学界 | 香港浸会大学:四大分布式深度学习框架在GPU上的性能评测
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学界 | 香港浸会大学:四大分布式深度学习框架在GPU上的性能评测相关的知识,希望对你有一定的参考价值。
选自arXiv
机器之心编译
参与:陈韵竹、李泽南
随着深度学习应用不断进入商用化,各类框架在服务器端上的部署正在增多,可扩展性正逐渐成为性能的重要指标。香港浸会大学褚晓文团队近日提交的论文对四种可扩展框架进行了横向评测(Caffe-MPI、CNTK、MXNet 与 TensorFlow)。该研究不仅对各类深度学习框架的可扩展性做出了对比,也对高性能服务器的优化提供了方向。
近年来,深度学习(DL)技术在许多 AI 应用当中取得了巨大成功。在获得大量数据的情况下,深度神经网络(DNN)能够很好地学习特征表示。但是,深度神经网络和大规模数据有着很高的计算资源要求。幸运的是,一方面,硬件加速器例如 GPU,FPGA 和 Intel Xeon Phi 可减少模型训练时间。另一方面,近期的一些研究已经证明,具有非常大的 mini-batch 的 DNN 可以很好地收敛到局部最小值。这对于利用大量处理器或集群而言是非常重要的。单个加速器的计算资源(比如计算单元和内存)有限,无法处理大规模神经网络。因此,人们提出了并行训练算法以解决这个问题,比如模型并行化和数据并行化。这也让科技巨头们在云服务中部署可扩展深度学习工具成为可能。亚马逊采用 MXNet 作为云服务 AWS 的主要深度学习框架,谷歌采取 TensorFlow 为谷歌云提供支持,而微软为微软云开发了 CNTK。此外,浪潮集团开发了 Caffe-MPI 以支持 HPC 的分布式部署。
