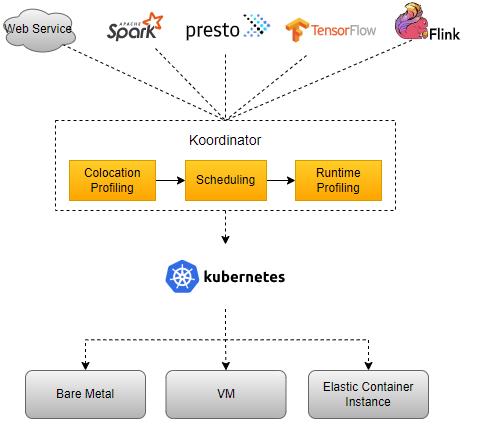
Koordinator 0.6:企业级容器调度系统解决方案,引入 CPU 精细编排资源预留与全新的重调度框架
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Koordinator 0.6:企业级容器调度系统解决方案,引入 CPU 精细编排资源预留与全新的重调度框架相关的知识,希望对你有一定的参考价值。
阿里云原生开源的混部系统 Koordinator 基于阿里超大规模混部生产实践经验而来,旨在为用户打造云原生场景下接入成本最低、混部效率最佳的解决方案,助力用户企业实现云原生后提升计算资源利用率、降低 IT 成本。
经过社区多位成员的贡献,Koordinator 0.6 版本正式发布。相较于上一个版本 0.5[1],新版本进一步完善了 CPU 精细化编排能力,更好的兼容原生用法;支持了资源预留的能力(Reservation),补齐了调度原子语意缺失;发布了全新的重调度框架,支持用户灵活的扩展自定义插件。这些特性源自于阿里巴巴内部的生产实践,并结合上游社区规划思考,为用户带来标准、强大、灵活的调度解决方案。
现代化调度系统的挑战
多云、混合云成为业务常态,调度系统必须适应多样化基础设施
随着国内外云厂商的不断发展,到 2022 年,大多数企业基础设施将围绕云计算环境构建,企业基础设施以云计算为主,以自建为辅。云计算按需的算力调配特性帮助企业实现通用、灵活、弹性的计算需求,自建部分满足企业传统应用架构过度、定制化或者安全合规诉求。
在企业使用云时,最大的顾虑是使用了厂商锁定的技术,因此多云架构是近年企业重点关注的领域,在多云环境中,不同云厂商的硬件可能存在不同程度的定制差异。调度系统如何适配多云场景下异构的算力设备,解决好异构资源调度、拓扑感知、运行时 QoS 保障,让用户在不同环境获得一致的体验,是一个很大的挑战。
为了帮助企业便利地管理云上、线下的算力,也会发展出混合云这样的产品架构,这其中可能出现一个集群中即包含云上又包含线下的计算节点,基础环境比较复杂。调度系统如何适配云上、线下环境,解决好不同环境对资源容量管理、任务编排、存储网络调度的诉求,同时支持用户在线下场景可以低成本的扩展自定义特性,让用户在一套调度系统上编排云上、线下的容器资源,是第二大挑战。
多种工作负载的混部成为常态,对调度系统能力的要求更加全面立体
Kubernetes 容器调度编排系统,帮助用户在一个节点上运行多个容器,也就提供了将不同业务的容器同时运行到一个节点的可能。也就是说,Kubernetes 天然地就支持了 “混部”。
随着企业容器化上云的进程加速,越来越多的应用类型通过 Kubernetes 部署到云基础设施之上。当企业的应用越来越多,为每一种类型的应用单独规划集群,在运维成本和资源成本上将不再可行。企业管理不同业务类型的方式逐步从切分集群到共享集群,从切分节点池到共享节点池这样的方式演进。
不同业务类型的工作负载,对调度系统都有不同的特性需求,调度系统如何在同一个集群、同一个节点上编排不同类型的工作负载,解决好它们各自的运行效率稳定性、对 Kubernetes 管控面性能和节点运行时稳定性的诉求,是现代化调度系统的一个重要课题。
成本效率成为企业关注的重点方向,调度系统是其中的关键一环
2020 年开始,受全球疫情的影响,企业的生产经营活动或多、或少的受到打击。有 65% 的企业开始考虑通过上云的方式降低企业 IT 信息化成本,已经上云的企业开始通过更深度的优化来降低 IT 资源成本。在成本治理领域,FinOps 的理念逐渐被企业所接受,在 2021 年 CNCF《FinOps Kubernetes Report》的调研报告显示,迁移至 Kubernetes 平台后,68% 的受访者表示所在企业计算资源成本有所增加,36% 的受访者表示成本飙升超过 20%。
这一调研结果与大型企业的应用实践截然不同,Google、微软、Alibaba 等国内外企业已经通过实践证明了企业容器化在成本上的巨大经济价值。这其中最关键的差别在于大型企业内部通常建设有完备的成本洞察能力,知道成本开销在哪里,同时建设了完备而强大的调度系统,让企业的资源充分的被利用起来。在这其中,调度系统如何处理好企业内部门间的 Quota 管理、资源借用,解决好上层弹性伸缩场景与底层节点池弹性伸缩之间的配合,合理的规划底层机型降低资源闲置率,是现代化云原生调度系统必须要解决的问题。
