大数据白皮书:Flume初级解析
Posted 长风云帆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据白皮书:Flume初级解析相关的知识,希望对你有一定的参考价值。
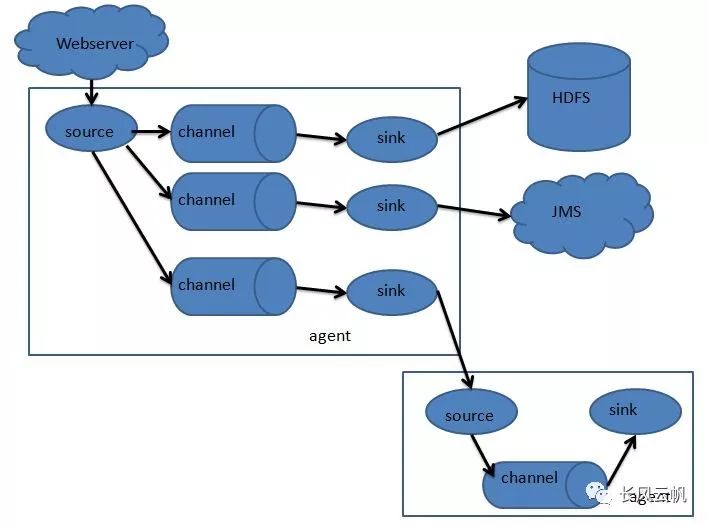
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
设计目标:
(1) 可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。
(2) 可扩展性
采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
(3) 可管理性
所有agent和colletor由master统一管理,这使得系统便于维护。多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理。
(4) 功能可扩展性
用户可以根据需要添加自己的agent,collector或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
长风云帆大数据培训,开阔眼界,高薪未来
以上是关于大数据白皮书:Flume初级解析的主要内容,如果未能解决你的问题,请参考以下文章