大数据组件--Flume
Posted 莫同学vv
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据组件--Flume相关的知识,希望对你有一定的参考价值。
https://baike.baidu.com/item/flume/6250098?fr=aladdin
Flume官方网址
http://flume.apache.org/
Flume简介
1) Flume 提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务, Flume 只能在 Unix 环境下运行。
2) Flume 基于流式架构,容错性强,也很灵活简单。
3) Flume、Kafka 用来实时进行数据收集,Spark、Storm 用来实时处理数据,impala 用来实 时查询。
Flume的几个角色
1、Source
用于采集数据,Source 是产生数据流的地方,同时 Source 会将产生的数据流传输到 Channel,这个有点类似于 Java IO 部分的 Channel。
2、Channel
用于桥接 Sources 和 Sinks,类似于一个队列。
3、Sink
从 Channel 收集数据,将数据写到目标源(可以是下一个 Source,也可以是 HDFS 或者 HBase)。
4、Event
传输单元,Flume 数据传输的基本单元,以事件的形式将数据从源头送至目的地。
Flume 传输过程
source 监控某个文件或数据流,数据源产生新的数据,拿到该数据后,将数据封装在一个 Event 中,并 put 到 channel 后 commit 提交,channel 队列先进先出,sink 去 channel 队列中 拉取数据,然后写入到 HDFS 中。
Flume 部署及使用的几个案例
文件配置 flume-env.sh
export JAVA_HOME=/home/admin/modules/jdk1.8.0_121
案例一:监控端口数据
