Koordinator v1.1发布:负载感知与干扰检测采集
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Koordinator v1.1发布:负载感知与干扰检测采集相关的知识,希望对你有一定的参考价值。
背景
Koordinator 旨在为用户提供完整的混部工作负载编排、混部资源调度、混部资源隔离及性能调优解决方案,帮助用户提高延迟敏感服务的运行性能,挖掘空闲节点资源并分配给真正有需要的计算任务,从而提高全局的资源利用效率。

从 2022 年 4 月发布以来,Koordinator 迄今一共迭代发布了 9 个版本。项目经历的大半年发展过程中,社区吸纳了包括阿里巴巴、小米、小红书、爱奇艺、360、有赞等在内的大量优秀工程师,贡献了众多的想法、代码和场景,一起推动 Koordinator 项目的成熟。
今天,很高兴地宣布 Koordinator v1.1 正式发布,它包含了负载感知调度/重调度、cgroup v2 支持、干扰检测指标采集,以及其他一系列优化点。接下来我们就针对这些新增特性做深入解读与说明。
版本特性深入解读
负载感知调度
支持按工作负载类型统计和均衡负载水位
Koordinator v1.0 及之前的版本,提供了负载感知调度提供基本的利用率阈值过滤保护高负载水位的节点继续恶化影响工作负载的运行时质量,以及通过预估机制解决解决冷节点过载的情况。已有的负载感知调度能解决很多常见场景的问题。但负载感知调度作为一种优化手段,还有比较多的场景是需要完善的。
目前的负载感知调度主要解决了集群内整机维度的负载均衡效果,但有可能出现一些特殊的情况:节点部署了不少离线 Pod 运行,拉高了整机的利用率,但在线应用工作负载的整体利用率偏低。这个时候如果有新的在线 Pod,且整个集群内的资源比较紧张时,会有如下的问题:
- 有可能因为整机利用率超过整机安全阈值导致无法调度到这个节点上的;
- 还可能出现一个节点的利用率虽然相对比较低,但上面跑的全是在线应用率,从在线应用角度看,利用率已经偏高了,但按照当前的调度策略,还会继续调度这个Pod上来,导致该节点堆积了大量的在线应用,整体的运行效果并不好。
在 Koordinator v1.1 中,koord-scheduler 支持感知工作负载类型,区分不同的水位和策略进行调度。
在 Filter 阶段:
新增 threshold 配置 prodUsageThresholds,表示在线应用的安全阈值,默认为空。如果当前调度的 Pod 是 Prod 类型,koord-scheduler 会从当前节点的 NodeMetric 中统计所有在线应用的利用率之和,如果超过了 prodUsageThresholds 就过滤掉该节点;如果是离线 Pod,或者没有配置 prodUsageThresholds,保持原有的逻辑,按整机利用率处理。
在 Score 阶段:
新增开关 scoreAccordingProdUsage 表示是否按 Prod 类型的利用率打分均衡。默认不启用。当开启后,且当前 Pod 是 Prod 类型的话,koord-scheduler 在预估算法中只处理 Prod 类型的 Pod,并对 NodeMetrics 中记录的其他的未使用预估机制处理的在线应用的 Pod 的当前利用率值进行求和,求和后的值参与最终的打分。如果没有开启 scoreAccordingProdUsage ,或者是离线 Pod,保持原有逻辑,按整机利用率处理。
支持按百分位数利用率均衡
Koordinator v1.0 及以前的版本都是按照 koordlet 上报的平均利用率数据进行过滤和打分。但平均值隐藏了比较多的信息,因此在 Koordinator v1.1 中 koordlet 新增了根据百分位数统计的利用率聚合数据。调度器侧也跟着做了相应的适配。
更改调度器的 LoadAware 插件的配置,aggregated 表示按照百分位数聚合数据进行打分和过滤。
aggregated.usageThresholds 表示过滤时的水位阈值;aggregated.usageAggregationType 表示过滤阶段要使用的百分位数类型,支持 avg,p99,p95,p90和 p50;aggregated.usageAggregatedDuration 表示过滤阶段期望使用的聚合周期,如果不配置,调度器将使用 NodeMetrics 中上报的最大周期的数据;aggregated.scoreAggregationType表示在打分阶段期望使用的百分位数类型;aggregated.scoreAggregatedDuration 表示打分阶段期望使用的聚合周期,如果不配置,调度器将使用 NodeMetrics 中上报的最大周期的数据。
在 Filter 阶段:
如果配置了 aggregated.usageThresholds 以及对应的聚合类型,调度器将按该百分位数统计值进行过滤;
在 Score 阶段:
如果配置了 aggregated.scoreAggregationType,调度器将会按该百分位数统计值打分;目前暂时不支持 Prod Pod 使用百分位数过滤。
使用示例
1.更改 koord-scheduler 配置,启用按 Prod 统计利用率并在过滤和打分阶段生效,整机按百分位数统计利用率并在过滤和打分阶段生效。
apiVersion: v1
kind: ConfigMap
metadata:
name: koord-scheduler-config
...