Koordinator 的解法和路径
打造下一代容器调度系统,我们这么做:

拥抱上游标准,打造基于 QoS 的闭环调度系统
在学术界,集群资源调度系统的架构设计是一个老话题了,从集中式到分布式,从两层调度到共享状态架构,从悲观锁到乐观锁。在工业界历史上,每一种架构都或多或少的有过成功的案例,也正印证了那句话“架构设计没有对错,只有合适不合适”。在 Kubernetes 成为容易编排的事实标准之后,在 Kubernetes 之上依然衍生出了多种的调度器设计,他们或是擅长解决某一垂直领域的问题,或是采用了不同的设计实现,在各自的场景中实现了价值。
打造现代化的云原生调度系统,Koordinator 坚持了如下的设计思路:
1. 拥抱 Kubernetes 上游标准,基于 Scheduler-Framework 来构建调度能力,而不是实现一个全新的调度器。构建标准形成共识是困难的,但破坏是容易的,Koordinator 社区与 Kubernetes sig-scheduling 社区相向而行。
2. QoS 是系统的一等公民,与业界大多数调度器更多的关注编排结果(静态)不同,Koordinator 非常关注 Pod 运行时质量(QoS),因为对于调度系统的用户而言,运行时稳定性是其业务成功的关键。
3. 状态自闭环,Koordinator 认为调度必须是一个完整的闭环系统,才能满足企业级应用要求。因此,我们在第一个版本就引入了状态反馈回路,节点会根据运行时状态调优容器资源,中心会根据节点运行时状态反馈做调度决策。
4. 智能化、简单化,Koordinator 并不是就所有的选择暴露把问题留给客户,而是根据应用特征智能的为用户提供优化配置建议,简化用户使用 Kubernetes 的成本。
建设能力强大、灵活且可插拔的精细化资源编排优化方案
今天,服务器的 CPU 有 Intel、AMD、多家供应商的 ARM 芯片,AI 场景广泛应用的 GPU、FPGA 等,Kubernetes 作为容器编排基础设施,承载着异构硬件的管理工作,如何在标准 Kubernetes 之上提供异构硬件的调度编排,同时支持用户多样、灵活的策略控制,Koordinator 遵循了如下的设计思路:
1. 兼容 Kubernetes,Kubernetes 为用户提供了 static policy cpu manager,Koordinator 的 CPU 拓扑感知可以在用户启用 static policy 时兼容运行,也支持接管用户存量的运行时 Pod,方便用户做技术升级。
2. 中心调度 + 单机调度联合决策,中心调度看到全局视角,其决策可以找到集群中最适合应用需求的节点,而单机调度可以在节点侧做一定的灵活度,以应对应用突发的流量颠簸。
3. 调度 + 重调度密切配合,调度解决 Pod 一次性放置的问题,而重调度才是驱动集群资源编排长期保持最优化的关键。Koordinator 将建设面向 SLO 的重调度能力,持续的驱动应用的编排符合预定义的 SLO。
打造开箱即用的混部和工作负载弹性解决方案
混部是解决 Kubernetes 集群资源利用率的终极武器,这一点在国内外大型企业中都得到了实践论证,但也只是限于这个小圈子之中。近年随着国内外厂商的宣传以及关键信息在学术界论文透出,数字化路上的企业特别是云原生化的企业,对混部都有或多或少的了解。但面对混部,用户的心声是有没有一套开箱即用的解决方案,帮助用户优化 Kubernetes 集群的资源成本效率。
企业接入混部最大的挑战是如何让应用跑在混部平台之上,这第一步的门槛往往是最大的拦路虎。Koordinator 针对这一问题,结合内部生产实践经验,设计了“双零侵入”的混部调度系统:
1. 对 Kubernetes 平台的零侵入。行业内的人大多知道,将 Kubernetes 应用于企业内部的复杂场景混部时,因为这样或者那样的原因总是需要对 Kubernetes 做一定量的修改,这些修改将导致用户使用混部时出现厂商锁定的风险。而 Koordinator 混部系统,设计之处即保证了不需要对社区原生 Kubernetes 做任何修改,只需要一键安装 Koordinator 组件到集群中,既可以为 Kubernetes 集群带来混部的能力。
2. 对工作负载编排系统的零侵入。想像一下,在企业内部的 Kubernetes 集群之上提供混部能力之后,将面临的问题是如何将企业的工作负载接入进来,以混部的方式运行。对工作负载管理逻辑的侵入,乐观是需要付出额外的适配成本,悲观时是这些改动是在云厂商提供的组件内(比如 kcm),将面临厂商锁定或者供应商不支持的风险。
