深度学习框架大PK褚晓文教授:五大深度学习框架三类神经网络全面测评(23PPT)
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习框架大PK褚晓文教授:五大深度学习框架三类神经网络全面测评(23PPT)相关的知识,希望对你有一定的参考价值。
1新智元报道
编辑:胡祥杰
【新智元导读】 香港浸会大学褚晓文教授团队在2016年推出深度学习工具评测的研究报告《基准评测 TensorFlow、Caffe、CNTK、MXNet、Torch 在三类流行深度神经网络上的表现》,并在2017年年初发布更新,引起广泛关注。在本次专访中,褚晓文教授介绍了各个工具的优势和劣势,并谈到了TPU崛起对GPU的影响。本文后半部分是褚晓文教授在AICC大会上的演讲实录和PPT。

香港浸会大学褚晓文教授团队在2016年推出深度学习工具评测的研究报告,并在2017年年初发布更新,引起广泛关注。见新智元报道《 基准评测 TensorFlow、Caffe、CNTK、MXNet、Torch 在三类流行深度神经网络上的表现(论文)》,2017年初版本的评测的主要发现可概括如下:
总体上,多核CPU的性能并无很好的可扩展性。在很多实验结果中,使用16核CPU的性能仅比使用4核或8核稍好。TensorFlow在CPU环境有相对较好的可扩展性。
仅用一块GPU卡的话,FCN上Caffe、CNTK和Torch比MXNet和TensorFlow表现更好;CNN上MXNet表现出色,尤其是在大型网络时;而Caffe和CNTK在小型CNN上同样表现不俗;对于带LSTM的RNN,CNTK速度最快,比其他工具好上5到10倍。
通过将训练数据并行化,这些支持多GPU卡的深度学习工具,都有可观的吞吐量提升,同时收敛速度也提高了。多GPU卡环境下,CNTK平台在FCN和AlexNet上的可扩展性更好,而MXNet和Torch在CNN上相当出色。
比起多核CPU,GPU平台效率更高。所有的工具都能通过使用GPU达到显著的加速。
在三个GPU平台中(GTX980,GTX1080,Tesla K80中的一颗GK210),GTX1080由于其计算能力最高,在大多数实验结果中性能最出色。
某种程度上而言,性能也受配置文件的影响。例如,CNTK允许用户调整系统配置文件,在运算效率和GPU内存间取舍,而MXNet则能让用户对cuDNN库的自动设置进行调整。
2017年9月7日,中国工程院信息与电子工程学部主办、浪潮集团承办的首届人工智能计算大会(AI Computing Conference,简称AICC)上,褚晓文教授发表题为《Benchmarking State-of-the-Art Deep Learning Software Tools》的报告并接受了 新智元的独家专访。他在采访中提到了这一项目的起源以及其中涉及的技术点,特别是深度学习网络的计算原理等。