data:
koord-scheduler-config: |
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: koord-scheduler
plugins:
# enable the LoadAwareScheduling plugin
filter:
enabled:
- name: LoadAwareScheduling
...
score:
enabled:
- name: LoadAwareScheduling
weight: 1
...
reserve:
enabled:
- name: LoadAwareScheduling
...
pluginConfig:
# configure the thresholds and weights for the plugin
- name: LoadAwareScheduling
args:
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: LoadAwareSchedulingArgs
# whether to filter nodes where koordlet fails to update NodeMetric
filterExpiredNodeMetrics: true
# the expiration threshold seconds when using NodeMetric
nodeMetricExpirationSeconds: 300
# weights of resources
resourceWeights:
cpu: 1
memory: 1
# thresholds (%) of resource utilization
usageThresholds:
cpu: 75
memory: 85
# thresholds (%) of resource utilization of Prod Pods
prodUsageThresholds:
cpu: 55
memory: 65
# enable score according Prod usage
scoreAccordingProdUsage: true
# the factor (%) for estimating resource usage
estimatedScalingFactors:
cpu: 80
memory: 70
# enable resource utilization filtering and scoring based on percentile statistics
aggregated:
usageThresholds:
cpu: 65
memory: 75
usageAggregationType: "p99"
scoreAggregationType: "p99"2.部署一个压测 Pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress-demo
namespace: default
labels:
app: stress-demo
spec:
replicas: 1
selector:
matchLabels:
app: stress-demo
template:
metadata:
name: stress-demo
labels:
app: stress-demo
spec:
containers:
- args:
- '--vm'
- '2'
- '--vm-bytes'
- '1600M'
- '-c'
- '2'
- '--vm-hang'
- '2'
command:
- stress
image: polinux/stress
imagePullPolicy: Always
name: stress
resources:
limits:
cpu: '2'
memory: 4Gi
requests:
cpu: '2'
memory: 4Gi
restartPolicy: Always
schedulerName: koord-scheduler # use the koord-scheduler$ kubectl create -f stress-demo.yaml
deployment.apps/stress-demo created等待压测 Pod 变成 Running 状态
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
stress-demo-7fdd89cc6b-gcnzn 1/1 Running 0 82s 10.0.3.114 cn-beijing.10.0.3.112 <none> <none>Pod 调度到了 cn-beijing.10.0.3.112
3.检查每个node的负载。
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cn-beijing.10.0.3.110 92m 2% 1158Mi 9%
cn-beijing.10.0.3.111 77m 1% 1162Mi 9%
cn-beijing.10.0.3.112 2105m 53% 3594Mi 28%按照输出结果显示,节点 cn-beijing.10.0.3.111 负载最低,节点 cn-beijing.10.0.3.112 的负载最高。