Koordinator 针对应用接入层的改造成本,设计了单独的工作负载接入层,帮助用户解决工作负载接入混部的难题,用户只需要管理混部的配置即可灵活的调度编排哪些任务以混部的方式运行在集群中,非常的简单且灵活。
构建工作负载数据分析体系,提供智能的优化建议
调度系统不止于解决调度、重调度、弹性伸缩等领域问题,一个完整的调度系统,需要具备基于历史数据驱动的自我迭代演进的能力。为工作负载的运行历史状态建立数据仓库,基于这些运行历史的大数据分析,持续的改进应用间在各个维度的的亲和、互斥关系,才能在用户运行时体验、集群资源利用效率同时达到最佳状态。
Koordinator 针对智能化调度的设计思路如下:
1. 智能资源超卖,Koordinator 首先解决的是节点资源充分利用的问题,通过分析节点容器的运行状态计算可超卖的资源量,并结合 QoS 的差异化诉求将超卖的资源分配给不同类型的任务,大幅提高集群的资源利用率。
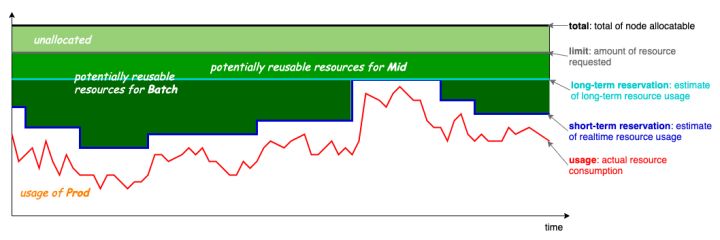
2. QoS 感知的重调度,当节点中 Pod 的运行时 QoS 不符合预期时,Koordinator 将智能决策抑制更低优先级的任务亦或是迁移当前收到干扰的容器,从而解决应用 QoS 不满足导致的问题。
3. 更多的能力敬请期待,未来这里将是 Koordinator 重点迭代的领域。
围绕着这条路,在 0.6 版本中,社区带来了下述更新。
版本功能特性解读
Koordinator 近期发布了 v0.6 版本,包含了以下增强、新增特性:
1. 新版本进一步完善了 CPU 精细化编排能力,更好的兼容原生用法。
2. 在 Kubernetes 之上引入资源预留的原子能力(Reservation),资源预留在容量管理、碎片优化、调度成功率优化等方面有重要作用。
3. 提供了 Pod 腾挪的能力(PodMigrationJob),可以帮助用户可靠地迁移有问题实例、整理集群资源碎片等。
4. 发布了全新的 Descheduler Framework,支持用户灵活的扩展自定义插件,结合 PodMigrationJob 实现安全、可靠、灵活的重调度。
5. 此外,该版本包含了 GPU、Gang、Elastic Quota 相关的设计。
更加完善的 CPU 精细化编排 - Fine-grained CPU Orchestration
随着资源利用率的提升进入到混部的深水区,需要对资源运行时的性能做更深入的调优,更精细的资源编排可以更好的保障运行时质量,从而通过混部将利用率推向更高的水平。
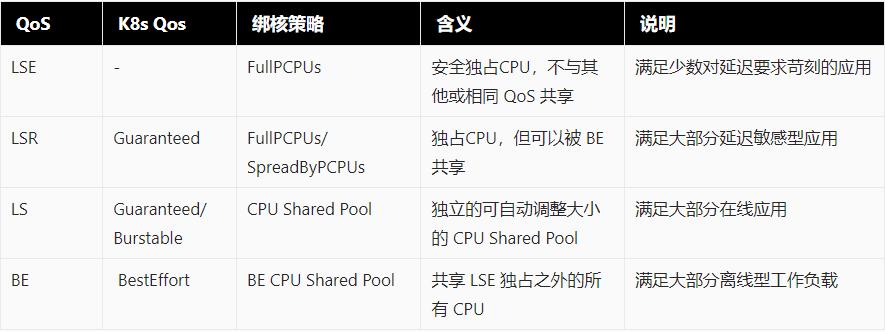
我们把 Koordinator QoS 在线应用 LS 类型做了更细致的划分,分为 LSE、LSR 和 LS 三种类型。拆分后的 QoS 类型具备更高的隔离性和运行时质量,通过这样的拆分,整个 Koordinator QoS 语义更加精确和完整,并且兼容 K8s 已有的 QoS 语义。并且我们针对 Koordinator QoS,设计了一套丰富灵活的 CPU 编排策略,如下表所示:
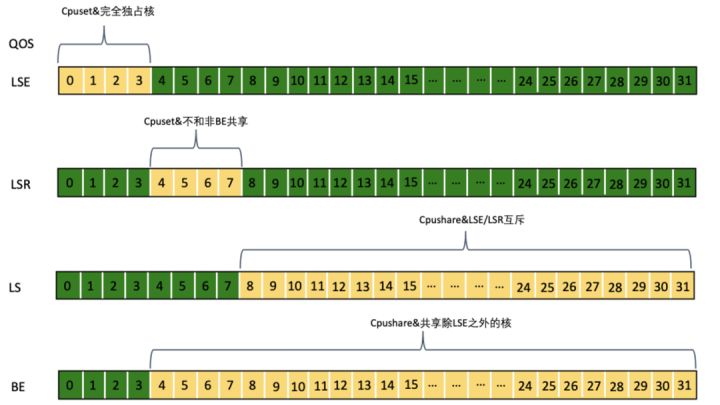
大家可以结合下图,可以更容易理解这一套 QoS 和编排策略:
在之前的《云原生混部系统 Koordinator 架构详解》中,我们向大家介绍过当时正在实现 CPU 精细化编排方案[2]设计,并在 Koordinator v0.5 版本中,实现了基本的 CPU 精细化编排能力,用户可以在 Pod 中新增 Koordinator CPU 精细化编排协议,指定期望的 CPU 编排策略指导 koord-scheduler 在调度时选择最适合的节点。koord-scheduler 在分配时优先考虑 NUMA 架构,使得分配的 CPU 尽可能不跨 NUMA Node/Socket,并且为了尽可能避免 NUMA Node/Socket 维度产生碎片,默认使用 MostAllocated 策略选择剩余 CPU 少的 NUMA Node。
在 Koordinator v0.6 中,进一步完善了 CPU 精细化编排能力,更好的支持了延迟敏感型应用对于干扰隔离的需求以及更好的兼容原生用法:
1. 当 Koordinator QoS 为 LSE/LSR 类型的 Pod 没有设置 CPU 精细化编排协议时,koord-scheduler 使用配置的默认 CPU 编排策略分配 CPU。
