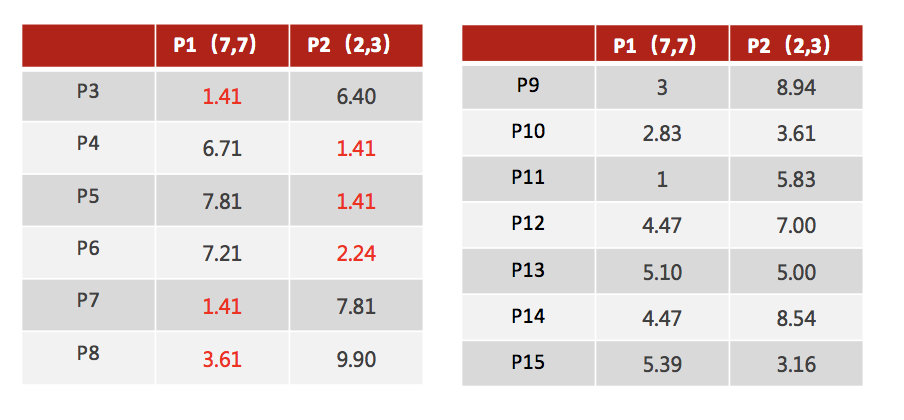
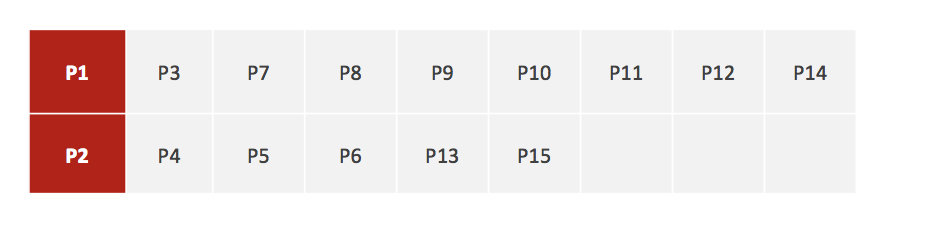
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)

4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程【经过判断,需要重复上述步骤,开始新一轮迭代】


5、当每次迭代结果不变时,认为算法收敛,聚类完成,K-Means一定会停下,不可能陷入一直选质心的过程。
3.3 小结
-
K-means聚类实现流程
【掌握】
-
事先确定常数K,常数K意味着最终的聚类类别数;
-
随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,
-
接着,重新计算每个类的质心(即为类中心),重复这样的过程,直到质心不再改变,
-
最终就确定了每个样本所属的类别以及每个类的质心。
-
注意
:
- 由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。
-
以上是关于机器学习聚类算法的主要内容,如果未能解决你的问题,请参考以下文章