4.部署一个在线 Pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-with-loadaware
labels:
app: nginx
spec:
replicas: 6
selector:
matchLabels:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
# Use koord-prod to indicate that the Pod is Prod
priorityClassName: "koord-prod"
schedulerName: koord-scheduler # use the koord-scheduler
containers:
- name: nginx
image: nginx
resources:
limits:
cpu: 500m
requests:
cpu: 500m$ kubectl create -f nginx-with-loadaware.yaml
deployment/nginx-with-loadawre created5.检查调度结果
$ kubectl get pods | grep nginx
nginx-with-loadaware-5646666d56-224jp 1/1 Running 0 18s 10.0.3.118 cn-beijing.10.0.3.110 <none> <none>
nginx-with-loadaware-5646666d56-7glt9 1/1 Running 0 18s 10.0.3.115 cn-beijing.10.0.3.110 <none> <none>
nginx-with-loadaware-5646666d56-kcdvr 1/1 Running 0 18s 10.0.3.119 cn-beijing.10.0.3.110 <none> <none>
nginx-with-loadaware-5646666d56-qzw4j 1/1 Running 0 18s 10.0.3.113 cn-beijing.10.0.3.111 <none> <none>
nginx-with-loadaware-5646666d56-sbgv9 1/1 Running 0 18s 10.0.3.120 cn-beijing.10.0.3.111 <none> <none>
nginx-with-loadaware-5646666d56-z79dn 1/1 Running 0 18s 10.0.3.116 cn-beijing.10.0.3.111 <none> <none>从上述输出可知,由于集群开启了负载感知调度功能,能感知节点负载,通过运用调度策略,此时 Pod 被优先调度到除 cn-beijing.10.0.3.112 以外的节点上。
负载感知重调度
Koordinator 在过去的几个版本中,持续的演进重调度器,先后了开源完整的框架,加强了安全性,避免因过度驱逐 Pod 影响在线应用的稳定性。这也影响了重调度功能的进展,过去 Koordinator 暂时没有太多力量建设重调度能力。这一情况将会得到改变。
Koordinator v1.1 中我们新增了负载感知重调度功能。新的插件称为 LowNodeLoad,该插件配合着调度器的负载感知调度能力,可以形成一个闭环,调度器的负载感知调度在调度时刻决策选择最优节点,但随着时间和集群环境以及工作负载面对的流量/请求的变化时,负载感知重调度可以介入进来,帮助优化负载水位超过安全阈值的节点。LowNodeLoad与 K8s descheduler 的插件 LowNodeUtilization 不同的是,LowNodeLoad 是根据节点真实利用率的情况决策重调度,而 LowNodeUtilization 是根据资源分配率决策重调度。
基本原理
LowNodeLoad 插件有两个最重要的参数:
- highThresholds 表示负载水位的目标安全阈值,超过该阈值的节点上的 Pod 将参与重调度;
- lowThresholds 表示负载水位的空闲安全水位。低于该阈值的节点上的 Pod 不会被重调度。
以下图为例,lowThresholds 为45%,highThresholds 为 70%,我们可以把节点归为三类:
- 空闲节点(Idle Node)。资源利用率低于 45% 的节点;
- 正常节点(Normal Node)。资源利用率高于 45% 但低于 70% 的节点,这个负载水位区间是我们期望的合理的区间范围
- 热点节点(Hotspot Node)。如果节点资源利用率高于 70%,这个节点就会被判定为不安全了,属于热点节点,应该驱逐一部分 Pod,降低负载水位,使其不超过 70%。

在识别出哪些节点是热点后,descheduler 将会执行迁移驱逐操作,驱逐热点节点中的部分 Pod 到空闲节点上。
如果一个集群中空闲节点的总数并不是很多时会终止重调度。这在大型集群中可能会有所帮助,在大型集群中,一些节点可能会经常或短时间使用不足。默认情况下,numberOfNodes 设置为零。可以通过设置参数 numberOfNodes 来开启该能力。