2. 新增支持 PCPULevel 或者 NUMANodeLevel 两种 CPU 互斥策略(CPU Exclusive Policy)。koord-scheduler 会根据用户的配置,尽量的保障具有相同互斥策略的 Pod 在物理核维度(PCPULevel)或者 NUMA Node 维度(NUMANodeLevel)互斥。该机制可以有效的避免 CPU 密集型应用的相互干扰。
3. 支持 Node CPU Orchestration API,集群管理员或者集群资源运营可以通过该 API 约束节点的 CPU 编排策略。
- 支持通过标签 node.koordinator.sh/cpu-bind-policy 约束调度时的 CPU 绑定逻辑。当前支持的策略 FullPCPUsOnly 表示要求 koord-scheduler 在分配 CPU 时,分配的 CPU 数量必须分配在相同的一批物理核上,并且在 SMT 架构下(例如常见的 x86 架构) 要求 Pod 的 CPU 请求数量必须是单个物理核内虚拟逻辑核的倍数。FullPCPUsOnly 与 Kubernetes 支持的 kubelet CPU Manager Policy Option full-pcpus-only=true 等价。
- 支持通过标签 node.koordinator.sh/numa-allocate-strategy 指定 NUMA Node 维度的分配选择策略,如果设置 MostAllocated,期望 koord-scheduler 优先从剩余 CPU 最少的 NUMA Node上分配;如果设置 LeastAllocated,期望 koord-scheduler 优先从剩余 CPU 最多的 NUMA Node 上分配。默认使用 MostAllocated 策略。该配置还会作用在后续将要支持的 NUMA Topology 调度能力。
4. 单机侧 koordlet 增强了对 LSE QoS 的支持,例如 koordlet 启用 CPU Suppress 机制时,在为 BE Pod 分配 CPU 时会排除掉 LSE Pod 绑定的 CPU,实现 LSE QoS 的强保障。
资源预留 - Reservation
在 Koordinator v0.6 中 ,我们基于原有 v0.5 版本完成的资源预留 API 设计方案[3],在不侵入 Kubernetes 已有的机制和代码前提下,实现了资源预留的原子能力(Reservation)。资源预留在容量管理、碎片优化、调度成功率和重调度等场景有重要作用:
1. 当有重要的工作负载在未来某段时间需要资源时,可以提前预留资源满足需求。
2. 用户在 PaaS 上发起扩容时,可以通过资源预留能力尝试预留,预留成功后发起扩容,保障 PaaS 的 SLA。
3. 用户在 PaaS 上发布时,如果应用采用了滚动发布的能力,可以通过资源预留保留即将销毁的 Pod 持有的资源,在滚动发布时,新建的 Pod 可以复用预留下来的原有资源,能够有效提高滚动发布的成功率。
4. 碎片优化场景中,可以通过资源预留占住空闲的碎片资源,并把可被整理的 Pod 迁移到这些节点。
5. 重调度时在发起驱逐前,先尝试预留资源,预留成功后发起驱逐,避免驱逐后无资源可用影响应用的可用性。
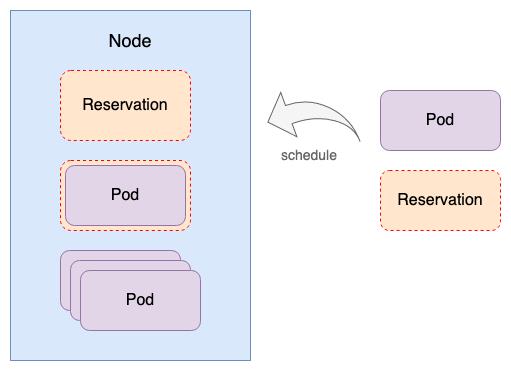
Koordinator Reservation API 允许用户不修改 Pod Spec 或者存量的 Workload(例如 Deployment, StatefulSet)即可以预留资源。基本流程如下:
1. 当用户期望预留资源时,可以创建一个 Reservation CRD 实例,通过 ReservationSpec.Template 声明未来新建的 Pod Spec , 并声明预留资源的所有权,即填写 ReservationSpec.Owners 字段。
2. koord-scheduler watch 到新建的 Reservation 后,会根据 ReservationSpec 中的信息模拟为一个 Pod(称为 ReservePod) 进行调度找到合适的节点,并把调度的结果更新回 ReservationStatus。
