开源加速Transformer推理的工具!腾讯的第100个开源项目
Posted 智东西
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源加速Transformer推理的工具!腾讯的第100个开源项目相关的知识,希望对你有一定的参考价值。

智东西4月25日消息,昨日,腾讯宣布开源推理加速工具TurboTransformers。
就像增压器(Turbo)能给汽车发动机引擎带来更强劲的功率,TurboTransformers能为众多自然语言处理(NLP)线上应用更充分地挖掘底层硬件的算力,带给Transformer推理引擎更强的性能表现。
该工具面向Transformer相关模型丰富的线上预测场景,在微信、腾讯云、QQ看点等产品的线上服务中已经广泛应用,这也是腾讯通过Github对外开源的第100个项目。

NLP线上推理极致的性能
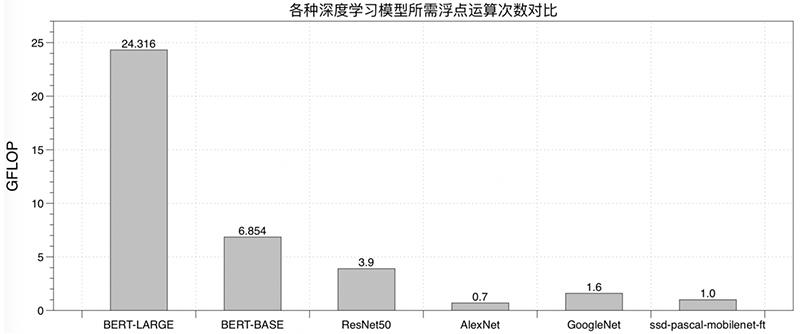
以BERT为代表的Transformer神经网络是近年来自然语言处理(NLP)领域最重要的模型创新,阅读理解、文章摘要、语义分类、同义改写等NLP任务,都通过采用BERT获得显著的效果提升。
但在提高模型精度的同时,Transformer相关模型也带来了更多的计算量。
由于深度学习的训练和推理任务存在差异,训练框架直接应用于线上推理并不能得到极致的性能。许多算法工程师都遇到了训练的模型效果很好,但因为响应延迟不满足要求,导致模型无法上线的问题。
一些工作尝试根据输入尺寸预先对计算图进行预处理和优化,以获得更好的推理时性能。但不同于输入常常没有变化的图像处理任务,NLP任务输入尺寸多个维度存在变化。实际推理时通过补零或截断成整理成固定的输入尺寸,这样引入了额外补零计算开销,预处理优化的方案对NLP任务并不适用。
随着BERT在互联网公司逐渐得到广泛应用,需要一个能充分发挥CPU/GPU硬件计算能力的Transformer推理方法。在这一背景下,腾讯微信开源了名为TurboTransformers的Transformer推理加速工具。
TurboTransformers的诞生源于腾讯内部对开源协同的推动。
2019年初,腾讯技术委员会成立,下设开源协同、自研上云两个项目组和对外开源管理办公室,以此来促进内部代码的开放共享和协同共建。
TurboTransformers来自于深度学习自然语言处理基础平台TencentNLP Oteam,作为基础性技术版块,率先进行了开源协同的实践,旨在搭建统一的深度学习NLP基础平台、提升研发效能。在内部对技术反复打磨的基础上,该项目进一步对外开源。

性能超过主流优化引擎
TurboTransformers能让Transformer推理引擎性能更强劲,具体而言,有高速、实用、简单三个特点。
1、CPU/GPU性能表现优异:面向Intel多核CPU和NVIDIA GPU硬件平台,通过核心融合和并行算法优化,充发挥硬件的各层级并行计算的能力,在多种CPU和GPU硬件上获得了超过PyTorch/TensorFlow和目前主流优化引擎(如onnxruntime-mkldnn/onnxruntime-gpu, torch JIT, NVIDIA faster transformers)的性能表现。