目标:Flume 监控一端 Console,另一端 Console 发送消息,使被监控端实时显示。
1) 安装 telnet 工具

2) 创建 Flume Agent 配置文件 flume-telnet.conf
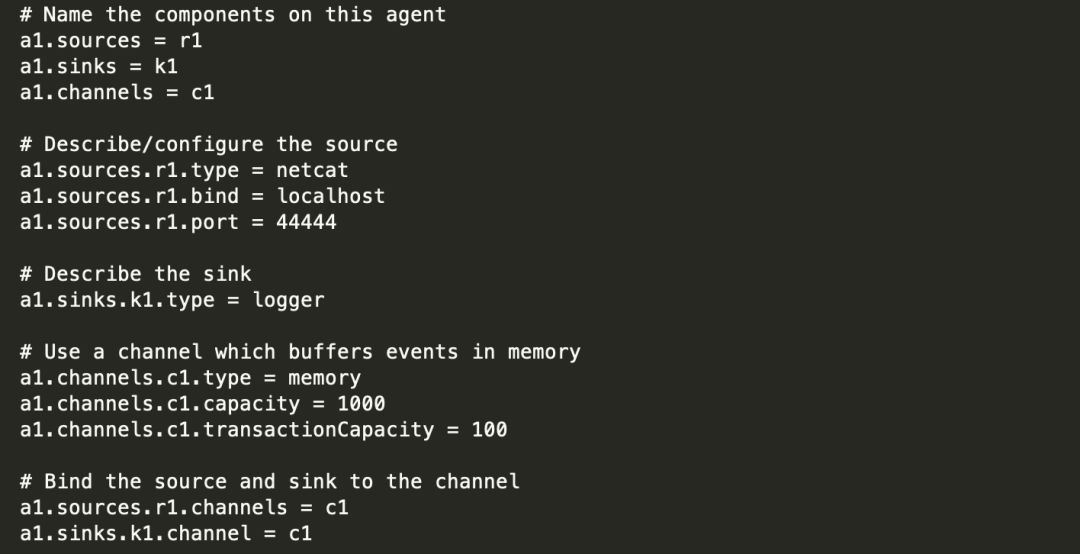
3) 判断 44444 端口是否被占用
$ netstat -tunlp | grep 44444
4) 先开启 flume 先听端口

5) 使用 telnet 工具向本机的 44444 端口发送内容
$ telnet localhost 44444
案例二:实时读取本地文件到 HDFS
目标:实时监控 hive 日志,并上传到 HDFS 中
1) 拷贝 Hadoop 相关 jar 到 Flume 的 lib 目录下(要学会根据自己的目录和版本查找 jar 包)

注意:后两个 jar 为 1.99 版本 flume 必须引用的 jar
2) 创建 flume-hdfs.conf 文件