褚晓文教授介绍说,其团队从2008年开始就开始从事GPU计算方面的科研工作,在2014到2015年的时候,开始接触到深度学习这个领域,那个时候为了开发一个并行的深度学习平台,对整个深度学习的原理和应用都有了一个比较深入的了解,这是一个前期的基础。
到了2016年的时候,他们就留意到,突然就很多深度学习平台开始开源了。工具多了以后,他们通过与工业界的接触了解到,大家经常会有一个困惑:工具很多,硬件也很多,各种各样的GPU卡,从4、5千块钱到4、5万都有。该如何进行选择?这个问题很复杂,也很难回答。所以他就开始跟学生一起,做了一些初步的比较的工作。
值得一提的是,这是一开源的项目,所有人都可以下载到代码和测试的数据,文档也写的很清楚,大家都可以重复实验。所以从发布至今,褚晓文教授他们也收到了大量的反馈,并对测评结果进行了优化迭代。今年最新版本的测评报告会在近期公布,新智元也将对此保持关注。
TensorFlow vs CNTK vs MXNet,谁的性能最好?
在专访中,我们邀请褚晓文教授对其科研小组所作测评的几个框架进行了介绍,他分析了TensorFlow、CNTK 和MXNet。
1. TensorFlow
他说,TensorFlow是目前关注量最多的,可能有80%的用户会选择用TensorFlow这个平台。TensorFlow 最大的优势在于它的社区很成熟,因为用的人多,大家讨论的也多,遇到困难,能找到帮你解决困难的可能性也会更高一点。但是TensorFlow自身是一个很大的框架,它的设计初衷在使用硬件资源上面是一个自动化的过程(注:目前开源的TensorFlow版本还是需要用户来合理的分配硬件资源)。
褚晓文教授说,由此,TensorFlow可能会有一个问题:性能可能未必是它最关注的一点。他也认为,谷歌在底层硬件上有着更深的布局,他们在硬件上的投入,可能是目前是其他的工具给不了的。“ 其他的工具更依赖于GPU。我觉得谷歌并不把它的重点放在GPU这一块,反而是说,直接用我的TPU好了。当然第一代TPU不是主要来做训练,而是使用8-bit整数乘法运算做一些推理,而第二代TPU已经开始支持浮点运算进行训练了,将来如果大量开放的话对GPU就会带来更大的挑战”,褚晓文教授说。
目前TensorFlow在市场上已经占到到百分之七十到八十。那么,未来会不会出现垄断,或者一个大一统的深度学习框架。褚晓文教授认为,慢慢的会收拢到两三个,但是不会仅有一个。也就是说,不会出现一个大一统的工具,但是可能会有两三个大的工具存在。
2. CNTK
CNTK是褚晓文教授个人比较喜欢的。他介绍说,微软对CNTK也是非常重视的一个项目,也投入了很多的专家,而且更新也非常快。“在我们多版的测试里面,CNTK很多情况下都是性能最好的之一,不管是单卡还是多卡的情况,所以说,微软我觉得他可能是非常看中性能这一块”,褚晓文教授说。