3. 用户创建新的Pod,koord-scheduler 优先为该 Pod 寻找合适的 Reservation 实例,koord-scheduler 会根据 Reservation 中记录的资源所有权,通过 label selector 机制或者判断 controller ownerReference 的形式判断新 Pod 是否与 Reservation 匹配,如果匹配,则会进行预处理,保障后续的 Reservation 资源定向给该 Pod 使用。并在打分阶段影响调度逻辑,优先实现 Reservation 对象占用的资源。
4. Pod bind 时更新 ReservationStatus,记录该 Reservation 被哪些 Pod 消费了。
5. 当 Pod 销毁时,koord-scheduler 会更新 ReservationStatus 删除 Pod 消费记录,该 Reservation 会被继续使用直到超过设定的过期时间(BTW: 默认 24 小时过期,如果 TTL 设置为 0,表示不过期)。
- Quick Start
1. 使用下面的 YAML 文件创建 Reservation reservation-demo
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Reservation
metadata:
name: reservation-demo
spec:
template: # set resource requirements
namespace: default
spec:
containers:
- args:
- '-c'
- '1'
command:
- stress
image: polinux/stress
imagePullPolicy: Always
name: stress
resources: # reserve 500m cpu and 800Mi memory
requests:
cpu: 500m
memory: 800Mi
schedulerName: koord-scheduler # use koord-scheduler
owners: # set the owner specifications
- object: # owner pods whose name is `default/pod-demo-0`
name: pod-demo-0
namespace: default
ttl: 1h # set the TTL, the reservation will get expired 1 hour later2. 观察并等待 Reservation reservation-demo 变为 Available 状态
$ kubectl create -f reservation-demo.yaml
reservation.scheduling.koordinator.sh/reservation-demo created
$ kubectl get reservation
NAME PHASE AGE
reservation-demo Available 3h16m3. 使用下面的文件创建 Pod pod-demo-0
apiVersion: v1
kind: Pod
metadata:
name: pod-demo-0 # match the owner spec of `reservation-demo`
spec:
containers:
- args:
- '-c'
- '1'
command:
- stress
image: polinux/stress
imagePullPolicy: Always
name: stress
resources:
limits:
cpu: '1'
memory: 1Gi
requests:
cpu: 200m
memory: 400Mi
restartPolicy: Always
schedulerName: koord-scheduler # use koord-scheduler4. 检查 Pod pod-demo-0 的调度结果
$ kubectl get pod pod-demo-0 -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-demo-0 1/1 Running 0 32s 10.17.0.123 node-0 <none> <none>pod-demo-0 被调度到 与 Reservation reservation-demo 相同的节点。
5. 检查 Reservation reservation-demo 的状态.