2、为NLP推理任务特点量身定制:可支持变长输入序列处理,无需序列补零、截断或者分桶带来的无用计算,也无需任何针对计算图在推理前的预处理过程。
3、使用方式简单:支持python和C++接口进行调用。支持TensorFlow和PyTorch预训练模型的载入,可作为huggingface/transformers的推理加速插件,通过加入几行python代码获得的BERT模型的端对端加速效果。
此前TurboTransformers已应用在腾讯内部多个线上BERT服务服务场景。其中微信常用问题回复服务获得1.88x加速,公有云情感分析服务获得2.11x加速,QQ看点推荐服务获得13.6x加速。
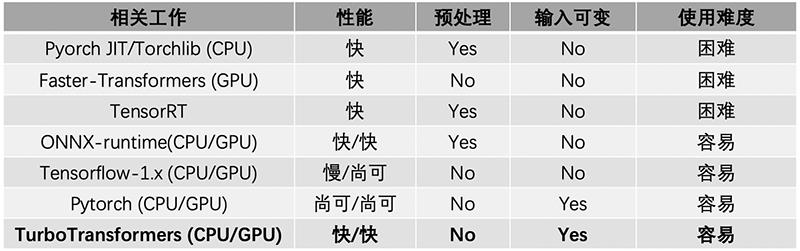
和其他相关工具对比,TurboTransformers在性能、使用方式上都具备优势。

技术创新的三个方向
为了让NLP相关算法更好地服务于用户,TurboTransformers在算子优化、框架优化和接口部署方式简化三个方面做了工作。
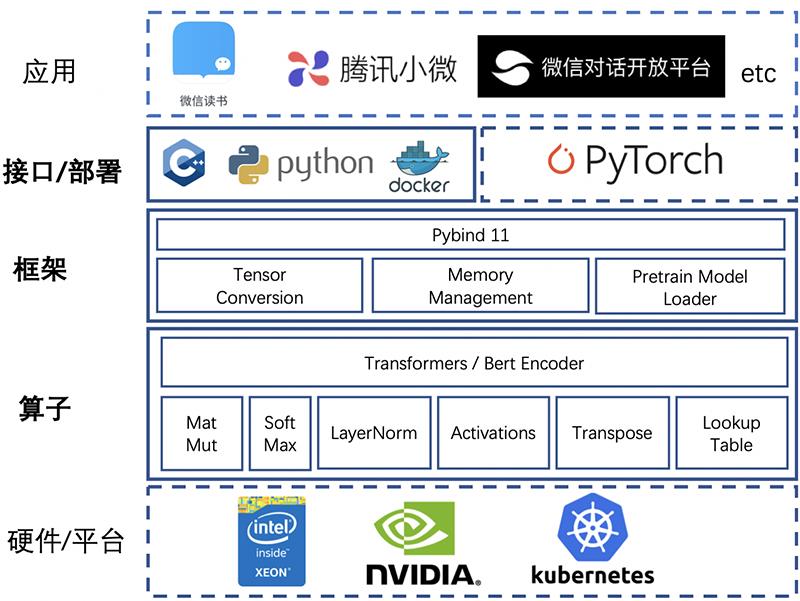 ▲TurboTransformers的软件架构
▲TurboTransformers的软件架构
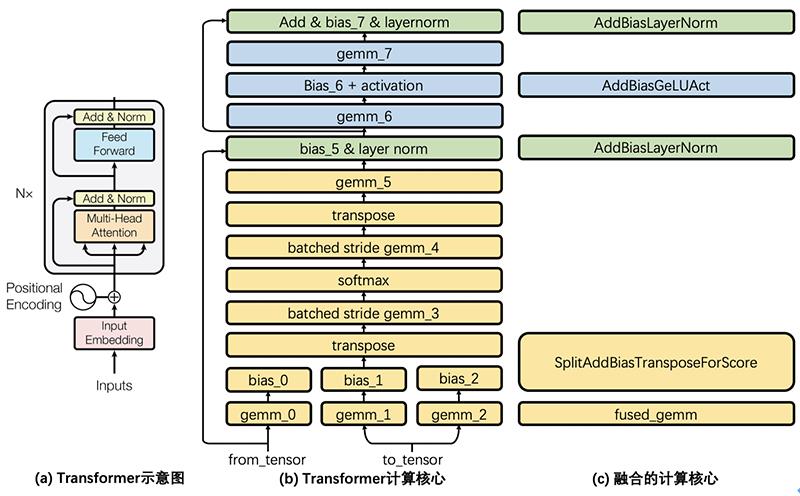
如下图所示,图(a)展示了论文Transformer结构示意图,这里称灰色方框内的结构为“一个Transformer Cell”,BERT encoder堆叠了Nx个这样的Cell。图(b)将一个Cell的细节加以展开,每一个矩形都是一个独立的计算核心。
Transformer Cell计算包含了8个通用矩阵乘法(GEMM)运算,通过调优Intel MKL和cuBLAS的GEMM调用方式来获得最佳GEMM性能。调整了预训练矩阵存储方式,并在硬件允许条件下,在GPU上使用tensor core方式进行GEMM运算。
类似NVIDIA FasterTransformers方案,将所有GEMM运算之间的计算融合成一个调用核心。融合有两个好处,一是减少了内存访问开销,二是减少多线程启动开销。
对于这些核心,在CPU上采用openmp进行并行,在GPU上使用CUDA进行优化实现。
对于比较复杂的LayerNorm和Softmax算子,它们包含了不适合GPU上并行的规约操作,TurboTransformers为它们设计了创新并行算法,极大降低了这些算子的延迟。理论上Transformers推理延迟应该近似于矩阵乘法延迟。
TurboTransformers采用了一个有效的内存管理方式。由于NLP的采用变长输入特性,每次运算中间结果的大小其实并不相同。为了避免每次都分配释放内存,该工具的开发团队通过Caching方式管理显存。
