python爬虫 2BeautifulSoup快速抓取网站图片
Posted 大家一起学编程(python)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫 2BeautifulSoup快速抓取网站图片相关的知识,希望对你有一定的参考价值。

前言
学习,最重要的是要了解它,并且使用它,正所谓,学以致用、本文,我们将来介绍,BeautifulSoup模块的使用方法,以及注意点,帮助大家快速了解和学习BeautifulSoup模块。有兴趣了解爬虫的小伙伴们,赶快学起来吧。关注公众号可获取爬虫教程哦。
第一步:了解需求
在开始写之前,我们需要知道我们要做什么?做爬虫。
抓取什么?抓取网站图片。
在什么地方抓取?图片之家_图片大全_摄影图片为主的国内综合性图片网

大家可以用这个网站练练手,页面也是比较简单的。
第二步:分析网站因素
我们知道我们需要抓取的是那一个网站数据,因此,我们要来分析一下网站是如何提供数据的。
根据分析之后,所有页面似乎都是相同的,那我们选择一个摄影图来为大家做演示。
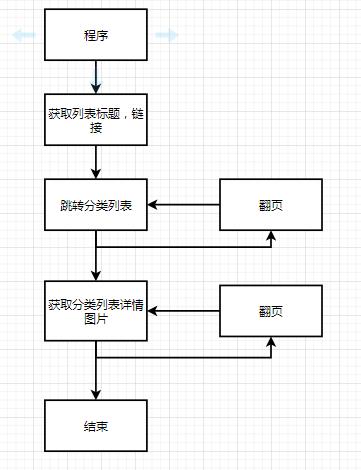
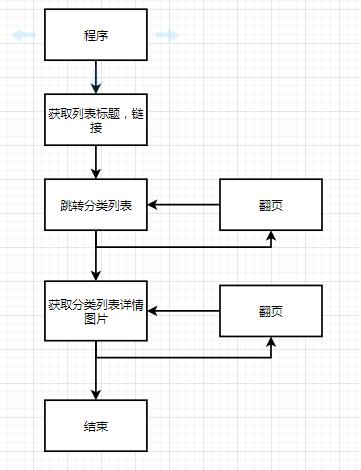
1、获取列表标题,以及链接
进一步研究页面数据,每一个页面,下方都有一个列表,然后通过列表标题,进入到下一级中。那这个页面我们需要获取列表标题。
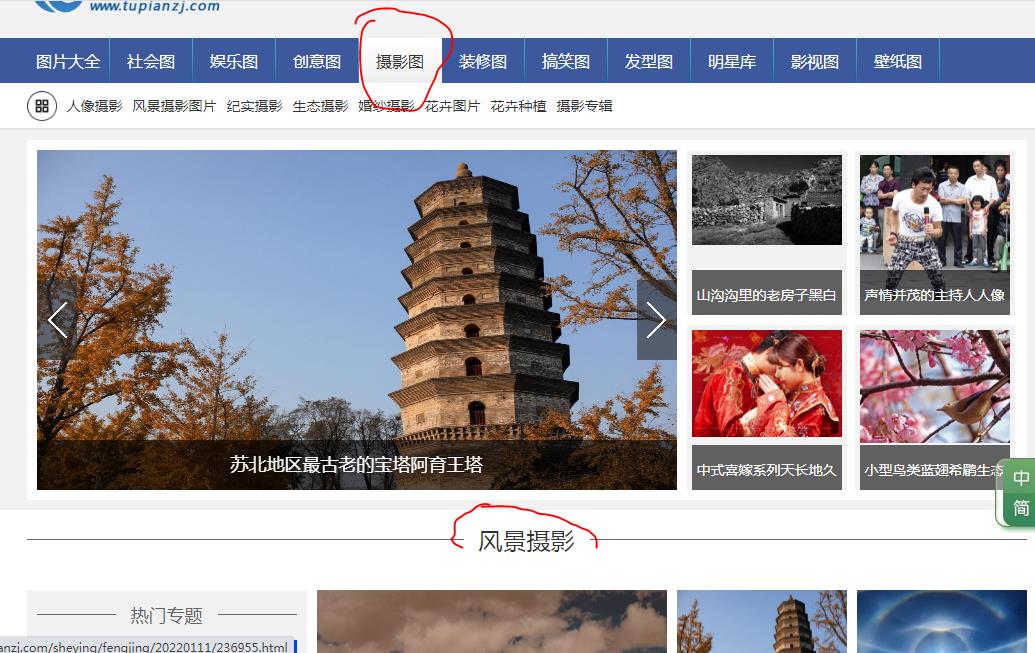
2、获取图片列表,以及链接,以及翻页操作
继续分析,点击链接进入之后,发现有已经有图片了列表,并且还可以翻页。

