Zeus资源调度系统介绍
Posted duanxz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zeus资源调度系统介绍相关的知识,希望对你有一定的参考价值。
摘要: 本文主要概述阿里巴巴Zeus资源调度系统的背景和实现思路。 本文主线:问题、解决方案、依赖基础知识、工程实践、目标、经验分享。立足企业真实问题、常规解决策略,引出依赖的容器技术、实践方案,所有这些落实到工程实践,要解决那些问题、实现哪些目标、技术大趋势的影响。最后给出阿里巴巴的实践经验。本序列文章并不是突出架构上重大突破,毕竟这个领域已经发展了10多年了。而是,实践过程中的一些细节、一些特殊场景下的特殊处理方法,作为一种新的认知素材。依赖的容器或周边系统,都不会进行深入的分析,围绕资源调度概括性地做一些总结和补充些细节描述。
关键词:容器技术 资源调度
1. 什么是宙斯(Zeus)
宙斯是阿里巴巴开源的一款分布式Hadoop作业调度平台,支持多机器的水平扩展。Zeus是一款完全分布式的调度系统,,支持多机器的水平扩展,一台机器为一个节点,由master节点分发任务至不同的worker,实现任务的分布式调度。目前支持的任务类型主要由hive脚本和shell脚本。Zeus不仅仅可以执行独立任务调度,还支持任务之间依赖调度。这就使得zeus完全不同于传统的任务调度系统中,任务只能单个任务之间调度,这也是zeus的设计中一大亮点。
2. Zeus的架构设计
软件架构设计
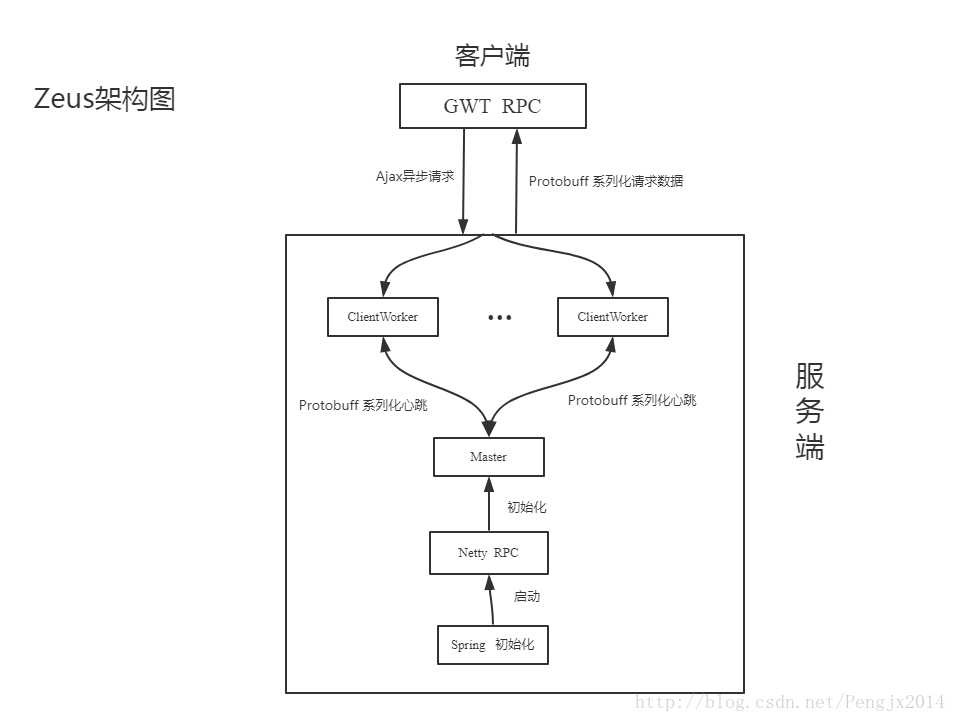
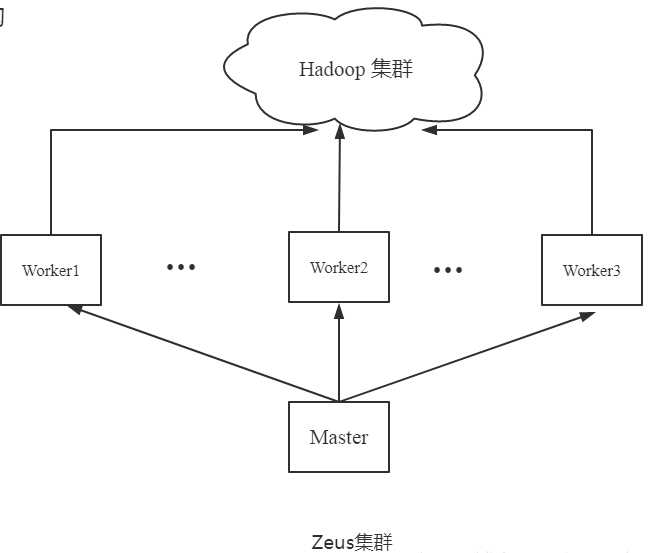
集群架构设计
3. Zeus核心模块分析
宙斯核心模块分为zeus-schedule,zeus-web,即宙斯调度层和宙斯web层,其中zeus-schedule负责的主要功能是RPC通信与任务调度,zeus-web提供一种web层的交互.后面将开始源码解读。
1.背景:资源浪费剖析
企业里面资源调度的存在或者必要性,与企业发展规模有很强的关联关系。任何企业从一开始就有某种程度的、某种特有阶段性的“服务器资源分配使用方案”,只是对资源或者成本“优化”的度,或者效率的要求急迫性、重要性不是那么突出。当服务器数量以万为单位增长,成本支出过亿的大背景下,依赖面向容器技术的资源调度和管理,显得非常急迫和重要。制定执行成本优化目标,落到实践中,首先需要对资源浪费、已有系统的缺陷、资源利用率不高进行系统化的诊断,然后执行平稳的逐步优化、提升效率、利用率。这就是问题或者需求的源头。
(1)资源管理混乱
资源管理系统没有掌握资源的利用情况,当前的资源利用率是怎么样的,有哪些空闲资源不是太清楚。甚至有些资源脱离了系统的管理,成为僵尸资源。这样造成了大量可用资源的闲置和浪费。
