为什么graphql可以替代restful?
Posted 架构师之巅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么graphql可以替代restful?相关的知识,希望对你有一定的参考价值。
引言
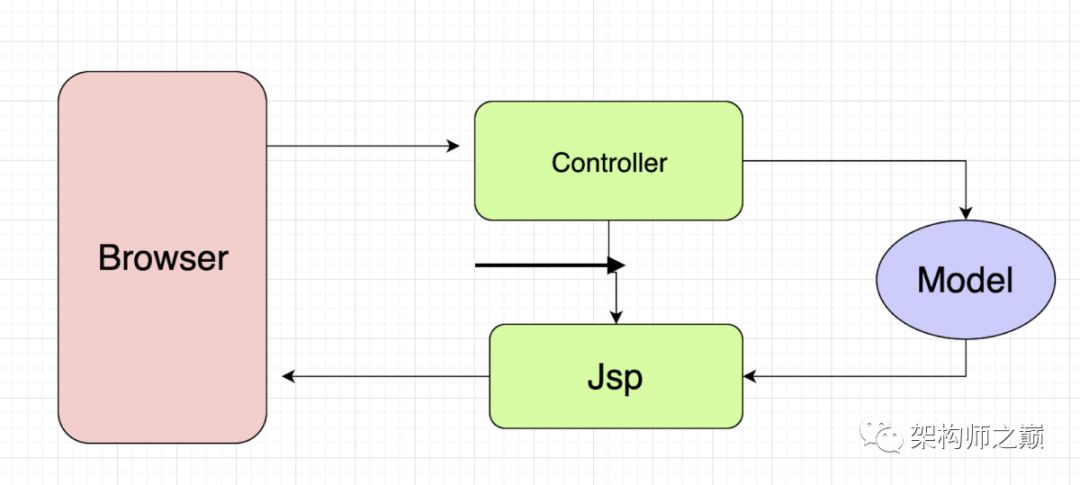
上图是笔者刚参加工作的时候使用的架构图,当时前后端并未分离,所有代码都刚在一个工程里,如果后端代码改了,前端代码得跟着改,每次改一点,都需要触动全身,非常痛苦;
前后端架构
后来随着公司壮大之后,项目功能也越来越多,改动量也越来越大,实在受不了这种低效率的开发模式了,后来改造成前后端分离的架构,说到前后端分离,它主要分为半分离和完全分离两种类型。
前后端半分离
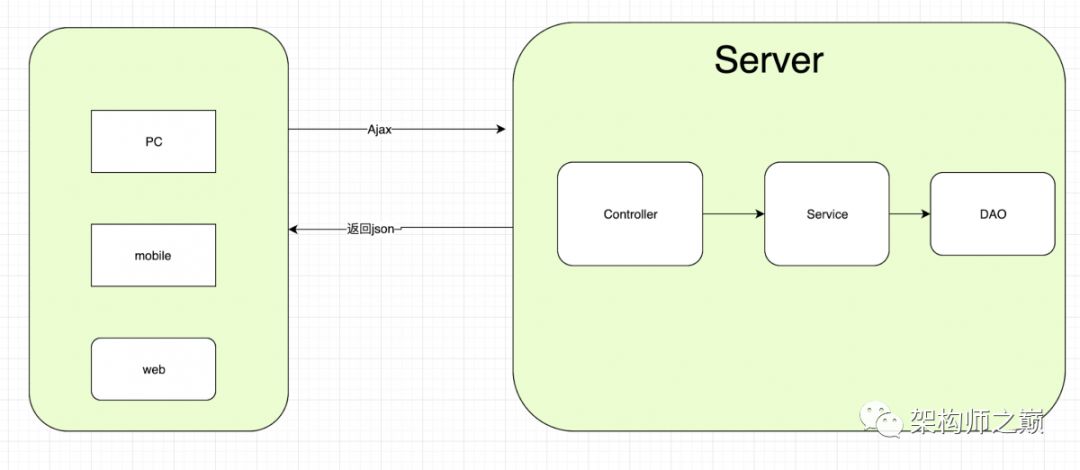
上图是前后端半分离的架构,为什么说是半分离,因为不是所有页面都是单页面应用,在多页面应用的情况下,前端因为没有掌握controller层,前端需要跟后端讨论,我们这个页面是要同步输出呢,还是异步json渲染呢?因此,在这一阶段,只能算半分离。
前后端完全分离
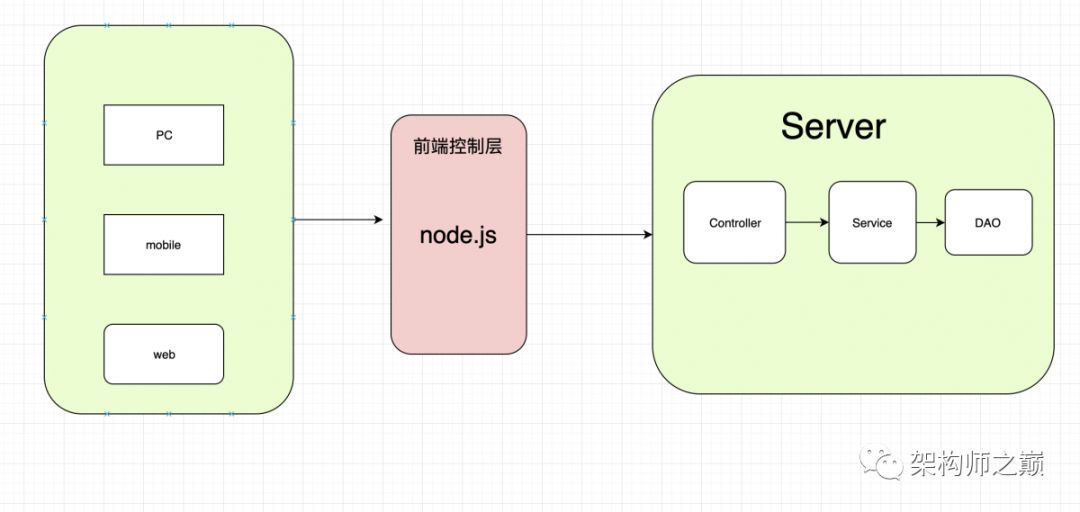
上图是完全分离的前后端架构,在这一时期,扩展了前端的范围。认为controller层也属于前端的一部分。在这一时期 前端:负责View和Controller层。后端:只负责Model层,业务处理/数据等。可是前端不懂后台代码呀?controller层如何实现呢?这就是node.js的妙用了,node.js适合运用在高并发、I/O密集、少量业务逻辑的场景。最重要的一点是,前端不用再学一门其他的语言了,对前端来说,上手度大大提高。
restful 简介
说到restful,很多人第一反应是“啊,你说的restful就是那个前后端分离的api吗”,在RESTful架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词,而且所用的名词往往与数据库的表格名对应。一般来说,数据库中的表都是同种记录的"集合"(collection),所以API中的名词也应该使用复数。
举例来说,有一个API提供动物园(zoo)的信息,还包括各种动物和雇员的信息,则它的路径应该设计成下面这样。
1、https://api.example.com/v1/zoos
2、https://api.example.com/v1/animals
3、https://api.example.com/v1/employees
对于资源的具体操作类型,由HTTP动词表示。常用的HTTP动词有下面五个(括号里是对应的SQL命令)。
1、GET(SELECT):从服务器取出资源(一项或多项)。
2、POST(CREATE):在服务器新建一个资源。
3、PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
4、PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
5、DELETE(DELETE):从服务器删除资源。
比如说我要获取一笔orderid为5的订单详情,通常我们都会这样设计;
GET /orders/5创建一笔新订单,我们一般会这样设计:
POST /ordersrestful 缺陷
前端程序员小红希望在 某个restful api接口中新增一个返回值,后端程序员小明由于忙着谈恋爱,没有时间排期增加;这是restful 第一个缺点,前端请求某个接口,希望新增字段的时候,增加了额外的沟通成本;
过了几天,前端程序员小红发现,现有接口无缘无故多返回了几个她不需要的属性,由于web,andorid,ios三个客户端请求的都是同一个接口,因此小明把这三个客户端所有的返回值都返回了。而这些额外的字段,小红并不需要,而且也增加了小红解析返回值的成本。这是restful的第二个缺点,接口的契约只能约定俗成,不能动态按需的请求字段。
graphql 简介
GraphQL 是一个用于 API 的查询语言,是一个使用基于类型系统来执行查询的服务端运行时(类型系统由你的数据定义)。GraphQL 并没有和任何特定数据库或者存储引擎绑定,而是依靠你现有的代码和数据支撑。
这是官网的一段简介,可能听起来有点蒙蔽;简单的说就是之前restful设计的接口,都是由后端控制的,后端接口一旦确定了,就很难更改,因为是很多客户端都使用这个接口,所以无法按照某个特定的客户端去做定制,而且那样成本也是特别高。但是使用graphql就不一样了,数据的主动权掌握在客户端这里,客户端想要什么样的数据,自己直接去请求就好了,无须服务端去做改动。
一个 GraphQL 服务是通过定义类型和类型上的字段来创建的,然后给每个类型上的每个字段提供解析函数。例如,一个 GraphQL 服务告诉我们当前登录用户是 me,这个用户的名称可能像这样:
type Query {