$ kubectl get reservation reservation-demo -oyaml
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Reservation
metadata:
name: reservation-demo
creationTimestamp: "YYYY-MM-DDT05:24:58Z"
uid: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
...
spec:
owners:
- object:
name: pod-demo-0
namespace: default
template:
spec:
containers:
- args:
- -c
- "1"
command:
- stress
image: polinux/stress
imagePullPolicy: Always
name: stress
resources:
requests:
cpu: 500m
memory: 800Mi
schedulerName: koord-scheduler
ttl: 1h
status:
allocatable: # total reserved
cpu: 500m
memory: 800Mi
allocated: # current allocated
cpu: 200m
memory: 400Mi
conditions:
- lastProbeTime: "YYYY-MM-DDT05:24:58Z"
lastTransitionTime: "YYYY-MM-DDT05:24:58Z"
reason: Scheduled
status: "True"
type: Scheduled
- lastProbeTime: "YYYY-MM-DDT05:24:58Z"
lastTransitionTime: "YYYY-MM-DDT05:24:58Z"
reason: Available
status: "True"
type: Ready
currentOwners:
- name: pod-demo-0
namespace: default
uid: yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy
nodeName: node-0
phase: Available我们可以观察到 Reservation reservation-demo 预留了 500m CPU 和 800 Mi 内存,并且 Pod pod-demo-0从 Reservation reservation-demo中分配了 200m CPU 和 400Mi 内存。
6. 清理 Reservation reservation-demo.
$ kubectl delete reservation reservation-demo
reservation.scheduling.koordinator.sh "reservation-demo" deleted
$ kubectl get pod pod-demo-0
NAME READY STATUS RESTARTS AGE
pod-demo-0 1/1 Running 0 110s可以观察到 Reservation 删除后,Pod pod-demo-0 还在运行中。
安全可靠的 Pod 腾挪迁移机制 - PodMigrationJob
腾挪迁移 Pod 是许多组件(例如 descheduler)所依赖的重要功能,可用于优化调度或帮助解决工作负载运行时质量问题。我们认为 Pod 迁移是一个复杂的过程,涉及到审计、资源分配、应用启动等步骤,还夹杂着应用的发布升级、扩容/缩容场景和集群管理员的资源运维操作。因此,如何管理 Pod 迁移过程的稳定性风险,保证应用不会因为 Pod 的迁移影响可用性,是一个非常关键的必须解决的问题。
为了让大家更好的理解,举几个场景:
1. 社区的重调度器内置的多个重调度策略根据自身逻辑判断某个 Pod 是否要被迁移,需要迁移时调用 K8s Eviction API 发起驱逐。但是这个过程并不关注被驱逐的 Pod 在将来是否可以分配到资源。因此存在大量 Pod 被驱逐后因为没有资源而处于 Pending 状态的情况。如果应用此时有大量请求进来,又因为没有足够的可用的 Pod 导致可用性异常。
2. 另外,社区重调度器调用的 K8s Evcition API 虽然会检查 PDB 确保在安全范围内驱逐,但是众所周知,众多的 workload Controller 在发布和缩容场景都是通过直接调用 Delete API 的形式销毁 Pod,此时并不会被 PDB 限制。这就导致重调度时如果遇到上述场景,是很可能引发严重的稳定性问题。
3. 我们认为 Pod 腾挪不是一个简单的后台自动化逻辑,有相当多的场景和用户期望由人工介入手工迁移 Pod,甚至期望重调度时发起的自动迁移请求应该被拦截掉,经过审批决定是否执行。
Koordinator 基于 CRD 定义了一个名为 PodMigrationJob API[4]。重调度器或者其他自动化自愈组件通过 PodMigrationJob 可以安全的迁移 Pod。PodMigrationJob Controller 在处理 PodMigrationJob 时会先尝试通过 Koordinator Reservation 机制预留资源,预留失败则迁移失败;资源预留成功后发起驱逐操作并等待预留的资源被消费。中间的过程都会记录到 PodMigrationJobStatus 中,并产生相关的 Event。
- Quick Start
PodMigrationJob 使用起来也十分简单:
1. 使用如下 YAML 文件创建一个 PodMigrationJob migrationjob-demo,迁移 Pod pod-demo-5f9b977566-c7lvk
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: PodMigrationJob
metadata:
name: migrationjob-demo
spec:
paused: false