在迁移前,descheduler 会计算出实际空闲容量,确保要迁移的 Pod 的实际利用率之和不超过集群内空闲总量。这些实际空闲容量来自于空闲节点,一个空闲节点实际空闲容量 = (highThresholds - 节点当前负载) * 节点总容量。假设节点 A 的负载水位是 20%,highThresholdss 是 70%,节点 A 的 CPU 总量为96C,那么 (70%-20%) * 96 = 48C,这 48C 就是可以承载的空闲容量了。
另外,在迁移热点节点时,会过滤筛选节点上的 Pod,目前 descheduler 支持多种筛选参数,可以避免迁移驱逐非常重要的 Pod。
- 按 namespace 过滤。可以配置成只筛选某些 namespace 或者过滤掉某些 namespace
- 按 pod selector 过滤。可以通过 label selector 筛选出 Pod,或者排除掉具备某些 Label 的 Pod
- 配置 nodeFit 检查调度规则是否有备选节点。当开启后,descheduler 根据备选 Pod 对应的 Node Affinity/Node Selector/Toleration ,检查集群内是否有与之匹配的 Node,如果没有的话,该 Pod 将不会去驱逐迁移。如果设置 nodeFit为 false,此时完全由 descheduler 底层的迁移控制器完成容量预留,确保有资源后开始迁移。
当筛选出 Pod 后,从 QoSClass、Priority、实际用量和创建时间等多个维度对这些 Pod 排序。
筛选 Pod 并完成排序后,开始执行迁移操作。迁移前会检查剩余空闲容量是否满足和当前节点的负载水位是否高于目标安全阈值,如果这两个条件中的一个不能满足,将停止重调度。每迁移一个 Pod 时,会预扣剩余空闲容量,同时也会调整当前节点的负载水位,直到剩余容量不足或者水位达到安全阈值。
使用示例
- 更改 koord-descheduler 配置,启用 LowNodeLoad
apiVersion: v1
kind: ConfigMap
metadata:
name: koord-descheduler-config
...
data:
koord-descheduler-config: |
apiVersion: descheduler/v1alpha2
kind: DeschedulerConfiguration
...
deschedulingInterval: 60s # 执行周期,60s执行一次 LowNodeLoad 插件
profiles:
- name: koord-descheduler
plugins:
deschedule:
disabled:
- name: "*"
balance:
enabled:
- name: LowNodeLoad # 配置开启 LowNodeLoad 插件
....
pluginConfig:
# LowNodeLoad 插件的参数
- name: LowNodeLoad
args:
apiVersion: descheduler/v1alpha2
kind: LowNodeLoadArgs
evictableNamespaces:
# include 和 exclude 是互斥的,只能配置其中一种。
# include: # include 表示只处理下面配置的 namespace
# - test-namespace
exclude:
- "kube-system" # 需要排除的 namespace
- "koordinator-system"
lowThresholds: # lowThresholds 表示空闲节点的准入水位阈值
cpu: 20 # CPU利用率为 20%
memory: 30 # Memory利用率为 30%
highThresholds: # highThresholds 表示目标安全阈值,超过该阈值的节点被判定为热点节点
cpu: 50 # CPU利用率为 50%
memory: 60 # Memory利用率为 60%
....2.部署一个压测 Pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress-demo
namespace: default
labels:
app: stress-demo
spec:
replicas: 1
selector:
matchLabels:
app: stress-demo
template:
metadata:
name: stress-demo
labels:
app: stress-demo
spec:
containers:
- args:
- '--vm'
- '2'
- '--vm-bytes'
- '1600M'
- '-c'
- '2'
- '--vm-hang'
- '2'
command:
- stress
image: polinux/stress
imagePullPolicy: Always
name: stress
resources:
limits:
cpu: '2'
memory: 4Gi
requests:
cpu: '2'
memory: 4Gi
restartPolicy: Always
schedulerName: koord-scheduler # use the koord-scheduler$ kubectl create -f stress-demo.yaml
deployment.apps/stress-demo created等待压测 Pod 变成 Running 状态
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