在英伟达高性能 DNN 库 cuDNN 的帮助下,CNTK,MXNet 和 TensorFlow 除了能在单 GPU 上实现高吞吐率之外,还能在多个 GPU 和多种机器之间实现良好的可扩展性。这些框架为开发者提供了一个开发 DNN 的简便方法。此外,尝试相关算法优化,通过使用多核 CPU、众核 GPU、 多 GPU 和集群等硬件来实现高吞吐率。但是,由于软件开发商的实施方法不尽相同,即使在同一个硬件平台上训练相同的 DNN,这些工具的性能表现也不尽相同。研究者已经对各种工具在不同 DNN 和不同硬件环境下进行了评估,但是深度学习框架和 GPU 的升级太过频繁,导致这些基准无法反映 GPU 和软件的最新性能。另外,多 GPU 和多机平台的可扩展性还没有得到很好的研究,但这是计算机集群最重要的性能指标之一。
本文扩展了我们之前的工作,尝试评估 4 个分布式深度学习框架(即 Caffe-MPI、CNTK、MXNet 和 TensorFlow)的性能。我们使用四台由 56 Gb 的 InfiniBand 架构网络连接的服务器,其中每一个都配备了 4 块 NVIDIA Tesla P40,以测试包括单 GPU,单机多 GPU,和多机在内的 CNN 架构的训练速度。我们首先测试了随机梯度下降(SGD)优化的运行性能,然后关注跨多 GPU 和多机的同步 SGD(S-SGD)的性能,以分析其细节。我们的主要研究发现如下:
对于相对浅层的 CNN(例如 AlexNet),加载大量训练数据可能是使用较大 mini-batch 值和高速 GPU 的潜在瓶颈。有效的数据预处理可以降低这一影响。
为了更好地利用 cuDNN,我们应该考虑自动调优以及输入数据的格式(例如 NCWH,NWHC)。CNTK 和 MXNet 都对外显露了 cuDNN 的自动调优配置,这都有利于在前向传播和反向传播中获得更高的性能。
在拥有 multiple GPU 的 S-SGD 当中,CNTK 不会隐藏梯度通信的开销。但是,MXNet 和 TensorFlow 将当前层的梯度聚合与前一层的梯度计算并行化处理。通过隐藏梯度通信的开销,扩展性能会更好。
所在四个高吞吐量的密集 GPU 服务器上,所有框架的扩展结果都不是很好。通过 56Gbps 网络接口的节点间梯度通信比通过 PCIe 的节点内通信慢得多。