因为TensorFlow拥有如此大的体量了,所以CNTK要追赶,注重的就是性能方面。当然CNTK有它的复杂性在里面,因为要取得好的性能,一定是要经过多次的调试,或者说当在写脚本的时候,要很熟悉这个框架,很熟悉这个硬件,很熟悉这个内存分配等等,才可以达到这个性能的极致。
他说:“所以你要取得好的性能,一定可能是在开发周期上面需要多花一些功夫在上面。但是无论如何,从我们的评测结果来讲,CNTK,的确是性能最好的,而且他跟英伟达的配合是很紧的,英伟达一旦放出来新的库,或者新的硬件,微软马上就会跟进,去更新他们的CNTK。”
3. MXNet
褚晓文说,MXNet的性能其实也相当好的,跟CNTK差距不大。它在可扩展性方面也是非常出色的。因为出来的比较晚,它可能的重点就是怎么做扩展性,比如说它一放出来,就已经直接可以在多卡和多机多卡的集群下面很方便的使用,这个是MXNet的一个优势。
褚晓文特别强调了测评对“性能”的重视,基本上这是一个以性能为主要标准的评测。但是,在这个过程中,他们也发现一些问题,比如,CuDNN本身对硬件的依赖性,不同版本的 CuDNN 跟不同类型的GPU卡是有一个匹配问题的。
针对今年备受关注的AI专用芯片,比如TPU对深度学习工具的支持。褚晓文教授说,在训练上来讲,GPU还是主流,因为任何一个硬件的出现是离不开软件的配套的,如果没有软件配套,硬件只能是为已知的一些网络做优化,如果有新的网络出现,那这个硬件是否还能够适应新的软件结构的,新的网络结构,这个是未知的。
这些AI芯片可能得是基于一些比较成熟的神经网络,针对那些已知的网络做一些优化。但是如果将来万一有一个颠覆性的网络结构,或者颠覆性的一种计算模式出现,那你的硬件也要重新来过。这个可能是AI芯片厂商要考虑的一个问题。
褚晓文教授说:“硬件是永远离不开软件支撑的,GPU的成功,就是从08年到现在,这么多年培养了大量的软件人才,他们在这方面的投入是相当大的,这也是为什么AMD迟迟追赶不上的原因,AMD缺乏一个软件的生态。”
但是,从目前的条件来看,专用AI芯片对深度学习工具性能上的提升是肯定的。因为数据量还是在指数级增长。
褚晓文教授认为,目前来看,比如说最简单的训练,还是需要花掉大量的时间,而且单GPU的瓶颈,还是在于它的增长速度跟不上数据的增长,所以一定还是要更专用的种芯片。
采访的最后,新智元问,如果要从这些工具中选择一个进行推荐,会推荐哪个?褚晓文教授表示:“我一般不会推荐,因为我们是一个比较中立的一个角度去看,我认为任何一个框架都有它的价值,都有可以借鉴的地方,从实际的角度,对于工程师来讲其实你选择要结合你的业务需求。”
但是,如果对于这种本身没有太多经验的人的话,他还是推荐TensorFlow。因为,它的文档,相对来说都会比较顺利一些,而且它开发起来相对容易一些。