stress-demo-7fdd89cc6b-gcnzn 1/1 Running 0 82s 10.0.3.114 cn-beijing.10.0.3.121 <none> <none>Pod stress-demo-7fdd89cc6b-gcnzn 调度在 cn-beijing.10.0.3.121
3.检查每个节点的负载
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cn-beijing.10.0.3.121 2106m 54% 4452Mi 35%
cn-beijing.10.0.3.124 73m 1% 1123Mi 8%
cn-beijing.10.0.3.125 69m 1% 1064Mi 8%按照输出结果显示,节点 cn-beijing.10.0.3.124 和 cn-beijing.10.0.3.125 负载最低,节点 cn-beijing.10.0.3.112 的负载最高,超过了配置的 highThresholds。
4.观察 Pod 变化,等待重调度器执行驱逐迁移操作
$ kubectl get pod -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
stress-demo-7fdd89cc6b-l7psv 1/1 Running 0 4m45s 10.0.3.127 cn-beijing.10.0.3.121 <none> <none>
stress-demo-7fdd89cc6b-l7psv 1/1 Terminating 0 8m34s 10.0.3.127 cn-beijing.10.0.3.121 <none> <none>
stress-demo-7fdd89cc6b-b4c5g 0/1 Pending 0 0s <none> <none> <none> <none>
stress-demo-7fdd89cc6b-b4c5g 0/1 Pending 0 0s <none> <none> <none> <none>
stress-demo-7fdd89cc6b-b4c5g 0/1 Pending 0 0s <none> cn-beijing.10.0.3.124 <none> <none>
stress-demo-7fdd89cc6b-b4c5g 0/1 ContainerCreating 0 0s <none> cn-beijing.10.0.3.124 <none> <none>
stress-demo-7fdd89cc6b-b4c5g 0/1 ContainerCreating 0 3s <none> cn-beijing.10.0.3.124 <none> <none>
stress-demo-7fdd89cc6b-b4c5g 1/1 Running 0 20s 10.0.3.130 cn-beijing.10.0.3.124 <none> <none>5.观察 Event,可以看到如下迁移记录
$ kubectl get event |grep stress-demo-7fdd89cc6b-l7psv
2m45s Normal Evicting podmigrationjob/20c8c445-7fa0-4cf7-8d96-7f03bb1097d9 Try to evict Pod "default/stress-demo-7fdd89cc6b-l7psv"
2m12s Normal EvictComplete podmigrationjob/20c8c445-7fa0-4cf7-8d96-7f03bb1097d9 Pod "default/stress-demo-7fdd89cc6b-l7psv" has been evicted
11m Normal Scheduled pod/stress-demo-7fdd89cc6b-l7psv Successfully assigned default/stress-demo-7fdd89cc6b-l7psv to cn-beijing.10.0.3.121
11m Normal AllocIPSucceed pod/stress-demo-7fdd89cc6b-l7psv Alloc IP 10.0.3.127/24
11m Normal Pulling pod/stress-demo-7fdd89cc6b-l7psv Pulling image "polinux/stress"
10m Normal Pulled pod/stress-demo-7fdd89cc6b-l7psv Successfully pulled image "polinux/stress" in 12.687629736s
10m Normal Created pod/stress-demo-7fdd89cc6b-l7psv Created container stress
10m Normal Started pod/stress-demo-7fdd89cc6b-l7psv Started container stress
2m14s Normal Killing pod/stress-demo-7fdd89cc6b-l7psv Stopping container stress
11m Normal SuccessfulCreate replicaset/stress-demo-7fdd89cc6b Created pod: stress-demo-7fdd89cc6b-l7psvcgroup v2 支持