ttl: 5m
mode: ReservationFirst
podRef:
namespace: default
name: pod-demo-5f9b977566-c7lvk
status:
phase: Pending$ kubectl create -f migrationjob-demo.yaml
podmigrationjob.scheduling.koordinator.sh/migrationjob-demo created2. 查询 PodMigrationJob 的迁移状态
$ kubectl get podmigrationjob migrationjob-demo
NAME PHASE STATUS AGE NODE RESERVATION PODNAMESPACE POD NEWPOD TTL
migrationjob-demo Succeed Complete 37s node-1 d56659ab-ba16-47a2-821d-22d6ba49258e default pod-demo-5f9b977566-c7lvk pod-demo-5f9b977566-nxjdf 5m0s
$ kubectl describe podmigrationjob migrationjob-demo
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ReservationCreated 8m33s koord-descheduler Successfully create Reservation "d56659ab-ba16-47a2-821d-22d6ba49258e"
Normal ReservationScheduled 8m33s koord-descheduler Assigned Reservation "d56659ab-ba16-47a2-821d-22d6ba49258e" to node "node-1"
Normal Evicting 8m33s koord-descheduler Try to evict Pod "default/pod-demo-5f9b977566-c7lvk"
Normal EvictComplete 8m koord-descheduler Pod "default/pod-demo-5f9b977566-c7lvk" has been evicted
Normal Complete 8m koord-descheduler Bind Pod "default/pod-demo-5f9b977566-nxjdf" in Reservation "d56659ab-ba16-47a2-821d-22d6ba49258e"可以观察到,PodMigrationJob Controller 把 Pod pod-demo-5f9b977566-c7lvk 迁移到了 `node-1`,新 Pod 为 pod-demo-5f9b977566-nxjdf.
- 仲裁机制
当前版本还暂未实现设计方案中定义的仲裁机制,该机制将会在 v0.7 版本中实现。仲裁机制是指 PodMigrationJob Controller 在 reconcile 前会选择最合适的一批 PodMigrationJob 执行。该过程涉及到 Group、Filter 和 Sort 三个阶段。
1. Group 阶段:
会按照 Workload, Namespace 和 Node 三个维度聚合。
2. Filter 阶段:
过滤掉危险的 PodMigrationJob。
- 判断 Workload 对应的 PDB 或者 OpenKruise PUB,如果不符合定义的安全阈值,则会过滤掉
- 判断目标 Pod 关联的 Workload 有多少正在执行的 PodMigrationJob,如果达到了配置的最大数量,则会过滤掉。
- 判断 Namespace 维度下正在迁移的 Pod 数量,超过阈值则过滤掉
- 判断 Node 维度下正在迁移的 Pod 数量,超过阈值则过滤掉
3. Sort 阶段:
对 PodMigrationJob 排序和打散。尽量选择迁移代价低的 Pod。
- 用户可以根据实际情况,在 Pod 上追加标签 scheduling.koordinator.sh/eviction-cost标记迁移代价。
- 让每个Workload、Namespace、Node 尽可能少的驱逐 Pod
全新的重调度框架 - Descheduler Framework
我们在 Koordinator v0.6 版本中实现了一个全新的重调度器框架[5](Descheduler Framework)。
K8s 社区 descheduler 在过去提供了一些策略解决一些常用的调度编排异常问题。但我们认为社区的 descheduler 还有很多方面可以提升:
1. K8s 社区 descheduler 只支持定时执行的机制,不支持基于 Event 触发的工作模式,无法满足一些期望联动其他组件触发的事件或者期望根据 Pod/Node 事件实现更积极的重调度等场景。
2. 另外社区 descheduler 不能很好的扩展实现自定义重调度策略,每次需要实现一个自定义重调度策略时都需要把社区上游的代码拷贝到本地进行修改,然后自己维护起来,当后续社区有变化时,需要花费较大的代价进行合并。这点与 kube-scheduler 对比来看,kube-scheduler 基于 scheduling framework,支持用户无需修改上游代码既可以扩展调度能力。
3. 不支持自定义驱逐逻辑。例如当需要实现上面提到的 PodMigrationJob 时,只能 fork 代码后修改适配。
我们认为重调度场景:
1. 需要一个插件化机制实现自定义的重调度策略,但又不希望这个抽象过于复杂;
2. 需要具备基本的插件管理能力,通过配置启用和禁用插件;
3. 具备统一的插件配置下发机制,方便插件自定义参数;
4. 并能够方便的扩展和使用统一的 Evictor 机制;
5. 另外期望用户能够基于 controller-runtime 实现 controller 并纳入统一的插件管理机制。