me: User
}
type User {
id: ID
name: String
}
一并的还有每个类型上字段的解析函数:
function Query_me(request) {
return request.auth.user;
}
function User_name(user) {
return user.getName();
}
一旦一个 GraphQL 服务运行起来(通常在 web 服务的一个 URL 上),它就能接收 GraphQL 查询,并验证和执行。接收到的查询首先会被检查确保它只引用了已定义的类型和字段,然后运行指定的解析函数来生成结果。
例如这个查询:
{
me {
name
}
}
会产生这样的JSON结果:
{
"me": {
"name": "Luke Skywalker"
}
}
这个时候,前端小红希望在要一个age属性,那就可以这样写:
{
me {
name
age
}
}
服务端产生的json结果如下:
{
"me": {
"name": "Luke Skywalker",
"age":12
}
}
你看,想要什么字段就在查询语句里增加字段即可,也不用和后端程序员沟通,而后端程序员也可以愉快的谈恋爱了。
Java 操作 graphql
spring-boot 是基于 2.0.0版本,首先加入以下依赖:
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-spring-boot-starter</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java-tools</artifactId>
<version>4.3.0</version>
</dependency>
下面是graphql服务的入口定义:
type Query {
bookById(id: ID): Book
}
type Book {
id: ID
name: String
pageCount: Int
author: Author
}
type Author {
id: ID
firstName: String
lastName: String
}
graphql 入口定义了, 但这只是一个描述, 我们需要实现 query中的描述, 在实际开发中,数据的查询应该从db中获取,这里为了方便直接在程序中写死了。
@Component
public class GraphQLDataFetchers {
private static List<Map<String, String>> books = Arrays.asList(
ImmutableMap.of("id", "book-1",
"name", "Harry Potter and the Philosopher's Stone",
"pageCount", "223",
"authorId", "author-1"),
ImmutableMap.of("id", "book-2",
"name", "Moby Dick",
"pageCount", "635",
"authorId", "author-2"),
ImmutableMap.of("id", "book-3",
"name", "Interview with the vampire",
"pageCount", "371",
"authorId", "author-3")
);
private static List<Map<String, String>> authors = Arrays.asList(
ImmutableMap.of("id", "author-1",
"firstName", "Joanne",
"lastName", "Rowling"),
ImmutableMap.of("id", "author-2",
"firstName", "Herman",
"lastName", "Melville"),
ImmutableMap.of("id", "author-3",
"firstName", "Anne",
"lastName", "Rice")
);
public DataFetcher getBookByIdDataFetcher() {
return dataFetchingEnvironment -> {
String bookId = dataFetchingEnvironment.getArgument("id");
// TODO 去数据库查数据
return books
.stream()
.filter(book -> book.get("id").equals(bookId))
.findFirst()
.orElse(null);
};
}
public DataFetcher getAuthorDataFetcher() {
return dataFetchingEnvironment -> {