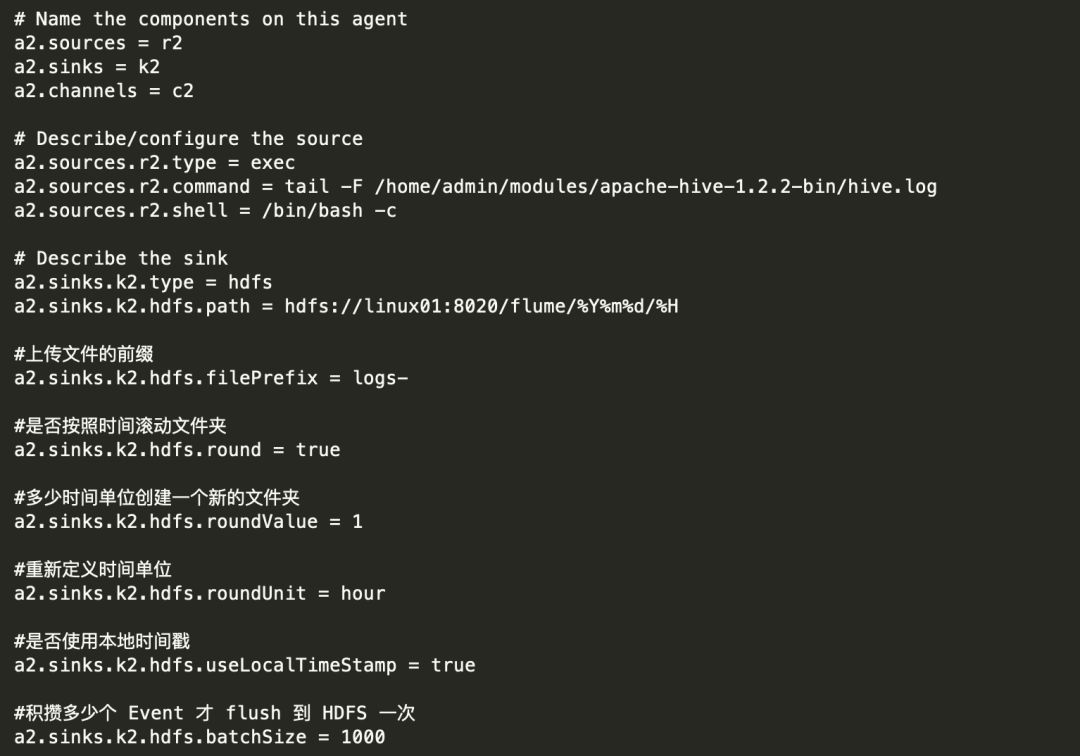
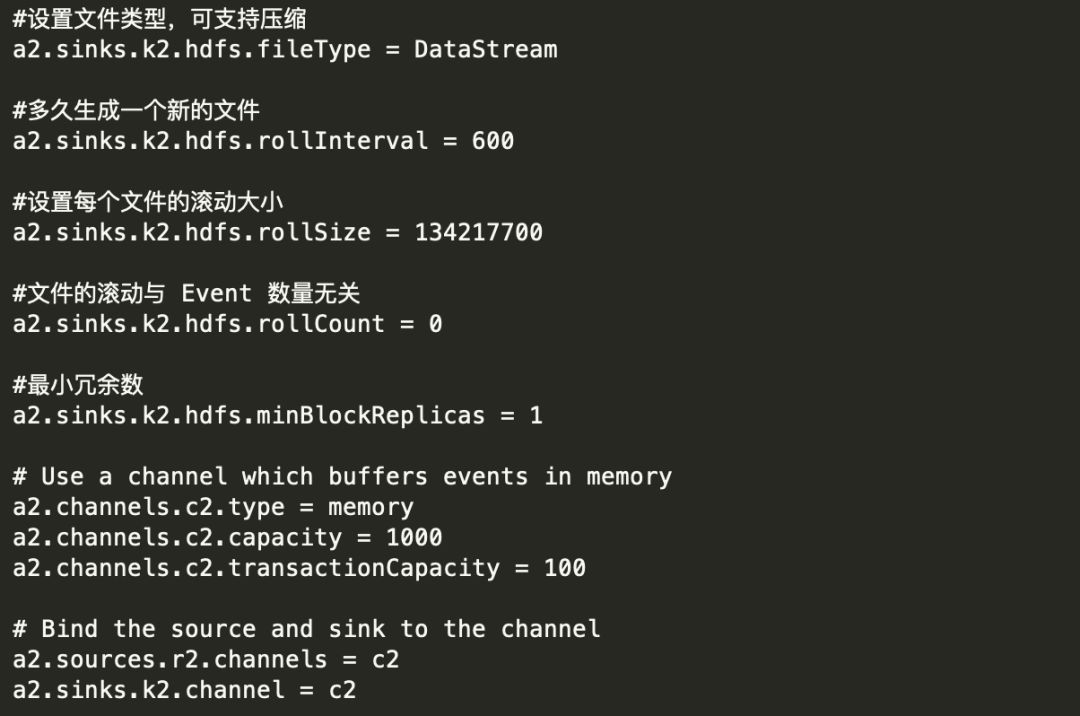
3) 执行监控配置
$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-hdfs.conf
案例三:实时读取目录文件到 HDFS
目标:使用 flume 监听整个目录的文件
1) 创建配置文件 flume-dir.conf
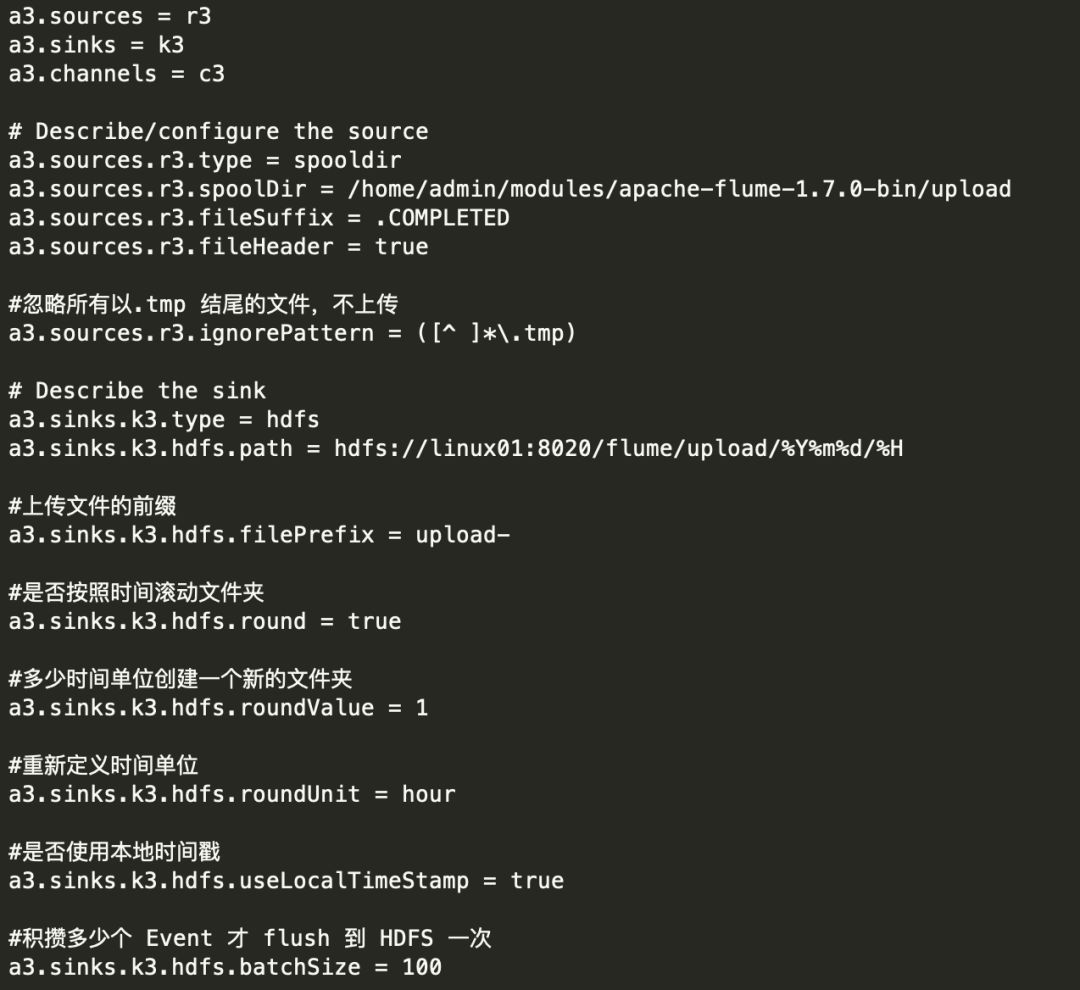
2) 执行测试:执行如下脚本后,请向 upload 文件夹中添加文件试试
$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir.conf
注意 : 在使用 Spooling Directory Source 时
1) 不要在监控目录中创建并持续修改文件
2) 上传完成的文件会以.COMPLETED 结尾