各位嘉宾,先生们,女士们中午好,非常感谢浪潮邀请我来参加这个大会,今天我想跟大家分享一下我们在深度学习各种工具性能测试方面的工作。今天在短短的二十分钟,我想花一半时间跟大家回顾过去十年里我们CPU和GPU的发展,接下来给大家介绍现在主流的深度学习软件工具,也就是浸会大学在深度学习软件工具的测试工作,及为什么做这个工作。最后跟大家简单汇报我们最新的测试结果。

深度学习在近年来已经深入到我们的生活和工作之中。深度学习这个生态圈大概分成三层:最上面是层出不穷的各种应用,包括著名的AlphaGo、谷歌Translate软件、讯飞的语音输入等等,这都是大家生活中会用到的软件,将来还会有无人驾驶、AI医疗、AI金融。
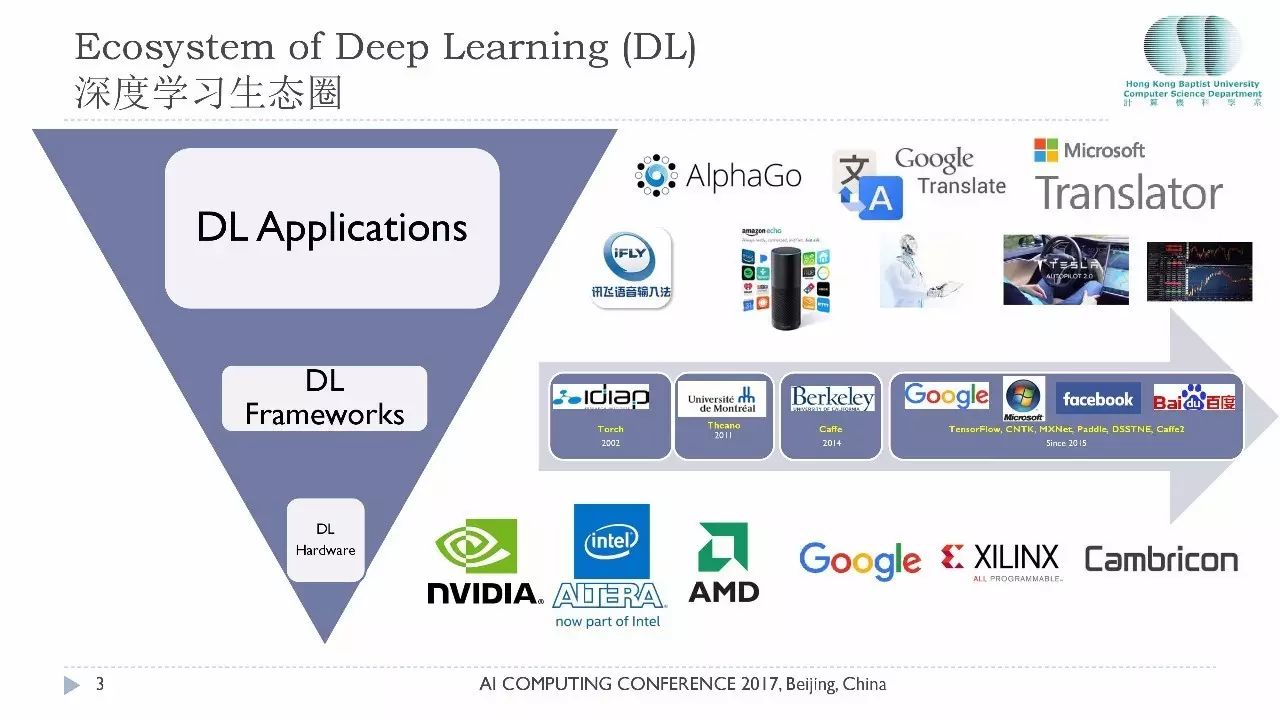
但是,工欲善其事必先利其器,深度学习的生态圈里核心一层就是生产工具。大家可以看到从2011年开始有各种各样的深度学习的平台开源,尤其从2015年开始基本上是百花齐放的状态。在最底层是原材料,各种各样的硬件,包括英伟达的GPU,英特尔收购了一些FPGA的公司,还有谷歌的TPU。
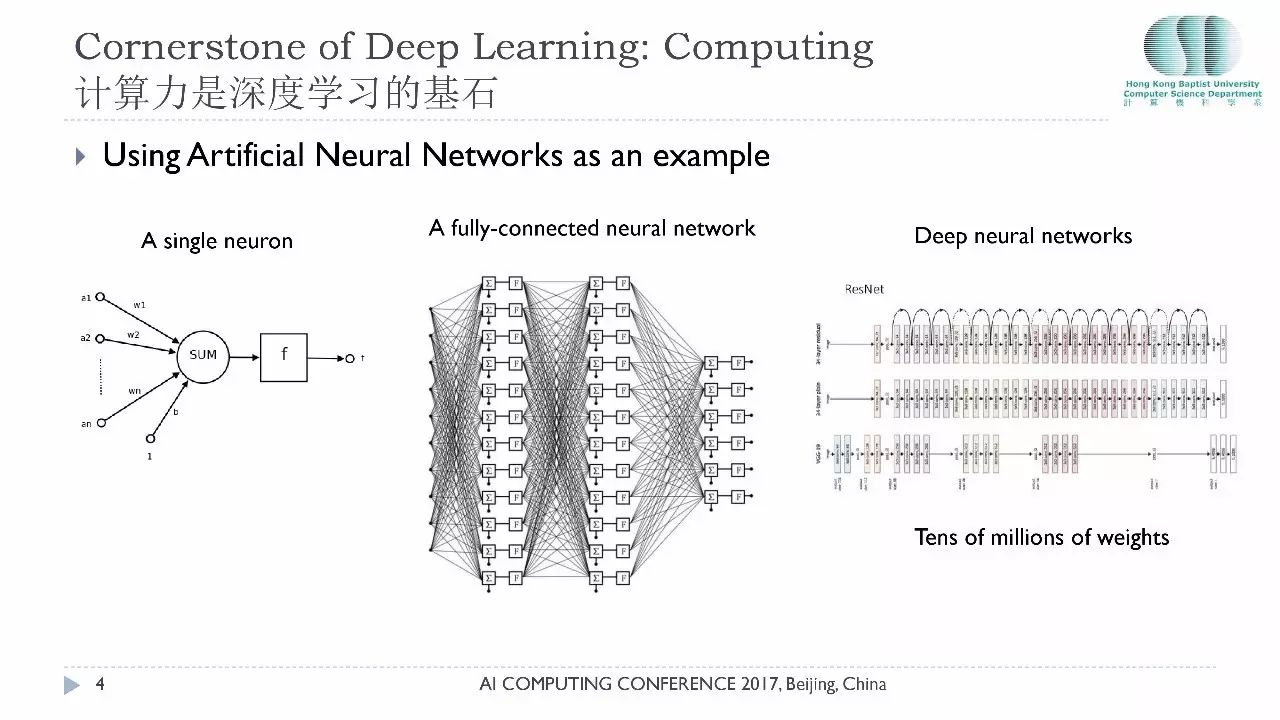
今天大会主题是计算,深度学习之所以达到今天的成功完全离不开计算,刚才孙剑先生已经跟大家分享了很多深度学习里面的计算。一个神经元它要做的事情就是很简单的两个矢量的点积运算,它的运算量取决于权重有多少,仅仅是一个神经元就要做很多计算。这是一个全连接的神经网络,可以想象,神经元很多的时候计算量有多庞大。
比如,人的大脑有几百亿的神经元在运作,为了解决这个计算问题,近期流行的各种深度的神经网络,比如卷积网络它就降低了权重的数量,但是目前的主流神经网络还是有数以百万计的权重,做一次前向运算要做几十亿次的乘加运算。所以说,计算力是深度学习的基石。
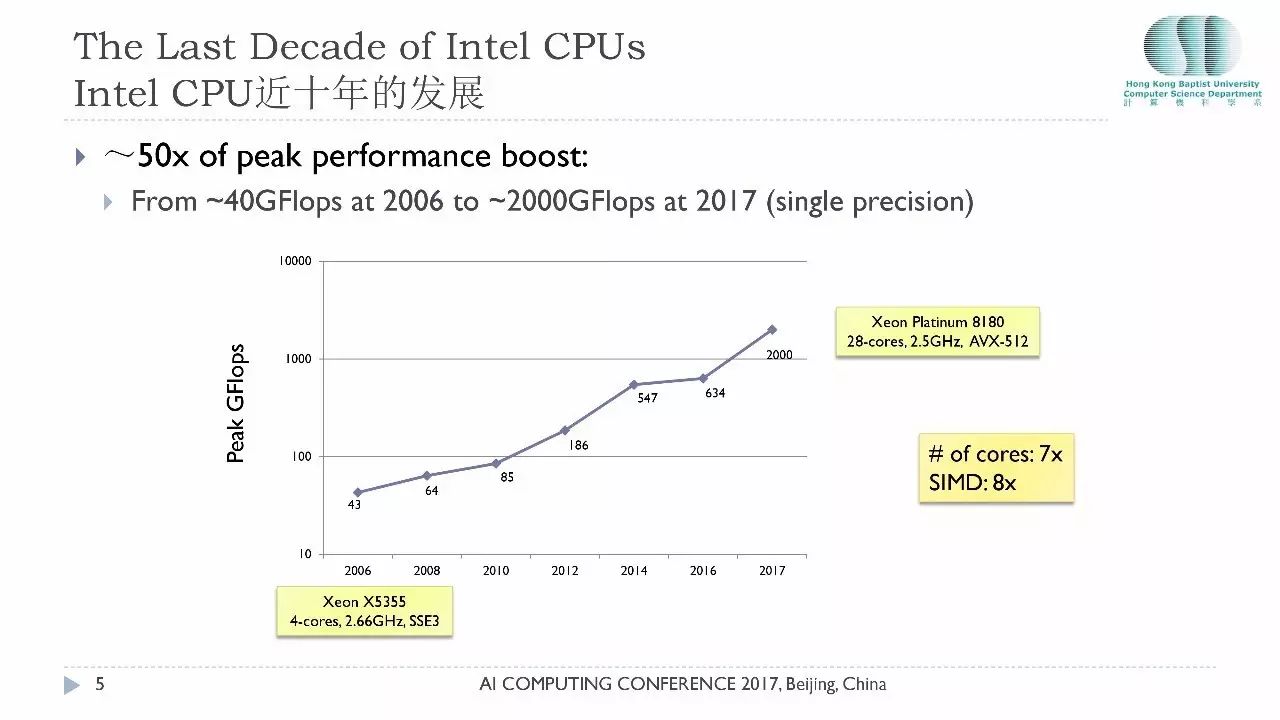
既然计算如此重要,我们需要回顾近十年来CPU的发展到底是怎么样的,2006年当时最强大的英特尔的CPU至强X5355是一款四核CPU,它的计算能力峰值当时是43个GFlops,也我们现在提的是单精度运算,今年 Intel 发布的最新白金CPU8180已经发展到28核,计算峰值能达到2个TFlops。
过去11年CPU处理能力提高了50倍,大家可能想知道这50倍是怎么来的,非常简单,第一它的核心数量从4变到28,有了7倍的增长。另外一个性能的提升来源于指令的宽度,2006年一条指令只能处理 2 个单精度的浮点运算,今天512位的指令集,一条指令可以同时处理16个单精度的浮点运算,这就相当于8倍的性能提升。50倍的提升就是这么来的,这给软件从业者带来了相当大的挑战,如果你不懂得如何利用多核以及如何利用SIMD指令,那么你的性能就还停留在十年前的水平。
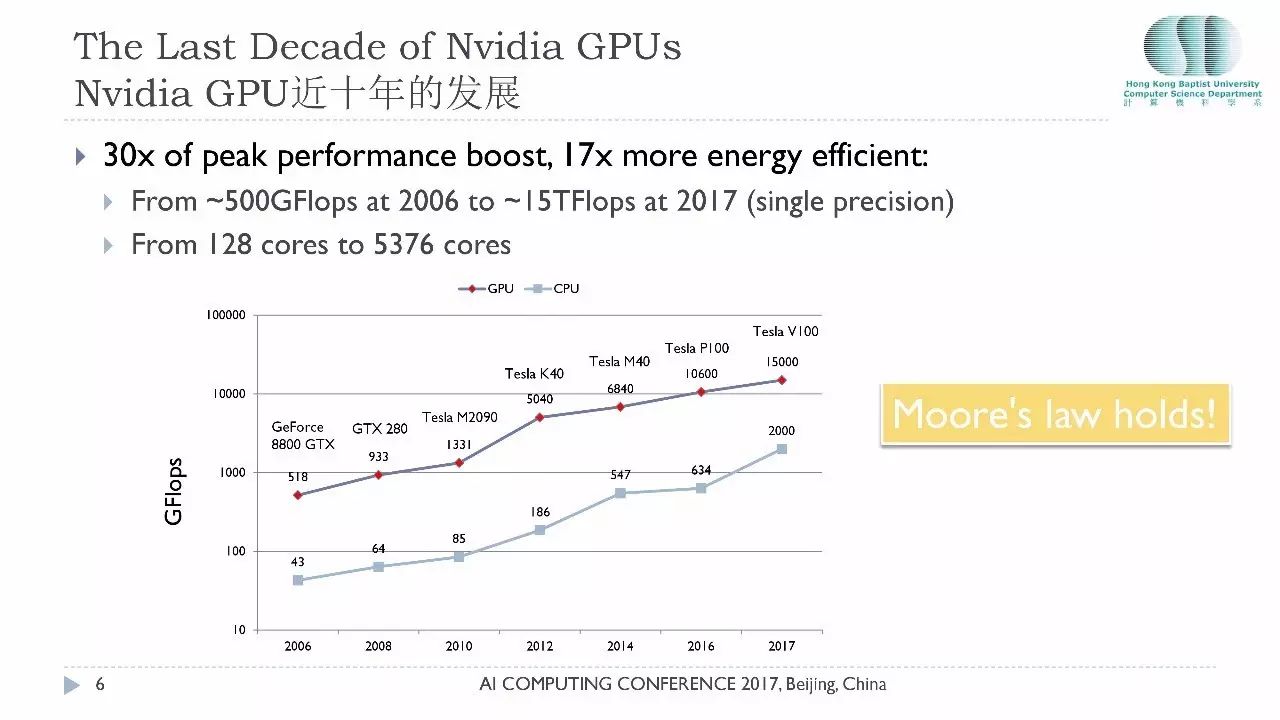
