python爬虫框架之scrapy的快速上手 二
Posted ase265
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫框架之scrapy的快速上手 二相关的知识,希望对你有一定的参考价值。
scrapy快速上手之crawl模板
前面提到过,我们使用了basic作为模板生成了爬虫
现在介绍另外一种模板:crawl
创建项目
首先在命令行界面执行:
scrapy startproject Spider
后,即可得到提示
You can start your first spider with:
cd Spider
scrapy genspider example example.com然后,根据提示在命令继续输入cd Spider
这样,我们就来到了所创建爬虫的工作目录下
前面已经介绍过scrapy genspider example example.com
是使用basic模板来创建爬虫文件的
所以,为了使用crawl模板来创建爬虫文件,需要使用
scrapy genspider -t crawl example example.com
执行完毕后,可以得到如下提示:
Created spider 'example' using template 'crawl' in module:
Spider.spiders.example至此,我们成功创建了用crawl模板生成的爬虫project
我们得到的文件目录结构如下:
Spider
spiders
_init_.py
example.py
_init_.py
items.py
middleswares.py
pipelines.py
settings.py
scrapy.cfg这些文件分别是:
- scrapy.cfg:项目配置的文件
- Spider:该项目的python模块,该文件夹的名字为startproject命令指定的名字
- items.py:项目的item文件
- pipilines.py:项目的管道文件
- settings.py:项目的设置文件
- spiders:放置爬虫代码的文件
- spiders/example.py:爬虫文件
example.py
不同的模板生成的example.py是不一样的,这是crawl模板生成的example.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ExampleSpider(CrawlSpider):
name = 'example'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item以上内容就是我们利用crawl模板生成的爬虫文件,可以看到这与使用basic模板生成的爬虫文件的差别还是挺大的
首先ExampleSpider类继承于CrawlSpider,而使用basic模板生成的ExampleSpider类继承于Spider类
但还是有一些相同之处,例如name、allowed_domains和start_urls代表的含义都是一样的,即:
name为爬虫的名字,allow_domains指定要爬取的网址,start_url指定从哪个url开始爬取。
ExampleSpider类里还多了一个属性:rules。这个rules属性的作用是什么呢?
要想明白这个我们首先需要知道CrawlSpider是如何工作的
首先,CrawlSpider继承于Spider
在Spider中,在爬虫启动后会对start_url中给出的url发起请求,然后将得到的结果给parse函数进行解析
这个parse函数需要我们自己根据需求进行编写
而在CrawlSpider中,同样的也会对start_url中给出的url发起请求,然后将得到的结果给parse函数进行解析
所不同的是CrawlSpider类为了实现本身的爬取逻辑,自己定义了parse函数
换句话说,parse已经被实现了,我们也不能轻易更改,否则CrawlSpider运行会出错
那么CrawlSpider的爬取逻辑是什么呢?
举个例子来说,假设start_urls存储是某个网站的首页链接,那么启动爬虫时将根据该链接生成Request请求
正常情况下,Request请求将返回Response对象,即网页内容,然后使用CrawlSpider定义的parse函数进行解析
该函树解析的主要目的是提取出用户感兴趣的链接,并沿着该链接爬取下去,直到爬取整个网站或者爬取的链接已不在指定的域名
那么怎么知道用户感兴趣的链接呢?用户感兴趣的只有用户知道,于是便有了rules这个属性
用户感兴趣的链接将以正则表达式的形式定义在rules属性的LinkExtractor中
rules是一个包含了一个或者多个Rule对象的集合,Rule里面有三个参数:
- LinkExtractor定义如何从爬取到的页面提取链接,通过定义正则表达式的方法来提取链接
- callback:指定一个回调函数,从LinkExtractor中每获取到链接时就会调用该函数,该函数接受LinkExtractor的链接的响应作为第一个参数
- follow:指定了从response提取的链接是否需要跟进。如果callback为None,follow 默认设置为True,否则默认为False
因此,示例中的rules可解释为:
提取匹配 ‘Items/‘ 的链接并使用parse_item方法对请求匹配到的链接后得到的响应进行分析
此外还会对得到的响应的链接进行跟进
小例子:新浪新闻的爬取
这里我们简单列举一个爬取新浪新闻的例子
将新浪新闻的首页https://news.sina.com.cn/作为入口
沿着该链接进行爬取,我们感兴趣的链接为:news.sina.com.cn
于是CrawlSpider的属性被定义为:
name = 'sina'
allowed_domains = ['sina.com.cn']
start_urls = ['https://news.sina.com.cn/']
rules = (
Rule(LinkExtractor(allow=r'news.sina.com.cn'), callback='parse_item', follow=True),
)同时为了方便处理,我们对返回的response只将标题提取出来,parse_item方法定义如下:
def parse_item(self, response):
item = {}
item['title'] = response.xpath('//title/text()').extract()[0]
return item现在我们的工作就完成了,它将沿着新浪新闻首页的包含有“news.sina.com.cn”的链接爬取下去
最后启动爬虫:scrapy crawl sina
运行结果

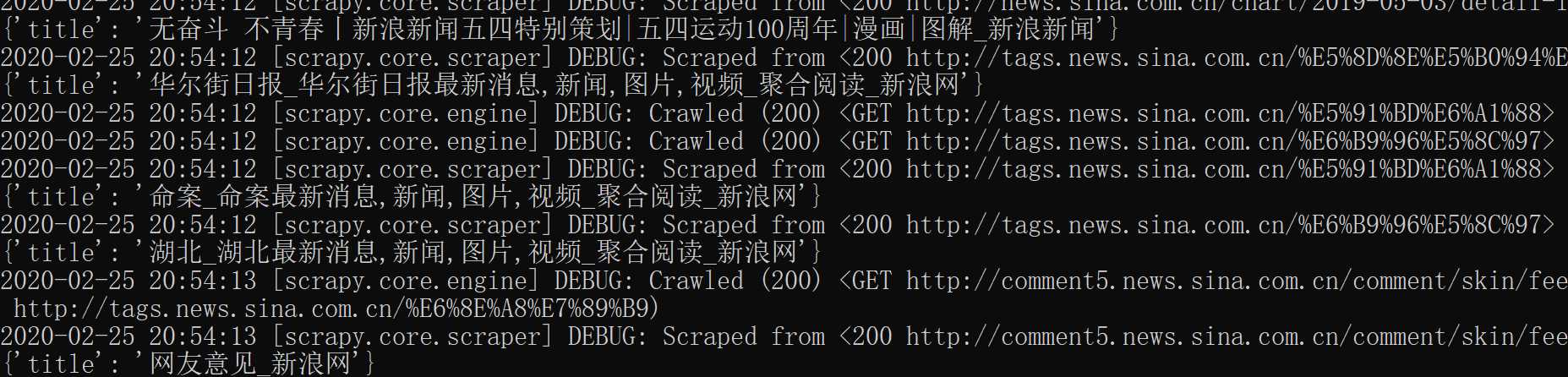
代码
代码非常简单,github
以上是关于python爬虫框架之scrapy的快速上手 二的主要内容,如果未能解决你的问题,请参考以下文章