(2)申请和使用不一致
例如,营销或者宣传活动,申请几百台资源实例,由于业务没有预期那么好,或者预留buffer,应对超预期压力。最终的结果是申请和使用不一致。活动期间,白天整体利用率偏高,晚上整体利用率偏低。例如,初期资源少,每一次申请和使用的一致性,并没有系统统一追踪沉淀、统一透明化度量,业务慢慢发展了,单纯申请机器扩容不一定是最佳的。软件是否也需要进行优化升级了呢。容量评估和预测、历史趋势追踪预测等系统完善度直接影响申请和使用的过程一致性、长期一致性。
(3)在线业务的访问低谷期间资源浪费
对于网站来说,访问量是呈现成曲线分布的,有高峰有低谷。在访问高峰的时候资源利用率比较高,在访问低谷的时候,则资源比较闲置,从而造成大量资源的浪费
(4)故障修复
机器的磁盘、内存条、网卡,随时都会坏掉,统计概率大约是万分之三,一旦坏掉了,进入维修流程。1万台规模,每天来个3、5台,一个礼拜也就20多台,再花个1个礼拜慢慢修复。修复了,回归可用资源池又是一段时间。这种浪费是隐形的,很零碎。一年下来累计的不可用工作小时非常大。故障自动识别、自动脚本处理、故障预警等直接影响效率、准确率。
(5)可达效率
在IT软件中,基本上没有解决不了的问题。系统分层、功能弱化总是能够把问题的影响或者问题的复杂度降到最低,最终达到服务可上线的目标。系统之间的这种分层或者功能弱化形成的依赖关系,上下游之间的可达效率,其实也非常影响系统的整体资源利用率。例如:A上游RT、QPS非常大,A下游B能够处理的吞吐量大,但是RT相对增长,整体链路可达效率逐层降低。适当的整合能够带来一定的资源利用率提升。
2. Zeus介绍
Zeus是一个资源调度系统,它对数据中心的服务器资源进行统一的调度和分配。它的主要功能包括:
(1) 对数据中心的物理资源进行了封装,隐藏了其中的细节。对于外界来说,整个数据中心就像是一台巨大的服务器,对外提供CPU, 内存,存储,网络等资源。应用开发者不需要关心自己的应用部署在哪台服务器上。
(2) 接收应用的资源申请请求,为应用调度分配资源。
(3) 优化成本。通过超卖,混合部署等方法提高资源利用率,节约成本。
(4) 提升系统稳定性。Zeus在进行资源调度时,会监控系统的软硬件故障,确保有故障的资源不被分配,对有问题的物理资源进行跟踪处理。
3. 资源的虚拟化
Zeus使用LXC容器技术对物理资源进行切分隔离,在CPU、Memory、Disk、Network量化后的数据基础上,按照固定或者分时共享,实现资源动态共享,整体提升物理机的资源利用率。容器技术还有其他的优势,例如屏蔽硬件的异构性,带来面向API的资源分配和数据沉淀,从而为资源预测提供了规范、统一的数据。另外,容器技术是云时代的加速器,以Docker容器为代表的容器技术极大的方便了应用运维管理。当然容器技术从某种角度看,也有一些不足,不能应用在所有场景当中、难以解决依赖关系问题、较差的隔离性、潜在的蔓延问题、缺乏工具。