背景
Koordinator 中众多单机 QoS 能力和资源压制/弹性策略构建在 Linux Control Group (cgroups) 机制上,比如 CPU QoS (cpu)、Memory QoS (memory)、CPU Burst (cpu)、CPU Suppress (cpu, cpuset),koordlet 组件可以通过 cgroups (v1) 限制容器可用资源的时间片、权重、优先级、拓扑等属性。Linux 高版本内核也在持续增强和迭代了 cgroups 机制,带来了 cgroups v2 机制,统一 cgroups 目录结构,改善 v1 中不同 subsystem/cgroup controller 之间的协作,并进一步增强了部分子系统的资源管理和监控能力。Kubernetes 自 1.25 起将 cgroups v2 作为 GA (general availability) 特性,在 Kubelet 中启用该特性进行容器的资源管理,在统一的 cgroups 层次下设置容器的资源隔离参数,支持 MemoryQoS 的增强特性。
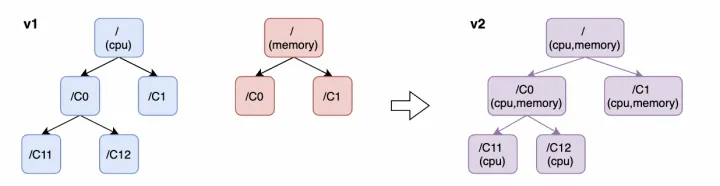

- 重构了 Resource Executor 模块,以统一相同或近似的 cgroup 接口在 v1 和 v2 不同版本上的文件操作,便于 koordlet 特性兼容 cgroups v2 和合并读写冲突。
- 在当前已开放的单机特性中适配 cgroups v2,采用新的 Resource Executor 模块替换 cgroup 操作,优化不同系统环境下的报错日志。
Koordinator v1.1 中大部分 koordlet 特性已经兼容 cgroups v2,包括但不限于:
- 资源利用率采集
- 动态资源超卖
- Batch 资源隔离(BatchResource,废弃BECgroupReconcile)
- CPU QoS(GroupIdentity)
- Memory QoS(CgroupReconcile)
- CPU 动态压制(BECPUSuppress)
- 内存驱逐(BEMemoryEvict)
- CPU Burst(CPUBurst)
- L3 Cache 及内存带宽隔离(RdtResctrl)
遗留的未兼容特性如 PSICollector 将在接下来的 v1.2 版本中进行适配,可以跟进 issue#407 获取最新进展。接下来的 Koordinator 版本中也将逐渐引入更多 cgroups v2 的增强功能,敬请期待。
使用 cgroups v2
在 Koordinator v1.1 中,koordlet 对 cgroups v2 的适配对上层功能配置透明,除了被废弃特性的 feature-gate 以外,您无需变动 ConfigMap slo-controller-config和其他 feature-gate 配置。当 koordlet 运行在启用 cgroups v2 的节点上时,相应单机特性将自动切换到 cgroups-v2 系统接口进行操作。
此外,cgroups v2 是 Linux 高版本内核(建议 >=5.8)的特性,对系统内核版本和 Kubernetes 版本有一定依赖。建议采用默认启用 cgroups v2 的 Linux 发行版以及 Kubernetes v1.24 以上版本。
更多关于如何启用 cgroups v2 的说明,请参照 Kubernetes 社区文档。
文档: https://kubernetes.io/docs/concepts/architecture/cgroups/#using-cgroupv2
在 koordlet 中开发支持 cgroups v2 的功能
如果您期望在 koordlet 组件中开发和定制支持 cgroups v2 的新功能,欢迎了解 Koordinator v1.1 中新增的系统资源接口Resource和系统文件操作模块ResourceExecutor,它们旨在优化如 cgroups、resctrl 等系统文件操作的一致性和兼容性。
您可以通过下面的方式,操作常见的 cgroups 接口,修改容器的资源隔离参数:
var (
// NewCgroupReader() generates a cgroup reader for reading cgroups with the current cgroup version.
// e.g. read `memory.limit_in_bytes` on v1, while read `memory.max` on v2.
cgroupReader = resourceexecutor.NewCgroupReader()
// NewResourceUpdateExecutor() generates a resource update executor for updating system resources (e.g. cgroups, resctrl) cacheablely and in order.
executor = resourceexecutor.NewResourceUpdateExecutor()
)
// readPodCPUSet reads the cpuset CPU IDs of the given pod.