再看GPU在近十年的发展。红色这条线是GPU性能,下面那条线还是CPU的性能,这里讨论的是英伟达的GPU。2006年英伟达第一次发布通用计算的GPU 8800GTX,当时它的性能已经达到了500个GFlops,接下来十年,大家可以看到GPU相对CPU的计算能力一直维持在10-15倍的比例,今年英伟达提出的V100性能已经达到15个TFlops的单精度的性能。大家有没有发现这两条曲线非常吻合,有没有想过为什么?
今天前面很多嘉宾已经提到摩尔定律,根本原因就是摩尔定律在掌控一切,摩尔定律说的就是你的芯片里面的晶体管数量它的增长每隔两年大概翻一倍,这个取决于芯片的工艺。所以每次工艺的进步都会带来CPU和GPU的性能的提升。
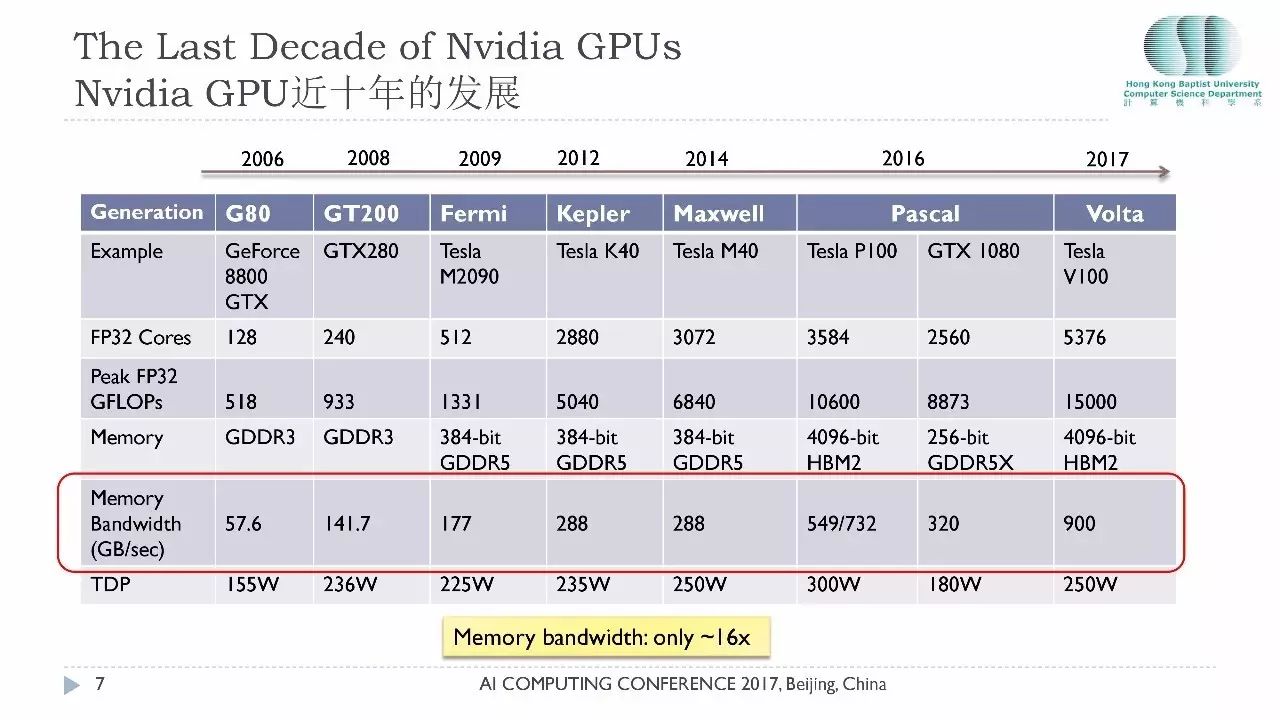
这张表给大家展示了英伟达最近的七代GPU的产品,把它放在一起,从2006年它的GPU核只有128个,今天Volta已经有超过5300个核芯,这是个相当了不起的突破。
大家要留意它的内存的带宽,刚才孙剑给大家共享了冯诺伊曼的瓶颈问题就是内存的问题,内存技术也是在发展的,但是它的发展速度远远低于计算核心的发展。过去11年里面内存的带宽从57个GFlops提升到900个GFlops,还得多谢3D内存技术的突破,如果不考虑3D内存而仅仅考虑GDDR内存的话,它的性能提升仅仅只有8倍。所以说在过去的11年里面内存带宽仅仅提升了15-16倍,而计算能力提升了30-50倍,这说明内存的性能跟计算的性能之间的距离在逐渐扩大。这也是GPU计算今天面临的一个巨大的挑战,这个挑战就是巨大的计算能力和相对薄弱的内存访问之间的一道鸿沟。

大家想象一下,现在的这些GPU或者CPU它每一个时钟周期可以做1到2个浮点运算,这是它的能力,但是每做一次运算数据从哪里来,数据往哪里去,每一次运算都需要至少2个数据读取的操作,把结果写回到某个地方去,这都涉及到数据的传输。所以内存的的确确是今天面临的一个巨大的问题。
我们还没有讲访问内存需要多长时间。通常来讲当你要做计算的时候那个数据从全局内存读到处理器里面需要几百个时钟周期,是非常缓慢的过程。内存的带宽,拿GTX1080来举例,它的计算能力已经达到了8个TFlops,内存带宽仅仅有300个GB/s。
假设你的一个GPU线程要做一次运算,首先要从全局内存读取数据,经过400个时钟周期的时间才能拿到数据,花20个时钟周期处理数据得到结果,再把结果再花400周期写到内存里面去,所以单从一个线程的角度来看我们的GPU大部分时间是在等待的。
为了解决这个问题,当然有很多的解决方案,GPU用了非常复杂的内存架构,是一个金字塔型的架构,最顶层是非常快的寄存器,它下面还有L1级的Cache,还有L2级的Cache,还有Shared Memory。CPU的Cache对程序员是不透明的,程序员不能控制那些Cache,GPU计算领域这些Cache 和 Shared Memory是可以被程序员控制的,GPU架构里软件设计空间非常庞大,设计一个好的GPU程序是一门艺术。
