最近质心
Posted azheng333
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最近质心相关的知识,希望对你有一定的参考价值。
算法很简单,取训练样本每种类别的平均值当做聚类中心点,待分类的样本离哪个中心点近就归属于哪个聚类 。
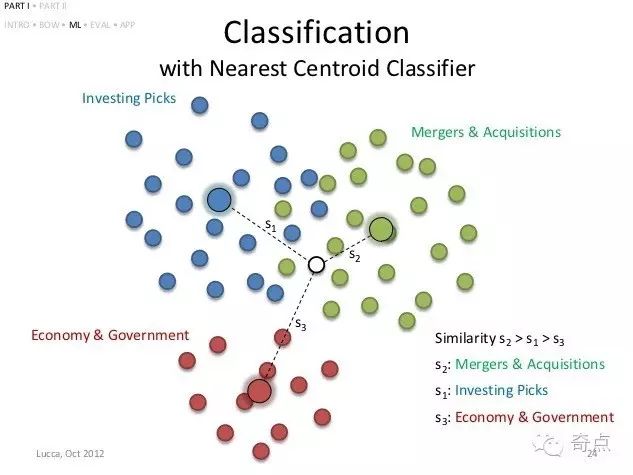
在《白话大数据与机器学习》里使用了sklearn里的NearestCentroid来处理数据:
训练模型 clf = NearestCentroid().fit(x, y)
预测数据 clf.predict(x)
这里我们来实现一下最近的质心算法,看看该算法具体是如果实现的。
1 准备数据
首先我们需要一些训练数据 这里使用鸢尾花数据 https://en.wikipedia.org/wiki/Iris_flower_data_set。
这里x是一个(150, 4)2维数组,总共150条数据,打印其中的5条数据看一下:
[[5.1, 3.5, 1.4, 0.2],
[4.9, 3.0, 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5.0, 3.6, 1.4, 0.2],
... ...]
可以看到每条数据都有4个特征项分别是: 萼片的长度,萼片的宽度,花瓣的长度,花瓣的宽度
y是x里每条数据对应的分类:
[0, 0, 1, 1, 2, ...]
可以看到x里对应的分类总共有3种[0,1,2]。
2 训练模型
求出了每种分类里的数据每个特性项的平均值:
{0: [[5.1, 3.5, 1.4, 0.2],
[4.9, 3.0, 1.4, 0.2],
... ...],
1: [[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0,2],
... ...],
2: [[5.0, 3.6, 1.4, 0.2],
... ...]}
得到平均值结果集:
{0: [5.006, 3.418, 1.464, 0.244],
1: [5.936, 2.770, 4.260, 1.326],
2: [6.588, 2.974, 5.552, 2.026]}
3. 预测数据
求出待预测数据属于哪种分类的概率更大,也就是离哪个聚类质心更近。
对每条记录,计算其与每个聚类中点之间的距离并保存在一个数组里,计算距离公式有很多,欧式距离,曼哈顿距离等:
[[8.512, 2.321, 4.576]]
可以看到待预测数据属于分类0,1,2的距离被计算出来了。
完整代码可以访问github进行下载 https://github.com/azheng333/Ml_Algorithm.git。
(完)
关注大数据尖端技术发展,关注奇点大数据

以上是关于最近质心的主要内容,如果未能解决你的问题,请参考以下文章