容器技术把硬件等计算、存储、传输资源进行了无状态性、相对透明的共享。容器内的具体任务以及容器的生命周期等管理,交给了上层业务进行管理、运维。
从任务实现的语言来看,一类是编译型语言(C、C++、Golang)实现的服务,一类是解释型语言(Java、php、javascript)。对于前者,进程启动时并不需要一次性hold住固定大内存,对于后者特别是java,在进程启动时候,配置固定内存开销。两种不同类型语言,使得物理机内存资源的动态共享模型有所不同,而Cgroup实现的CPU Set或者CPU子系统,可以动态共享CPU。磁盘IO、网络IO通过队列、聚合等也可以执行“限流”。另外,在单JVM进程中,合并部署多个应用,或者单JVM进程中,通过租用的方式,启动多个服务,共享同一个JVM进程。
从资源生命周期看,长期租用、短期租用、不定时租用。不定时租用对应的往往是分时共享,而长期租用多半是固定配额共享或者专有共享。资源在时间、粒度、上下文环境一致、业务类型上进行平衡。
不论哪种角度看共享,只要有共享,就必须保障基础环境的一致性,不能因为共享者的环境变更导致其他服务受影响。实时环境巡检也就必不可少。
在一个大的生态性质的资源调度管理系统中,上面这些往往同时存在不同的业务集群中。在一个业务集群中、抽象出一套综合的策略是很难满足多场景需求的。不同业务集群,在底层的硬件抽象、运维监控管理工具是可以统一的。资源共享的粒度、时机,可以多样化。
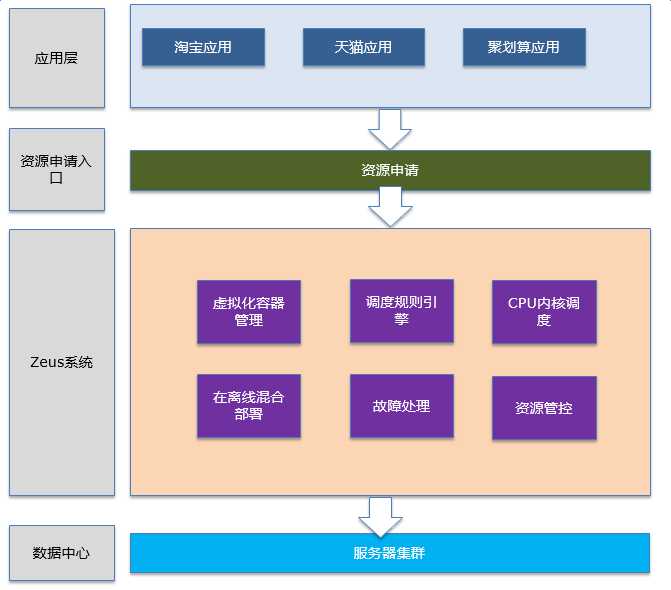
4. 技术架构
Zeus主要采取分布式二层架构模式,分配策略空闲优先,融合业务相亲相近、负载错峰、业务稳定性等多种约束条件,基于超卖的资源共享。调度并发上,选择资源是全局排序,采取的编程语言是Golang。容器服务的对象集中在在线Service。在线离线混部部分,采取分时共享资源。通过周边多个系统的协调,为公司每年节约大量成本,并且所使用的策略是常态化的。也有一些一次性的策略,针对11大促特殊场景的需求。
Zeus从稳定性,资源利用率,运维自动化这三个方面来考虑调度的问题。实时监控基础设施层的故障,并进行自动化处理,对上层应用屏蔽掉故障,从而提升系统的稳定性。通过多种调度策略,以及混合部署等方案提升资源利用率。通过提升调度的成功率,提供多种数据分析工具和数据视图提升运维自动化程度。
架构图如下
5. 资源利用率
5.1 超卖
应用在申请的资源的时候,往往会申请比他实际使用更多的资源。也就是说他申请的资源,在实际使用中,他是用不了这么多资源的。这样就形成了资源的浪费。我们通过超卖来解决这个问题。