Map<String, String> book = dataFetchingEnvironment.getSource();
String authorId = book.get("authorId");
// TODO 去数据库查数据
return authors
.stream()
.filter(author -> author.get("id").equals(authorId))
.findFirst()
.orElse(null);
};
}
}
定义GraphQL:
@Component
public class GraphQLProvider {
@Autowired
GraphQLDataFetchers graphQLDataFetchers;
private GraphQL graphQL;
@PostConstruct
public void init() throws IOException {
URL url = Resources.getResource("schema.graphqls");
String sdl = Resources.toString(url, Charsets.UTF_8);
GraphQLSchema graphQLSchema = buildSchema(sdl);
this.graphQL = GraphQL.newGraphQL(graphQLSchema).build();
}
private GraphQLSchema buildSchema(String sdl) {
TypeDefinitionRegistry typeRegistry = new SchemaParser().parse(sdl);
RuntimeWiring runtimeWiring = buildWiring();
SchemaGenerator schemaGenerator = new SchemaGenerator();
return schemaGenerator.makeExecutableSchema(typeRegistry, runtimeWiring);
}
private RuntimeWiring buildWiring() {
return RuntimeWiring.newRuntimeWiring()
.type(newTypeWiring("Query")
.dataFetcher("bookById", graphQLDataFetchers.getBookByIdDataFetcher()))
.type(newTypeWiring("Book")
.dataFetcher("author", graphQLDataFetchers.getAuthorDataFetcher()))
.build();
}
@Bean
public GraphQL graphQL() {
return graphQL;
}
}
定义Controller:
@RestController
@RequestMapping("/test")
public class DemoController {
@Autowired
private GraphQL graphQL;
@GetMapping
public Object find(@RequestParam("query") String query){
ExecutionResult result = graphQL.execute(query);
return result.getData();
}
}
打开postman,使用get请求,请求如下:
http://localhost:8080/test?query={
bookById(id:"book-1") {
id
}
}
返回结果如下:
{
"bookById": {
"id": "book-1"
}
}
这个时候,我需要多返回一个name,请求如下:
http://localhost:8080/test?query={
bookById(id:"book-1") {
id
name
}
}
返回结果如下:
{
"bookById": {
"id": "book-1",
"name": "Harry Potter and the Philosopher's Stone"
}
}
示例很简单,但graphql确实很好地解决了不同接口对查询字段差异性的要求,而不会产生数据冗余,更多功能还待研究。
当然你会说使用graphql会不会产生额外的工作量?当然会增加额外的工作量,前期你需要熟悉graphql的语法,后端需要大量的工作;但是这些额外的工作只是在前期,后期的好处就会体现出来了。
总结
本文介绍了传统的web开发架构的弊端,以及随着业务的增长,如何改造成前后端分离的架构,进而引申出restful 架构,随着restful 架构的缺陷,才有后来的代替者graphql。
·END·
时刻关注最前沿的技术
jiagoushizhidian
以上是关于为什么graphql可以替代restful?的主要内容,如果未能解决你的问题,请参考以下文章