3) 被监控文件夹每 600 毫秒扫描一次文件变动
案例四:Flume 与 Flume 之间数据传递:单 Flume 多 Channel、 Sink
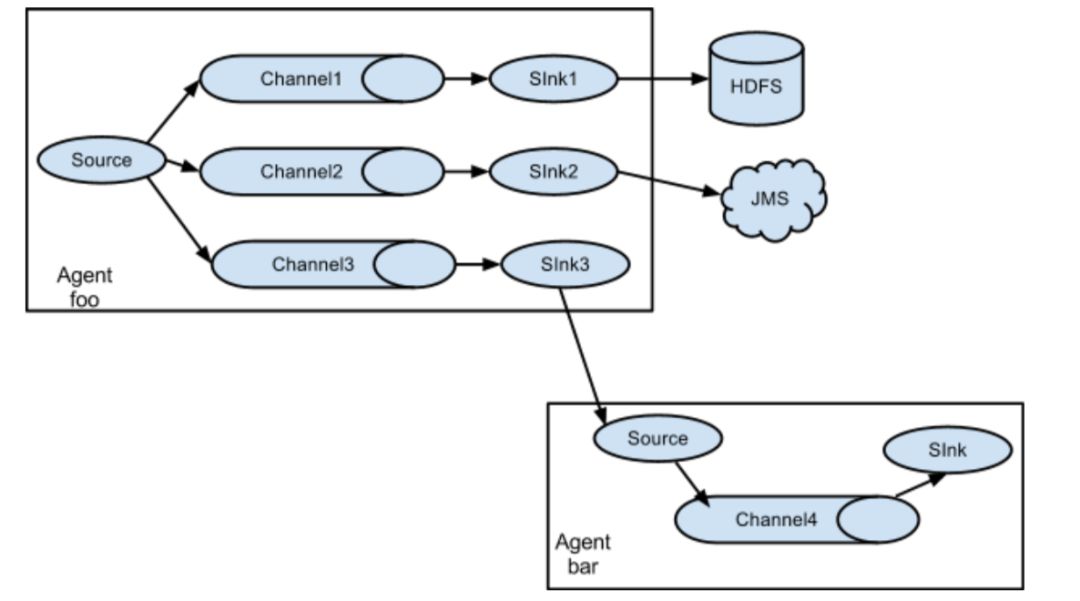
目标:使用 flume-1 监控文件变动,flume-1 将变动内容传递给 flume-2,flume-2 负责存储到HDFS。同时 flume-1 将变动内容传递给 flume-3,flume-3 负责输出到 local filesystem。
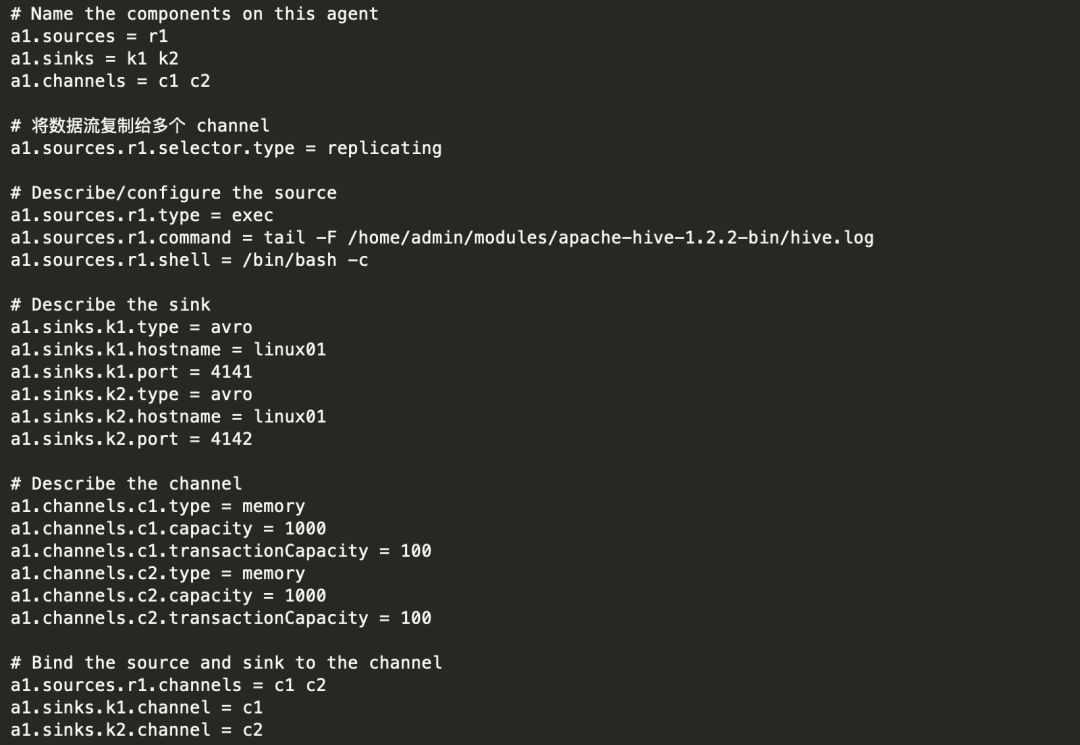
1) 创建 flume-1.conf,用于监控 hive.log 文件的变动,同时产生两个 channel 和两个 sink 分 别输送给 flume-2 和 flume3:
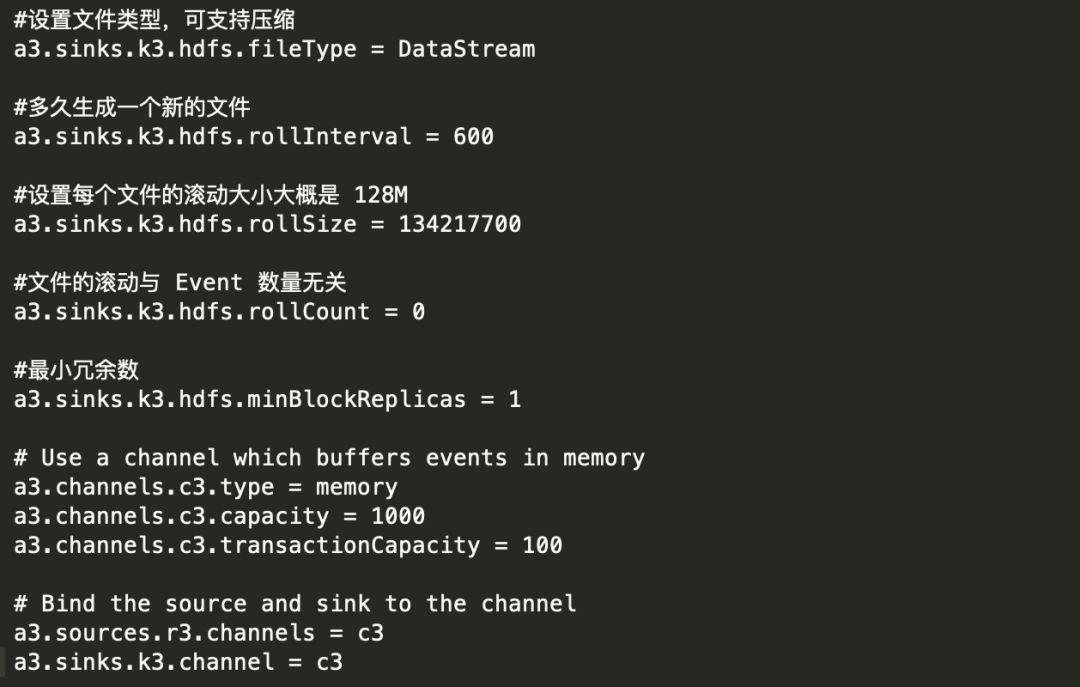
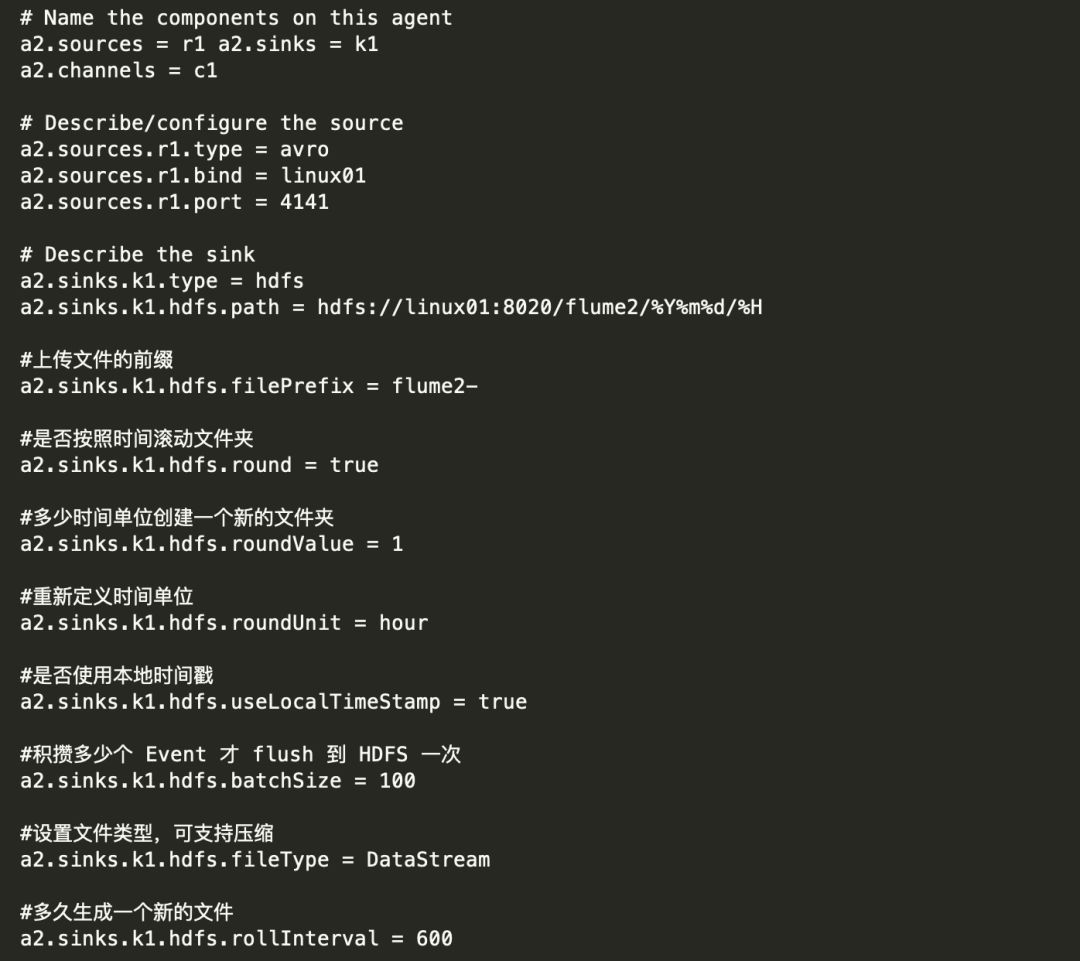
2) 创建 flume-2.conf,用于接收 flume-1 的 event,同时产生 1 个 channel 和 1 个 sink,将数 据输送给 hdfs:
3) 创建 flume-3.conf,用于接收 flume-1 的 event,同时产生 1 个 channel 和 1 个 sink,将数 据输送给本地目录:
注意:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录。
4) 执行测试:分别开启对应 flume-job(依次启动 flume-3,flume-2,flume-1),同时产生 文件变动并观察结果:
以上内容参看自
<<Flume日志收集与MapReduce模式>>
<<企业大数据处理:Spark、Druid、Flume与Kafka应用实践>>
配置文件可直接在Flume官网查找
后面还会介绍另一个日志收集工具Logstash
以上是关于大数据组件--Flume的主要内容,如果未能解决你的问题,请参考以下文章