// e.g. read `/sys/fs/cgroup/cpuset/kubepods.slice/kubepods-podxxx.slice/cpuset.cpus` -> `6-15`
func readPodCPUSet(podMeta *statesinformer.PodMeta) (string, error)
podParentDir := koordletutil.GetPodCgroupDirWithKube(podMeta.CgroupDir)
cpus, err := cgroupReader.ReadCPUSet(podParentDir)
if err != nil
return "", err
return cpus.String(), nil
func updatePodCFSQuota(podMeta *statesinformer.PodMeta, cfsQuotaValue int64) error
podDir := koordletutil.GetPodCgroupDirWithKube(podMeta.CgroupDir)
cfsQuotaStr := strconv.FormatInt(cfsQuotaValue, 10)
// DefaultCgroupUpdaterFactory.New() generates a cgroup updater for cacheable updating cgroups with the current cgroup version.
// e.g. update `cpu.cfs_quota_us` on v1, while update `cpu.max` on v2.
updater, err := resourceexecutor.DefaultCgroupUpdaterFactory.New(system.CPUCFSQuotaName, podParentDir, cfsQuotaStr)
if err != nil
return err
// Use executor to cacheable update the cgroup resource, and avoid the repeated but useless writes.
_, err := executor.Update(true, updater)
if err != nil
return err
return nil
您也可以通过下面的方式,新增和注册 cgroups 资源和更新函数:
// package system
const (
// Define the cgroup filename as the resource type of the cgroup resource.
CgroupXName = "xx.xxx"
CgroupYName = "yy.yyy"
CgroupXV2Name = "xx.xxxx"
CgroupYV2Name = "yy.yy"
)
var (
// New a cgroup v1 resource with the filename and the subsystem (e.g. cpu, cpuset, memory, blkio).
// Optional: add a resource validator to validate the written values, and add a check function to check if the system supports this resource.
CgroupX = DefaultFactory.New(CgroupXName, CgroupXSubfsName).WithValidator(cgroupXValidator).WithCheckSupported(cgroupXCheckSupportedFunc)
CgroupY = DefaultFactory.New(CgroupYName, CgroupYSubfsName)
// New a cgroup v2 resource with the corresponding v1 filename and the v2 filename.
// Optional: add a resource validator to validate the written values, and add a check function to check if the system supports this resource.
CgroupXV2 = DefaultFactory.NewV2(CgroupXName, CgroupXV2Name).WithValidator(cgroupXValidator).WithCheckSupported(cgroupXV2CheckSupportedFunc)
CgroupYV2 = DefaultFactory.NewV2(CgroupYName, CgroupYV2Name).WithCheckSupported(cgroupYV2CheckSupportedFunc)
)
func init()
// Register the cgroup resource with the corresponding cgroup version.
DefaultRegistry.Add(CgroupVersionV1, CgroupX, CgroupY)
DefaultRegistry.Add(CgroupVersionV2, CgroupXV2, CgroupYV2)
// package resourceexecutor
func init()
// Register the cgroup updater with the resource type and the generator function.
DefaultCgroupUpdaterFactory.Register(NewCommonCgroupUpdater,
system.CgroupXName,
system.CgroupYName,
干扰检测指标采集
在真实的生产环境下,单机的运行时状态是一个“混沌系统”,资源竞争产生的应用干扰无法绝对避免。Koordinator 正在建立干扰检测与优化的能力,通过提取应用运行状态的指标,进行实时的分析和检测,在发现干扰后对目标应用和干扰源采取更具针对性的策略。
当前 Koordinator 已经实现了一系列 Performance Collector,在单机侧采集与应用运行状态高相关性的底层指标,并通过 Prometheus 暴露出来,为干扰检测能力和集群应用调度提供支持。
指标采集
Performance Collector 由多个 feature-gate 进行控制,Koordinator 目前提供以下几个指标采集器:
- CPICollector:用于控制 CPI 指标采集器。CPI:Cycles Per Instruction。指令在计算机中执行所需要的平均时钟周期数。CPI 采集器基于 Cycles 和 Instructions 这两个 Kernel PMU(Performance Monitoring Unit)事件以及 perf_event_open(2) 系统调用实现。
- PSICollector:用于控制 PSI 指标采集器。PSI:Pressure Stall Information。表示容器在采集时间间隔内,因为等待 cpu、内存、IO 资源分配而阻塞的任务数。使用 PSI 采集器前,需要在 Anolis OS 中开启 PSI 功能,您可以参考文档获取开启方法。
Performance Collector 目前是默认关闭的。您可以通过修改 Koordlet 的 feature-gates 项来使用它,此项修改不会影响其他 feature-gate
kubectl edit ds koordlet -n koordinator-system...
spec:
...
spec:
containers:
- args:
...