3、获取图片详情,所有图片
再点击继续研究,发现图片还有多张。

分析完成,我们来编写代码。
流程图如下:
第三步:编写代码实现需求
1、导入模块
导入我们需要使用到的所有模块。
import os
import re
from bs4 import BeautifulSoup
import requests
import time2、获取列表标题,以及链接
def tupianzj():
"""获取标题,链接"""
response = requests.get(url="https://www.tupianzj.com/sheying/",headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("h3","class":"list_title")
list=[]
for i in list_title:
list.append('name':i.get_text(),'url':i.find("a").get("href"))
return list
3、获取分类列表标题,链接,以及翻页。
def tu_list(url,page):
"""获取类比列表"""
response = requests.get(url,headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("ul","class":"list_con_box_ul")[0].find_all("li")
for i in list_title:
for j in i.find_all("a"):
try:
j.find("img").get("src")
name=j.get("title")#列表列表图片名称
url1="https://www.tupianzj.com"+j.get("href")[0:-5]#类比列表图片详情链接
text=Soup.find_all("div","class":"pages")[0].find_all("a")[1].get("href")#下一页
page1=Soup.find_all("span","class":"pageinfo")[0].find("strong").get_text()#获取总页数
url2=url+text[0:-6]+page+".html"
print(url2,page1)
try:
os.mkdir(name)#创建文件
except:
pass
tu_detail(name,url1,2)
if page==1:
for z in range(2,int(page1))
tu_list(url2,page)
except:
pass
4、获取详情图片,并保存
def tu_detail(path,url,page):
"""获取详情"""
if page<=2:
page=2
response = requests.get(url+"_"+str(page)+".html",headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
img_url=Soup.find("img",id="bigpicimg").get("src")
with open(path+"\\\\"+str(int(time.time()*1000000))+".jpg","wb") as f:
img=requests.get(img_url,headers=headers).content
f.write(img)
text=Soup.find_all("div","class":"pages")[0].find("a")
page1=re.findall(r"\\d+",text.decode())[0]
if page==2:
for i in range(int(page)+1,int(page1)+1):
tu_detail(path,url,i)
else:
return知识点总结
学会此文,可掌握知识点。
1、掌握BeautifulSoup
区分find,find_all的用法:find,查找第一个返回字符串,find_all 查找所有,返回列表
区分get,get_text的用法:get获取标签中的属性,get_text获取标签包围的文字。
2、掌握正则,re.findall 的使用
3、掌握字符串切片的方式 str[0,-5] 截取第一个文字,到倒数第5个文字。
4、掌握创建文件夹的方法os.mkdir(name)
5、掌握with open(f,w) as f:的用法
6、掌握requests模块的get请求方法。
完整代码
#-*- coding:utf-8 -*-
#!/usr/bin/env python
import os
import re
from bs4 import BeautifulSoup
import requests
import time
headers =
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User_agent':'Mozilla/5.0 (Linux; android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Mobile Safari/537.36',
def tu_detail(path,url,page):
"""获取详情"""
if page<=2:
page=2
response = requests.get(url+"_"+str(page)+".html",headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
# print(Soup)
img_url=Soup.find("img",id="bigpicimg").get("src")
with open(path+"\\\\"+str(int(time.time()*1000000))+".jpg","wb") as f:
img=requests.get(img_url,headers=headers).content
f.write(img)
text=Soup.find_all("div","class":"pages")[0].find("a")
page1=re.findall(r"\\d+",text.decode())[0]
if page==2:
for i in range(int(page)+1,int(page1)+1):
tu_detail(path,url,i)
else:
return
def tu_list(url,page):
"""获取类比列表"""
response = requests.get(url,headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("ul","class":"list_con_box_ul")[0].find_all("li")
for i in list_title:
for j in i.find_all("a"):
try:
j.find("img").get("src")
name=j.get("title")#列表列表图片名称
url1="https://www.tupianzj.com"+j.get("href")[0:-5]#类比列表图片详情链接
text=Soup.find_all("div","class":"pages")[0].find_all("a")[1].get("href")#下一页
page1=Soup.find_all("span","class":"pageinfo")[0].find("strong").get_text()#获取总页数
print(url2,page1)
try:
os.mkdir(name)#创建文件
except:
pass
tu_detail(name,url1,2)
if page==1:
for z in range(2,int(page1))
url2=url+text[0:-6]+str(z)+".html"
tu_list(url2,z)
except:
pass
def tupianzj():
"""获取标题,链接"""
response = requests.get(url="https://www.tupianzj.com/sheying/",headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("h3","class":"list_title")
for i in list_title:
tu_list(i.find("a").get("href"),1)
以上是关于python爬虫 2BeautifulSoup快速抓取网站图片的主要内容,如果未能解决你的问题,请参考以下文章
python爬虫 2BeautifulSoup快速抓取网站图片
python爬虫 2BeautifulSoup快速抓取网站图片