我们在进行 descheduler framework 的设计时,也注意到 K8s descheduler 社区其实也注意到了这些问题,期望实现一个类似于 K8s scheduling framework 一样的框架(descheduler framework) ,并且也提出了一些针对性的提案探索相关的实现,例如 #753 Descheduler framework Proposal[6]和 PoC #781[7]。
这个想法与 Koordinator 团队不谋而合。纵观 K8s descheduler 社区的提案,基本上解决了我们关心的很多问题,例如插件配置、插件抽象等,但是我们也注意到有很多相关实现还在 PoC 阶段或者部分相关实现还未合入到主干分支。经过 Koordinator 团队的 Review 和讨论,我们认为虽然这些提案中还有一些未解决的问题和未完全敲定的设计,但我们相信这是一个正确的方向。
同时基于 Koordinator 制定的的里程碑,我们期望尽快建设重调度相关的特性,因此我们基于上游社区#753 PR[8]的思路,在 Koordinator 中独立实现了一套新的 descheduler framework。我们期望通过这样独立实现的方式解决 Koordinator 对重调度能力的需求,同时也期望借此推动上游社区 descheduler framework 工作的演进,当上游有新的进展时,我们将会及时跟进,尽最大可能与上游保持兼容。
Koordinator descheduler framework 提供了插件配置管理(例如启用、禁用,统一配置等)、插件初始化、插件执行周期管理等机制。并且该框架内置了基于 PodMigrationJob 实现的 Controller,并作为 Evictor Plugin 方便被各种重调度插件使用,帮助重调度插件安全的迁移 Pod。
基于 Koordinator descheduler framework,用户可以非常容易的扩展实现自定义重调度策略,就像基于 K8s scheduling framework 的实现自定义的调度插件一样简单。并且用户也可以以插件的形式实现 controller,支持基于 Event 触发重调度的场景。
当前,我们已经完成了 descheduler framework 主体部分,整体都是可用的。并且提供了一个示例插件[9]方便大家理解和开发。在后续的版本中,我们将会迁移社区已有的重调度策略,以插件的形式集成到 Koordinator,作为内置能力的一部分。并且还会针对混部场景,实现针对性的重调度插件解决混部场景下的具体问题,例如负载均衡重调度,解决节点间负载不均衡、热点等问题。
目前框架还处于快速演进的初期阶段,还有很多细节需要完善。欢迎大家有兴趣一起参与建设。我们希望更多的人可以更放心、更简单地实现自己需要的去调度能力。
其他变更
对于大家关心的 GPU Share Scheduling, Gang Scheduling 和 Elastic Quota Scheduling 等能力也有一些新的进展。
在 v0.6 版本中,Koordiantor社区完成了 GPU Share Scheduling 和 Gang Scheduling 的方案设计工作,相关的 Proposal 已经 Review 通过。Elastic Quota Scheduling 的方案设计也基本完成。这些能力将会在 v0.7 版本中实现。
另外,为了探索 GPU 超卖和 GPU 诊断分析等场景,在 v0.6 版本中增加了 GPU Metric 上报机制。
你可以通过 Github release[10]页面,来查看更多的改动以及它们的作者与提交记录。
相关链接
[1] 版本 0.5:
https://github.com/koordinator-sh/koordinator/releases/tag/v0.5.0
[2] CPU 精细化编排方案:
https://koordinator.sh/docs/user-manuals/fine-grained-cpu-orchestration/
[3] 资源预留 API 设计方案
https://koordinator.sh/docs/designs/resource-reservation/
[4] PodMigrationJob API:
https://koordinator.sh/docs/designs/pod-migration-job/
[5] 重调度器框架:
https://koordinator.sh/docs/designs/descheduler-framework/
[6] #753 Descheduler framework Proposal :
https://github.com/kubernetes-sigs/descheduler/issues/753
[7] PoC #781:
https://github.com/kubernetes-sigs/descheduler/pull/781
[8] #753 PR:
https://github.com/kubernetes-sigs/descheduler/issues/753
[9] 示例插件:
https://github.com/koordinator-sh/koordinator/blob/main/pkg/descheduler/framework/plugins/removepodsviolatingnodeaffinity/node_affinity.go
[10] Github release:
https://github.com/koordinator-sh/koordinator/releases/tag/v0.6.1
[11] Slack channel:
https://koordinator-sh.slack.com/join/shared_invite/zt-1756qoub4-Cn4~esfdlfAPsD7cwO2NzA
作者:李涛、曾凡松
本文为阿里云原创内容,未经允许不得转载。
以上是关于Koordinator 0.6:企业级容器调度系统解决方案,引入 CPU 精细编排资源预留与全新的重调度框架的主要内容,如果未能解决你的问题,请参考以下文章
Koordinator v0.7: 为任务调度领域注入新活力