# modify here
# - -feature-gates=BECPUEvict=true,BEMemoryEvict=true,CgroupReconcile=true,Accelerators=true
- -feature-gates=BECPUEvict=true,BEMemoryEvict=true,CgroupReconcile=true,Accelerators=true,CPICollector=true,PSICollector=trueServiceMonitor
v1.1.0 版本的 Koordinator 为 Koordlet 增加了 ServiceMonitor 的能力,将所采集指标通过 Prometheus 暴露出来,用户可基于此能力采集相应指标进行应用系统的分析与管理。
apiVersion: v1
kind: Service
metadata:
labels:
koord-app: koordlet
name: koordlet
namespace: koordinator-system
spec:
clusterIP: None
ports:
- name: koordlet-service
port: 9316
targetPort: 9316
selector:
koord-app: koordlet
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
koord-app: koordlet
name: koordlet
namespace: koordinator-system
spec:
endpoints:
- interval: 30s
port: koordlet-service
scheme: http
jobLabel: koord-app
selector:
matchLabels:
koord-app: koordletServiceMonitor 由 Prometheus 引入,故在 helm chart 中设置默认不开启安装,可以通过以下命令安装ServiceMonitor:
helm install koordinator https://... --set koordlet.enableServiceMonitor=true部署后可在 Prometheus UI 找到该 Targets:

# HELP koordlet_container_cpi Container cpi collected by koordlet
# TYPE koordlet_container_cpi gauge
koordlet_container_cpicontainer_id="containerd://498de02ddd3ad7c901b3c80f96c57db5b3ed9a817dbfab9d16b18be7e7d2d047",container_name="koordlet",cpi_field="cycles",node="your-node-name",pod_name="koordlet-x8g2j",pod_namespace="koordinator-system",pod_uid="3440fb9c-423b-48e9-8850-06a6c50f633d" 2.228107503e+09
koordlet_container_cpicontainer_id="containerd://498de02ddd3ad7c901b3c80f96c57db5b3ed9a817dbfab9d16b18be7e7d2d047",container_name="koordlet",cpi_field="instructions",node="your-node-name",pod_name="koordlet-x8g2j",pod_namespace="koordinator-system",pod_uid="3440fb9c-423b-48e9-8850-06a6c50f633d" 4.1456092e+09可以期待的是,Koordinator 干扰检测的能力在更复杂的真实场景下还需要更多检测指标的补充,后续将在如内存、磁盘 IO 等其他诸多资源的指标采集建设方面持续发力。
其他更新点
通过 v1.1 release 页面,可以看到更多版本所包含的新增功能。
v1.1 release: https://github.com/koordinator-sh/koordinator/releases/tag/v1.1.0
未来规划
Koordinator 社区将不断丰富大数据计算任务混部的形态,拓展多种计算框架混部支持,丰富任务混部解决方案,项目上持续的完善干扰检测、问题诊断体系,推进更多的负载类型融入 Koordinator 生态,并取得更好的资源运行效率。
Koordinator 社区将持续的保持中立的发展趋势,联合各厂商持续的推进混部能力的标准化,也欢迎大家加入社区共同推荐混部的标准化进程。
作者:Koordinator 社区
本文为阿里云原创内容,未经允许不得转载。
以上是关于Koordinator v1.1发布:负载感知与干扰检测采集的主要内容,如果未能解决你的问题,请参考以下文章
Koordinator 一周年,新版本 v1.2.0 支持节点资源预留,兼容社区重调度策略
Koordinator v0.7: 为任务调度领域注入新活力
Koordinator 0.6:企业级容器调度系统解决方案,引入 CPU 精细编排资源预留与全新的重调度框架