我想带给大家的信息是:硬件和软件同样重要,仅仅有硬件是不够的,没有好的软件硬件的效能是发挥不出来的,这也是为什么今天有这么多深度学习软件它们的性能有如此大的差异。
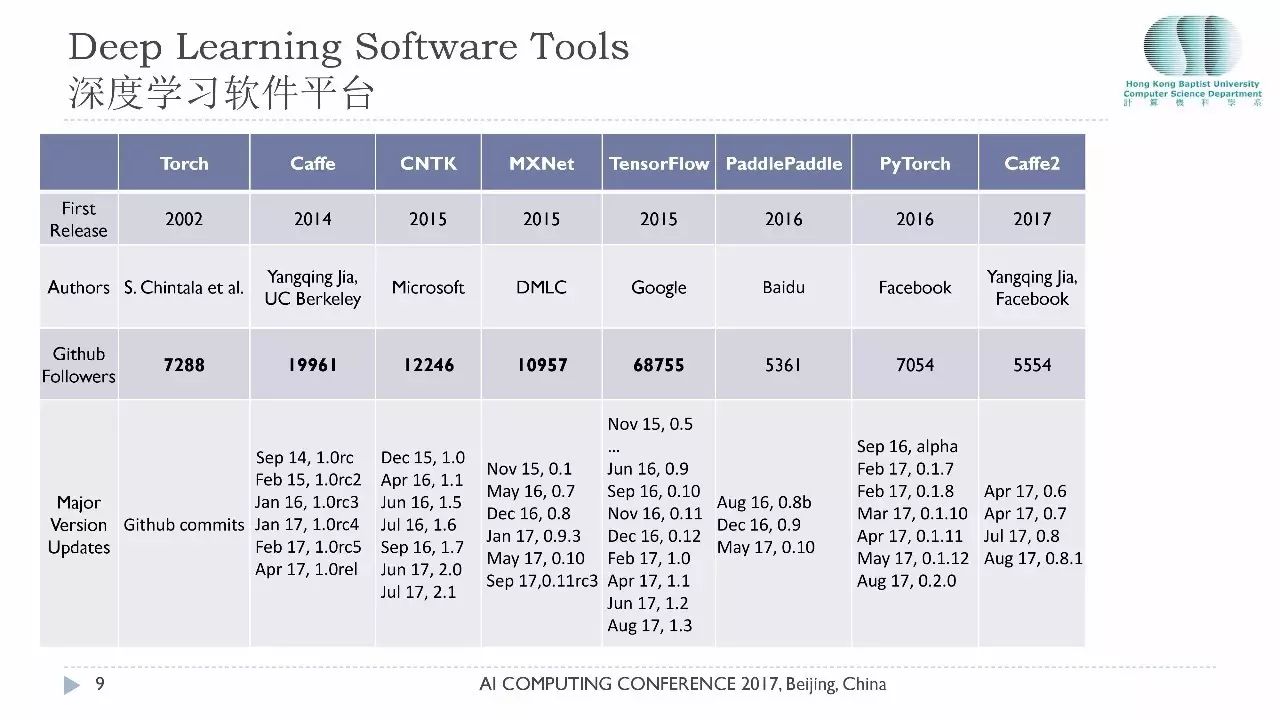
接下来看深度学习软件在近年来的发展。Torch是很流行的软件,2002年就有了,那时候还没有深度学习。后来把深度学习做进去了。2014年就是Caffe,微软2015年开源了CNTK,接下来谷歌也开源了他们相应的开发平台。第三行是它的粉丝数量,目前Tensorflow的粉丝团是最庞大的,有6万多个关注,相对来讲,CNTK、Caffe加起来还没有Tensorflow有影响力。最底下是开发平台的维护情况,随着硬件的提升,新的算法的提出,每个软件都是要不断的更新换代的,Tensorflow的更新是非常频繁的,基本上每一两个月就会有一个新的更新,代表着他们对软件平台的投入。
我特别想感谢所有默默无闻的工作在软件平台后面的程序员,没有他们就没有今天的深度学习。让我非常自豪的是这里的开发者有50%以上是中国人。

选择太多其实是很痛苦的,尤其是对刚刚进入这个领域的创业者来讲,这么多的GPU,5千块钱的5万块钱的差别在哪里?这么多的软件平台该选哪一个?其实要选择一个好的软件框架有很多因素,包括它的性能、它的成本、它的稳定性、它的社区的支持等等,我们今天主要是关注它的性能这一个层面。

其实我们是从2008年就开始研究GPU计算,在2014-2015年我们参与了深度学习软件的平台开发的项目,接下来我们就认识到深度学习将会彻底改变我们的社会。2015、2016年就开始出现了很多声音:这么多的软件、这么多的硬件该怎么处理?所以我们在2016年5月就启动了关于深度学习平台的基准测试项目。我们这个项目有两个目的,第一是要去以科学的态度测试这些不同的深度学习平台在不同的硬件平台上的运行性能 ,发现一些潜在的问题,把其作为一些科学的研究课题来改善提高。
那时候也有一些类似的基准测试项目,但我们有三个非常显著的特点:1. 我们要保证我们的试验结果是可靠的,一定要可重复实现的。所以我们是一个开源的项目,我们所有的源代码所有的数据全部是公开在网上供大家重复;2. 我们要保证我们的测试是公平的,尽可能的公平,其实这是一个非常有挑战性的工作,因为不同的软件工具它的设计、它对数据的处理都不一样;3. 我们希望这是一个很长期的工作,有的项目做了一次测试就完了,没有再去跟进,而我们希望这是一个非常长期的工作,当有新的软件出来新的硬件出来,我们都会把他们加入到我们的基准测试里面供大家参考。

过去的一年里我们在四个不同的维度做了一些工作,我们测试的软件工具包括Caffe、CNTK、Tensorflow、MXNet以及Torch,我们暂时聚焦这在五款测试工具。