TurboTransformers提供了一些脚本,可以将PyTorch/TensorFlow的预训练模型转化为npz格式,供TurboTransformers读入,从而无缝支持PyTorch/TensorFlow训练好的序列化模型,还考虑到pytorch huggingface/transformers是目前最流行的transformers训练方法,支持直接读入huggingface/transformers预训练模型。
TurboTransformers提供了C++和Python调用接口。可以嵌入到C++多线程后台服务流程中,也可以加入到pytorch服务流程中。
开发团队建议TurboTransformers通过docker部署,一方面保证了编译的可移植性,另一方面也可以无缝应用于K8S等线上部署平台。
▲在NVIDIA V100 GPU上的性能测试结果
据悉,目前TurboTransformers的功能还相对有限,未来腾讯还会进一步对其优化,在开源后,TurboTransformers也期待与社区和开发者一起共建。
当前TurboTransformers只支持了FP32的计算,重点支持了BERT模型,解决了计算加速问题但还需用户自行搭建服务框架。未来该项目团队计划支持GPU FP16,并将增加该工具自动化优化的能力,还将开源服务流程,打通用户上线的最后一站。
结语:以开源撬动技术创新
“腾讯希望在科研领域投入更多力量,把科技向善纳入公司新的使命与愿景。我们将通过内外部开放源代码等方式,积极参与全球科技共同体的共建。”在2019年智博会上,腾讯公司董事会主席兼首席执行官马化腾表达了腾讯对开源的重视。
随着技术能力的持续累积,以及以开源为代表的腾讯新代码文化的兴起,腾讯在开源领域表现亮眼:在全球最大的代码托管平台 Github 上,腾讯已经累计开源了100个项目,覆盖云原生、大数据、AI、安全、硬件等多个热门的技术方向,并累计获得了超过29万Star数,跻身国际上有影响力的开源企业之一。
在2020年,腾讯陆续推出了针对云的场景研发的Linux 操作系统TencentOS Server、视频评估算法DVQA等多个开源项目,同时也积极用科技力量助力全球抗击疫情,3月27日,腾讯健康新冠疫情模块国际版(TH_COVID19_International)、“新冠肺炎AI自查助手” (COVID-19 self-triage assistant)也接连开源,向全球开放科技能力。
正如腾讯高级执行副总裁、云与智慧产业事业群总裁汤道生所言:“开源不再是开发者的个人热情,它已成为许多技术驱动型产业背后重要的创新推动力。”全面拥抱开源的腾讯,在打破内部技术壁垒的同时,也在推动IT行业更快地创新发展和走向未来。
以上是关于开源加速Transformer推理的工具!腾讯的第100个开源项目的主要内容,如果未能解决你的问题,请参考以下文章
本周AI领域优秀开源项目分享,Transformer推理工具医疗影像AI工具包等 6大开源项目
两行代码自动压缩ViT模型!模型体积减小3.9倍,推理加速7.1倍
两行代码自动压缩ViT模型!模型体积减小3.9倍,推理加速7.1倍
速度超快!字节跳动开源序列推理引擎LightSeq
自然语言处理大模型大语言模型BLOOM推理工具测试
推理加速 GPT-3 超越英伟达方案50%,开源方案打通大模型落地关键路径