超卖带来的挑战就是,超卖多少比较合适。如果超卖多了,会引起资源竞争,导致系统的不稳定。如果超卖少了,会导致资源的浪费。我们需要找到一个平衡点,既不会影响系统的稳定性,也不会有很多的资源浪费。解决方案就是实行动态的超卖系数。先设置一个比较低的超卖系数,然后在系统运行的过程中,采集分析资源利用率情况,根据资源利用率的实际情况调高或者调低超卖系数。
5.2 混合部署
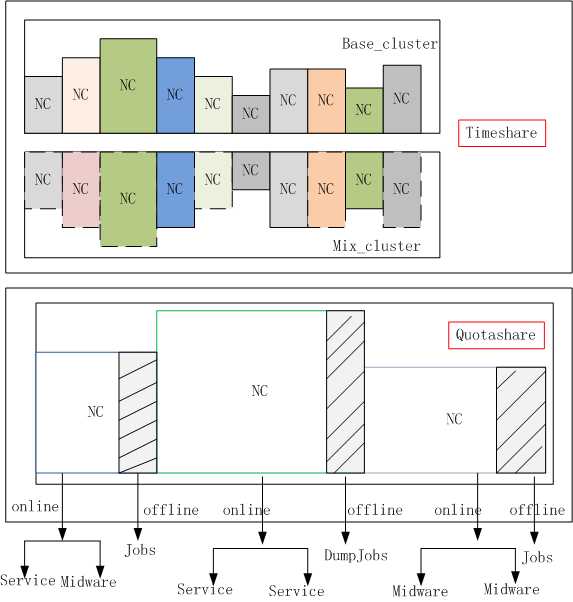
离线任务(Jobs或者短周期任务)、在线任务(service或者长周期任务)通过合并部署来共享宿主机资源。一种是实时错峰共享资源,当调度系统发现当前在线任务的资源利用率比较低的时候,把离线任务调度上来运行,从而提高资源的利用率。但要确保在线任务优先抢占资源,如果发生离线任务和在线任务争抢资源的情况,要杀掉离线任务,把资源让给在线任务。一种是固定配额来共享,service和jobs固定一定的资源,然后根据service空闲周期,jobs加大资源计算,动态调整CPU资源,假设内存、IO都不是瓶颈,也就是部分的调整资源给jobs。或者不关注service空闲,在jobs固定配额内自由提交jobs计算。这种时间窗口越短,对任务切换要求能力更高,需要资源实时预测模型。例如 Borg系统,针对进程最近时刻内存开销进行实时调整。这对C、C++是有益处的,而对java就很难快速实施了,因为需要改JVM参数,从而JVM需要重启,然后是业务代码重启。一种是分时独占交付,在service空闲周期内,service停止服务,完整的将资源空闲出来给jobs使用。
5.3 减少资源碎片
在资源分配的时候,有两种方式,一种是凑整分配,一种是打散分配。凑整分配就是尽量将一台宿主机分配满,这台宿主机分配满了以后,再去分配到别的宿主机。这种分配方式的好处是资源碎片比较少,资源利用率比较高,但容易造成资源竞争,系统不稳定。打散分配就是每次分配的时候找到空闲资源最多的宿主机进行分配,这种分配方式的好处是各个宿主机的负载比较均衡,但是会造成较多的资源碎片。Zeus的处理方法是在这两种方式之间找到一个平衡点,同时考虑凑整和负载均衡的问题,既要减少资源的碎片,也要考虑负载的适当均衡。
6. 稳定性
6.1 故障处理
Zeus会实时监控基础设施层的各种软硬件故障。提前发现大量软硬件或操作系统故障的宿主机,并标记为unavailable,线下定期处理。定期处理并回收失联及load过高的宿主机(数10台),成本回收并提高应用运行稳定性。提供黑名单机制,能快速屏蔽故障机和测试机,提高用户操作效率。能提前发现IP冲突等网络问题,并定期解决。
6.2 稳定性调度策略