在测试硬件方面,我们早期做了一些CPU的测试,把它们的性能跟GPU做比较,后来发现差距实在太大,所以近期我们已经放弃了在CPU上做测试,已经没有太大的实际意义GPU我们测试了多款市面上比较流行的GPU,从低端的到高端的。测试的网络包括全连接的网络,包括主流的深度卷积网络以及RNN网络。测试的数据集我们用的公开的数据集,当然我们自己合成的假的数据,真的数据里面我们有MINST,CIFAR10,近期也包括了ImageNet。

深度神经网络的计算里最关键的是两种运算:如果你是一个全连接层,它的计算主要是矩阵乘法,如果你是卷积层,它的核心计算是卷积运算。在主流的深度卷积网络里大家可以看到超过80%的运算是来源于卷积运算,一般的深度网络最后一两层才用到全连接层,所以这个卷积操作其实是现在深度学习里面最关键的核心技术。刚才孙剑博士也分享了如何做卷积的心得体会。大家有兴趣的话可以读一下最近三四年中发表 的非常经典的学术论文,这就是学术界和工业界的互动,现在学术界也慢慢流行开源,他们有好的想法好的算法不仅发表论文而且公开源代码,很快英伟达就会把他们的成果集成到他们的library里面。
简单讲一下卷积运算为什么那么复杂,因为卷积是一个数学概念,它的实现千变万化,有一本书专门讲如何实现卷积运算,目前最主流的有三种算法:第一是通过矩阵运算,这是Caffe最早使用的。第二是Facebook一直推动的基于快速傅立叶变化的运算,第三是基于Winograd的实现,这个方法已经存在几十年了,只是近期发现它在特殊情况下能够取得非常好的性能。

我们在Tesla P100对最新的cuDNN5.1版本做了测试,比较这三种算法,为什么选这三种算法,因为cuDNN实现了这三种算法供大家选择。大家可以看到在不同的网络配置下大家的性能还是有很大差距的,目前在小的卷积核上Winograd远远超过矩阵运算和快速浮列变化的运算性能,如果你想网络训练得比较快一定要了解卷积操作。
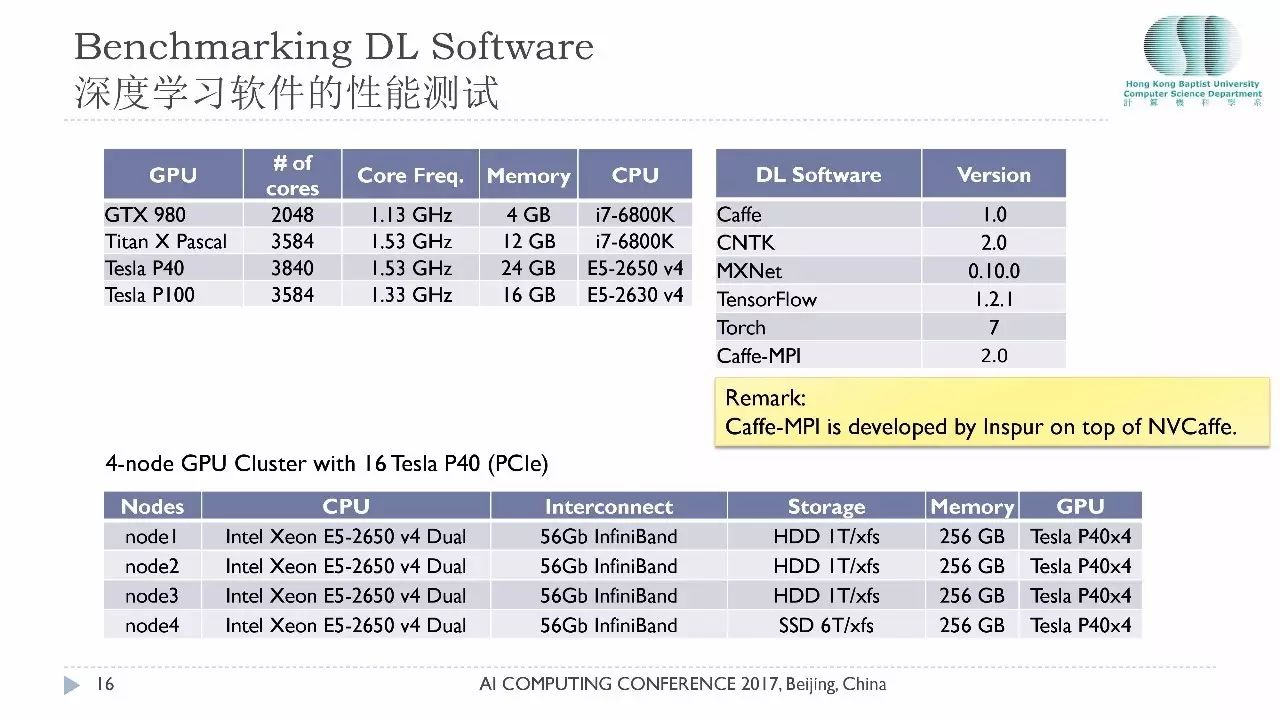
在深度学习整体框架的测试,最新的测试主要是针对四款GPU包括GTX 980、X Pascal另外还有P40和P100。测试的软件还是刚才提到的那五款软件。近期我们和浪潮合作也在测试他们的Caffe-MPI。Caffe-MPI是基于英伟达开发的NVCaffe做的并行版本。我们同时做了一些小规模集群上的测试。这是四个节点的GPU集群,一共有16块P40的卡,它们的网络连接用的56个Gb的网络,大家留意的是我们这个测试环境用的是基于PCle的P40,如果用的是NVlink的显卡那性能应该会更好。
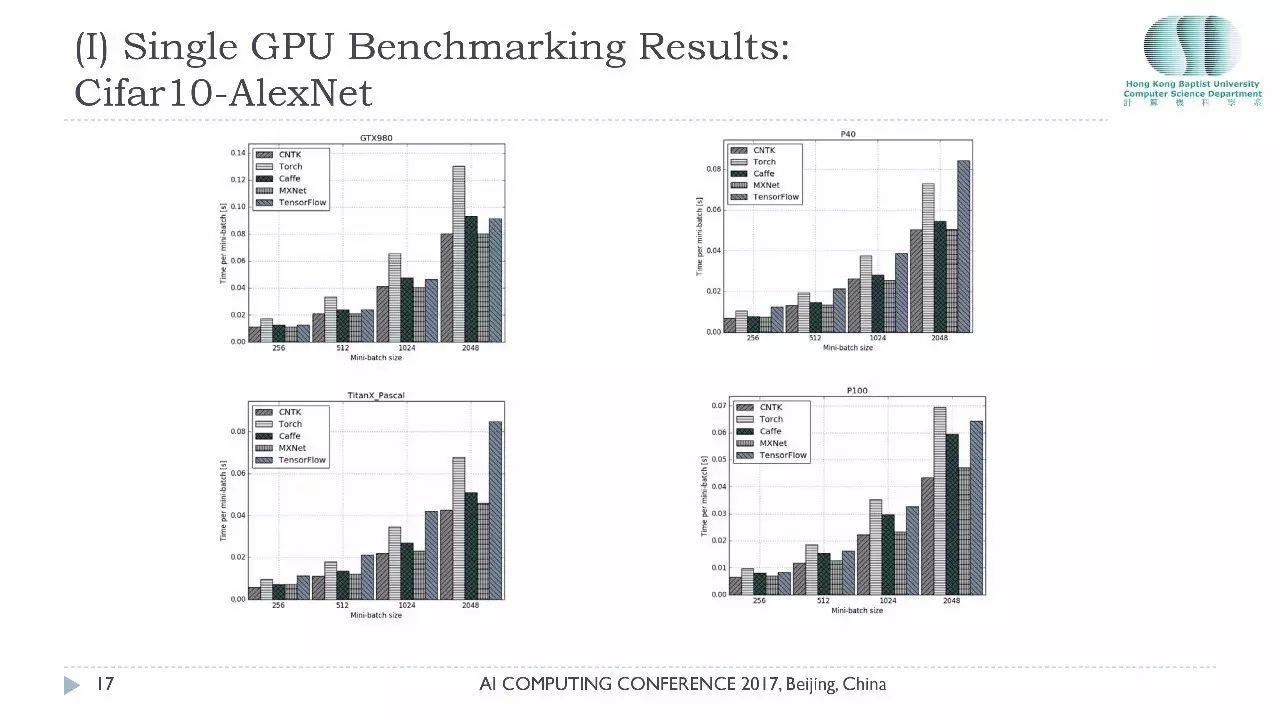
这张图是Cifar10在AlexNet上跑的结果,我们测试了不同的 Minibatch 增加的时候,显示的是运行时间,所以batch越高就代表越慢。在这组测试里面我们发现CNTK的性能的确是最好的,微软这个团队对性能投入了相当多的精力,它的性能在这组测试里是最好的。大家以后决定用什么平台用什么硬件的时候一定要自己做好测试,看看你自己用的是哪款卡,以决定你选取哪一个平台,或者你先决定用哪个平台再考虑选哪一款卡,二者之间有一个匹配问题。
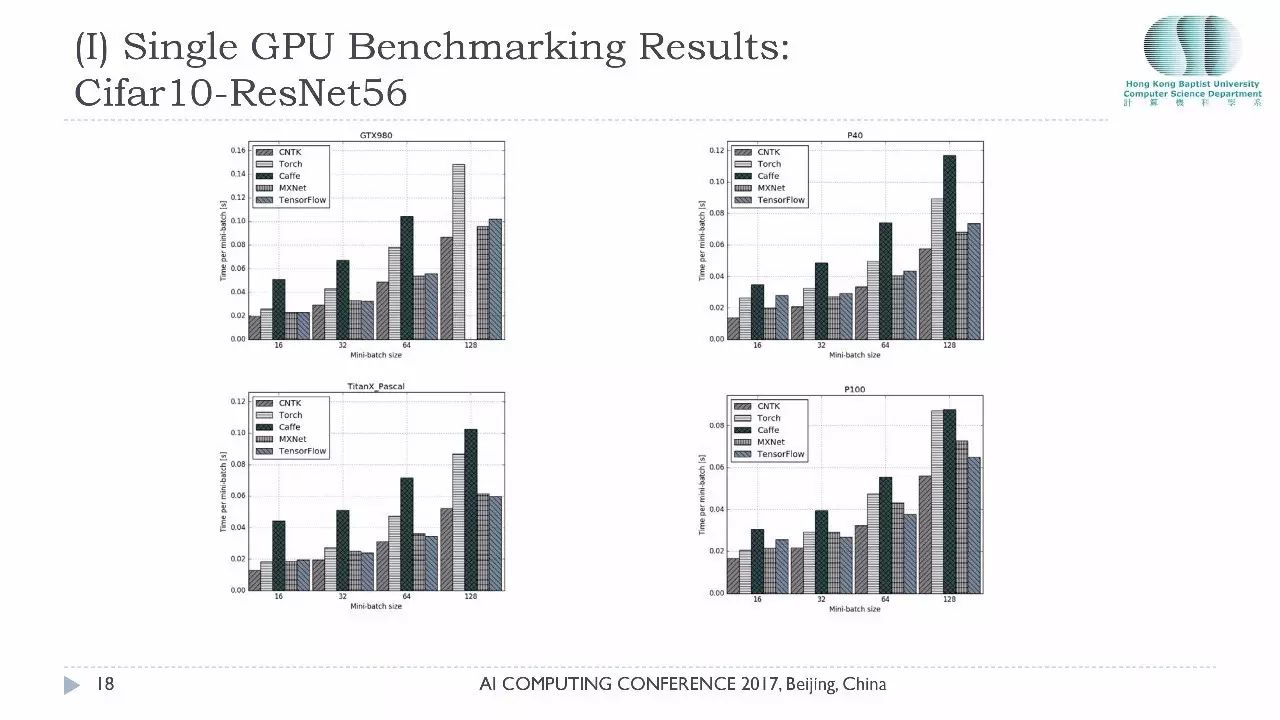
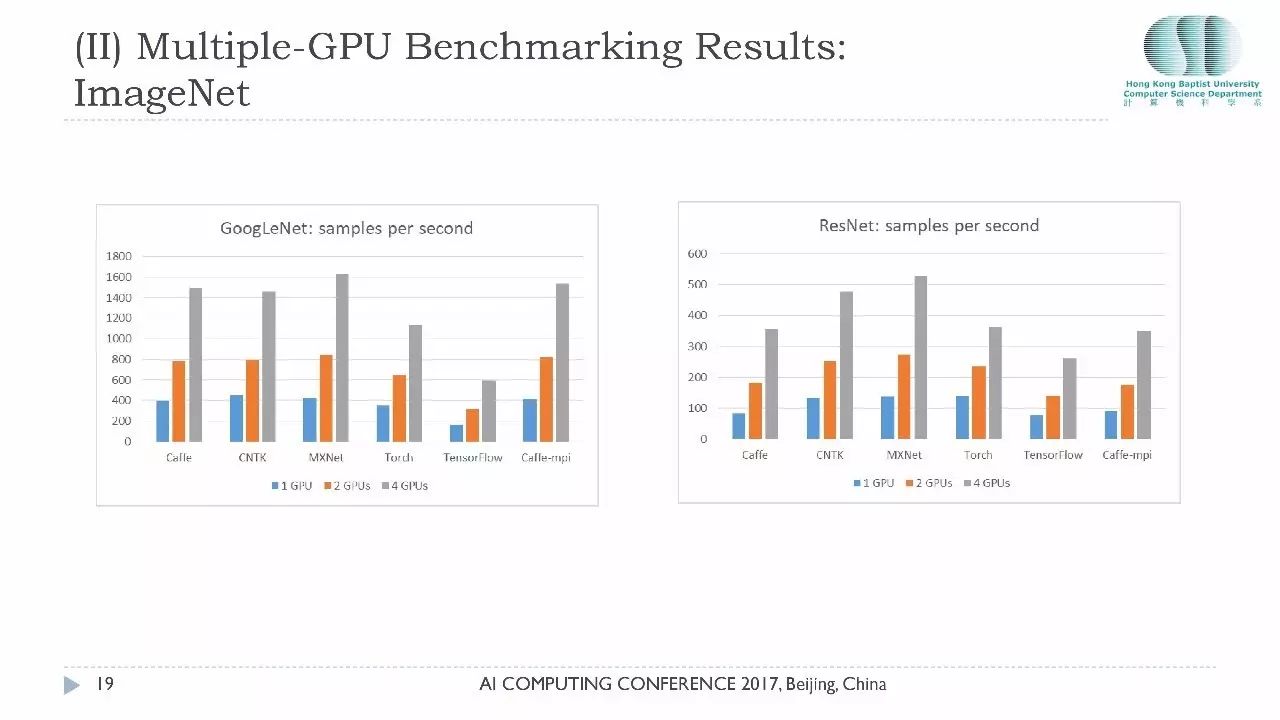
今天主要想跟大家分享的是在多卡环境下的性能,因为单卡过去一年我们已经做出了非常多的报告,多卡的环境的测试相对比较少一点。单机多卡状态下,大家关心的是一个加速比的问题,如果我要买四张GPU,买一台服务器还是买四台服务器?这涉及到成本的问题。非常高兴地告诉大家通过我们的测试,目前主流的测试平台在单机多卡的表现都非常好,它的加速比基本上都是线性的,而且我们用的是PCIE总线,没有使用NVlink,如果使用NVlink的话,卡和卡之间的通信性能会更好一点。
最后汇报一下我们在GPU集群上的测试结果。这个集群是4个节点的集群,每个节点里面有4张卡,最多有16张卡,我们关心的同样是用16张卡的性能和用1张卡的性能到底有多少提升。在GoogleNet上面这里的数据代表的是1秒钟能够处理多少张图像,如果考虑单卡大家可以看到CNTK和MxNet性能差不多,但是扩展性上MxNet的性能在16张卡的性能在我们测试里是最好的,涉及到磁盘IO问题。
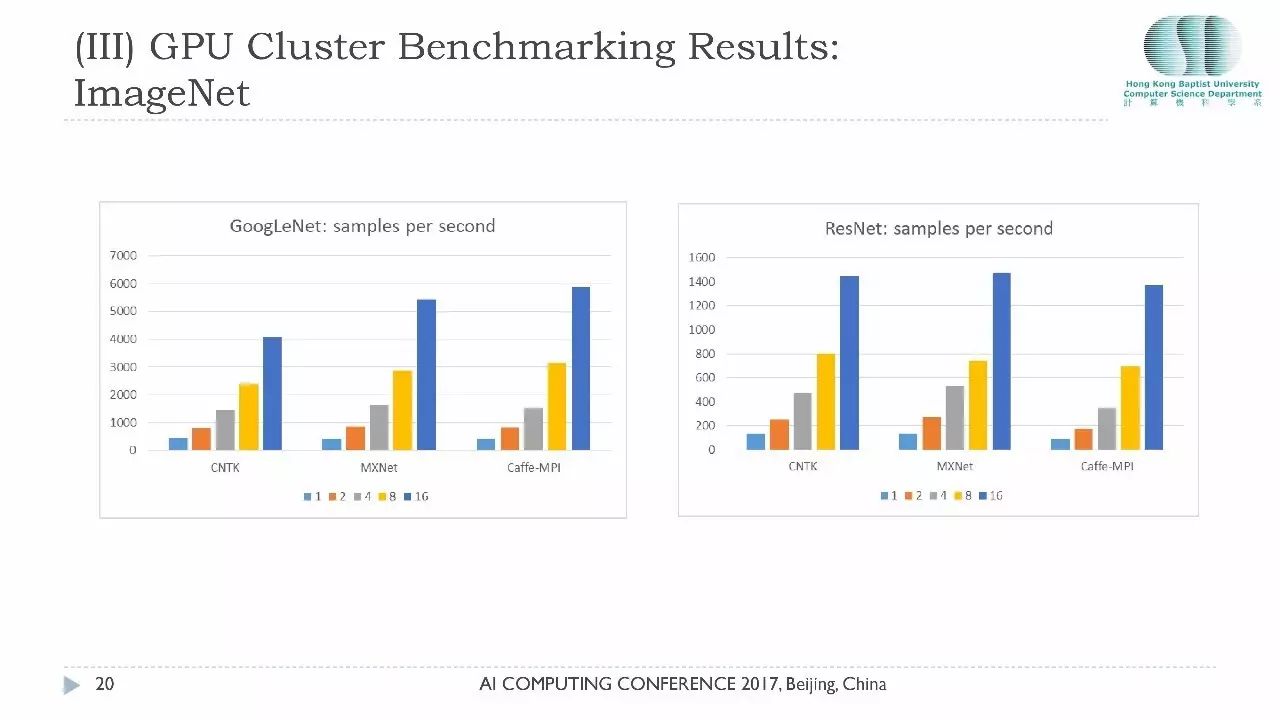
CaffeMPI的加速比是最好的,加速比达到了16张卡可以带来15倍的提升,但是为什么它的绝对性能并没有CNTK和MxNet这么好,因为单卡性能基于NVCaffe开发的。如果大家想对Caffe-MPI了解更多的话,下午四点钟浪潮的吴博士会给大家做一个关于Caffe-MPI的详细介绍,尤其使用Caffe的用户大家想想怎么把Caffe这个平台扩展到多机的环境下面,Caffe-MPI是非常好的选择。

最后谈一下我们近期的计划。首先我们要考虑把其他主流的比较新的深度学习软件包括进来,比如百度的PaddlePaddle,还有近期的PyTorch。硬件方面我们考虑把AMD的芯片和软件做一些测试比较,有可能我们也会联络一些做AI芯片的公司跟我们一起做一些Benchmark,我们希望扩展性方面把16张卡做到更多,比如32张卡64张卡,尤其在Cloud里面的表现。
我们欢迎同大家合作,我们是一个非常开放的平台,任何有兴趣的朋友都可以发邮件给我。最后我要感谢浪潮提供这么好的一个平台给大家,也感谢英伟达对我们提供了很多硬件的支持,感谢CNTK团队、Tensorflow团队和MxNet团队对我们的支持,谢谢大家。
【号外】新智元正在进行新一轮招聘,
点击阅读原文可查看职位详情,期待你的加入~
以上是关于深度学习框架大PK褚晓文教授:五大深度学习框架三类神经网络全面测评(23PPT)的主要内容,如果未能解决你的问题,请参考以下文章
学界 | 不同硬件不同网络,横向对比五大深度学习框架(附论文第七版)