通过如下图所示的各种调度策略来确保系统的稳定性。
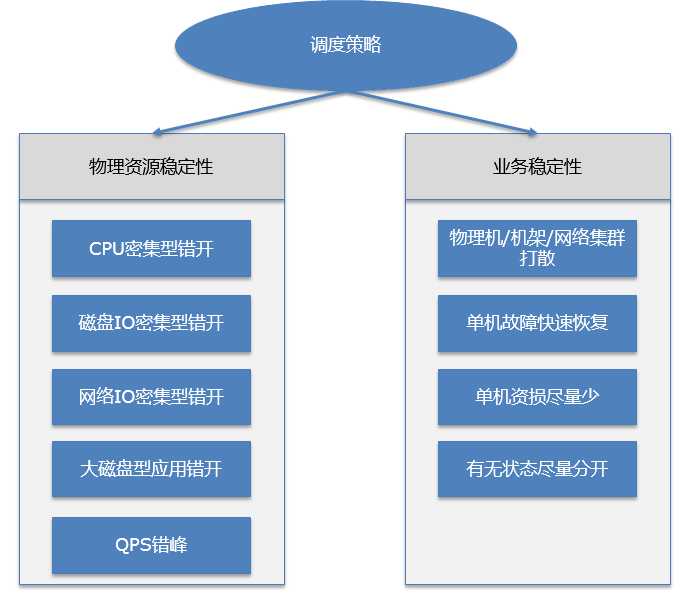
6.2 大促稳定性
在类似双11这种大型促销的活动中,由于负载超出平时数倍,会出现各种资源竞争异常的情况。Zeus通过对应用部署的自动洗牌,定点迁移,容器内核的调整等方式确保大促的稳定运行,不出现资源竞争的问题。
7. 运维自动化
Zeus能够自动化的处理各种软硬件故障,大大降低人工干预的程度,从而提高了运维自动化程度。Zeus大大提升了应用扩容的成功率,为弹性伸缩的自动化运行也提供了可靠的保证。
Zeus还提供了多维度的运维工具,可以让运维人员轻松的对资源进行控制和管理,提升了运维自动化程度。
转载:https://blog.csdn.net/iie_libi/article/details/71597971,原文链接:https://blog.csdn.net/Pengjx2014/article/details/78380300
8. 参考链接
[1]http://news.oneapm.com/cloud-oneapm/
[2]http://2016.qconbeijing.com/presentation/2878
[3]http://www.linuxjournal.com/content/containers%E2%80%94not-virtual-machines%E2%80%94are-future-cloud]
[4]http://www.innoarchitech.com/in-depth-look-container-technology-caas-next-big-thing-tech/
[5]http://news.oneapm.com/cloud-oneapm/
[6]http://searchservervirtualization.techtarget.com/feature/Five-cons-of-container-technology
[7] Abhishek Vermay, Luis Pedrosaz, Madhukar Korupolu, David Oppenheimer, Eric Tune, John Wilkes. Large-scale cluster management at Google with Borg
[8]http://ju.outofmemory.cn/entry/21397
[9]http://www.cngulu.com/2870.html [10]http://www.umbrant.com/blog/2015/mesos_omega_borg_survey.html
以上是关于Zeus资源调度系统介绍的主要内容,如果未能解决你的问题,请参考以下文章