论文:Performance Modeling and Evaluation of Distributed Deep Learning Frameworks on GPUs
论文链接:https://arxiv.org/pdf/1711.05979.pdf
深度学习框架已经被广泛部署于 GPU 服务器上,已为学术界和工业界的深度学习应用提供支持。在深度学习网络(DNN)的训练中,有许多标准化过程或算法,比如卷积运算和随机梯度下降(SGD)。但是,即使是在相同的 GPU 硬件运行相同的深度学习模型,不同架构的运行性能也有不同。这篇文章分别在单 GPU,多 GPU 和多节点环境下评估了四种先进的分布式深度学习框架(即 Caffe-MPI、CNTK、MXNet 和 TensorFlow)的运行性能。首先,我们构建了使用 SGD 训练深度神经网络的标准过程模型,然后用 3 种流行的卷积神经网络(AlexNet、GoogleNet 和 ResNet-50)对这些框架的运行新能进行了基准测试。通过理论和实验的分析,我们确定了可以进一步优化的瓶颈和开销。文章的贡献主要分为两个方面。一方面,对于终端用户来说,针对他们的场景,测试结果为他们选择合适的框架提供了参考。另一方面,被提出的性能模型和细节分析为算法设计和系统配置而言提供了更深层次的优化方向。

表 2 针对数据并行化的实验硬件配置
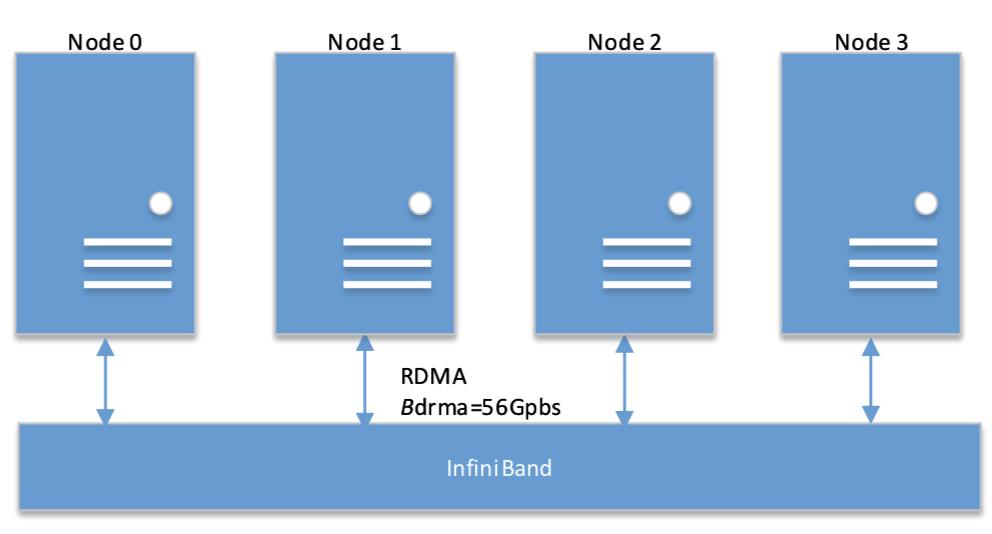
图 1 GPU 集群的拓扑
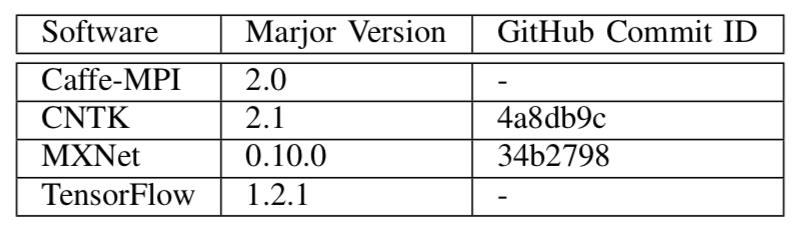
表 3 实验所用的软件

表 4 试验中神经网络的设置
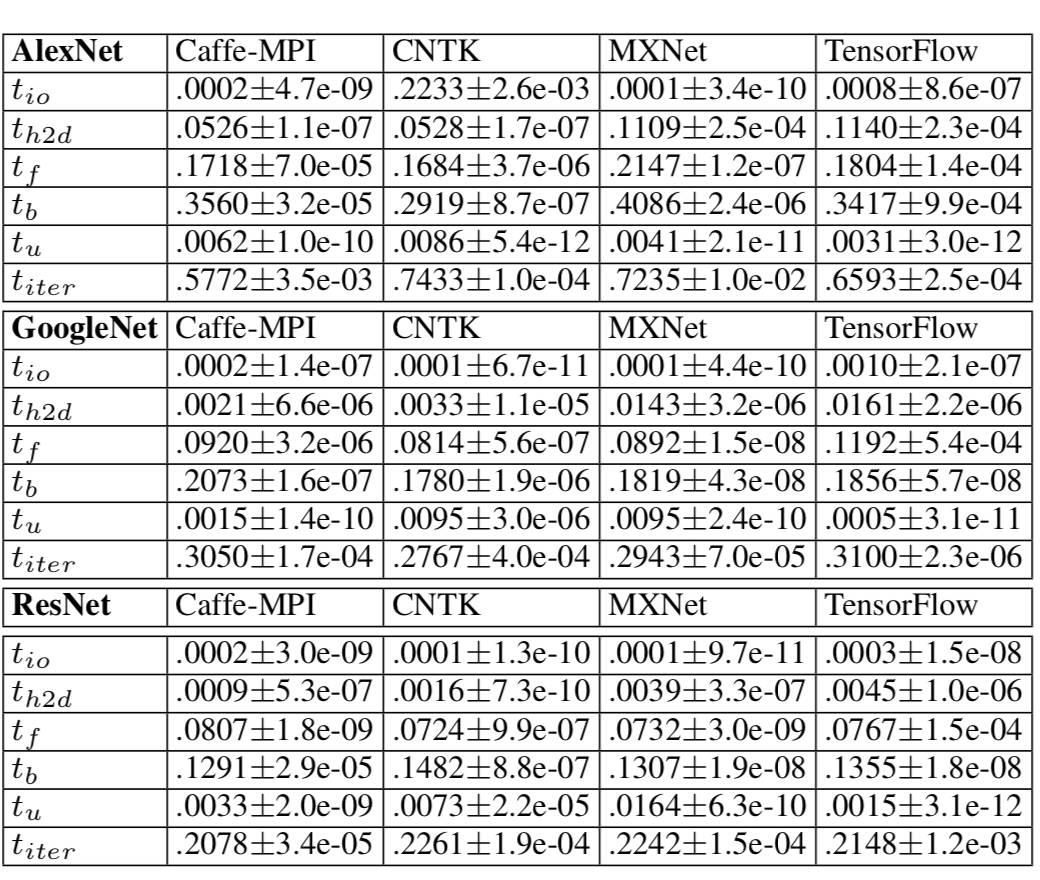
表 5 SGD 不同阶段的时间(单位:秒)
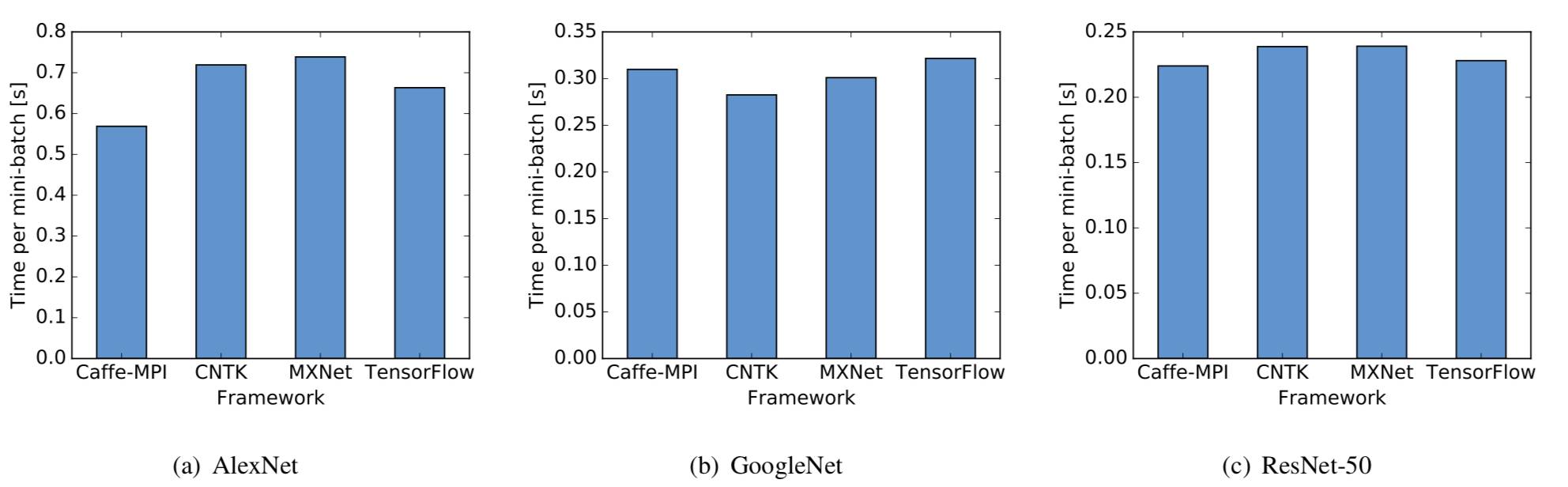
图 3 三种神经网络在单 GPU 上的性能比较(数值越低越好)
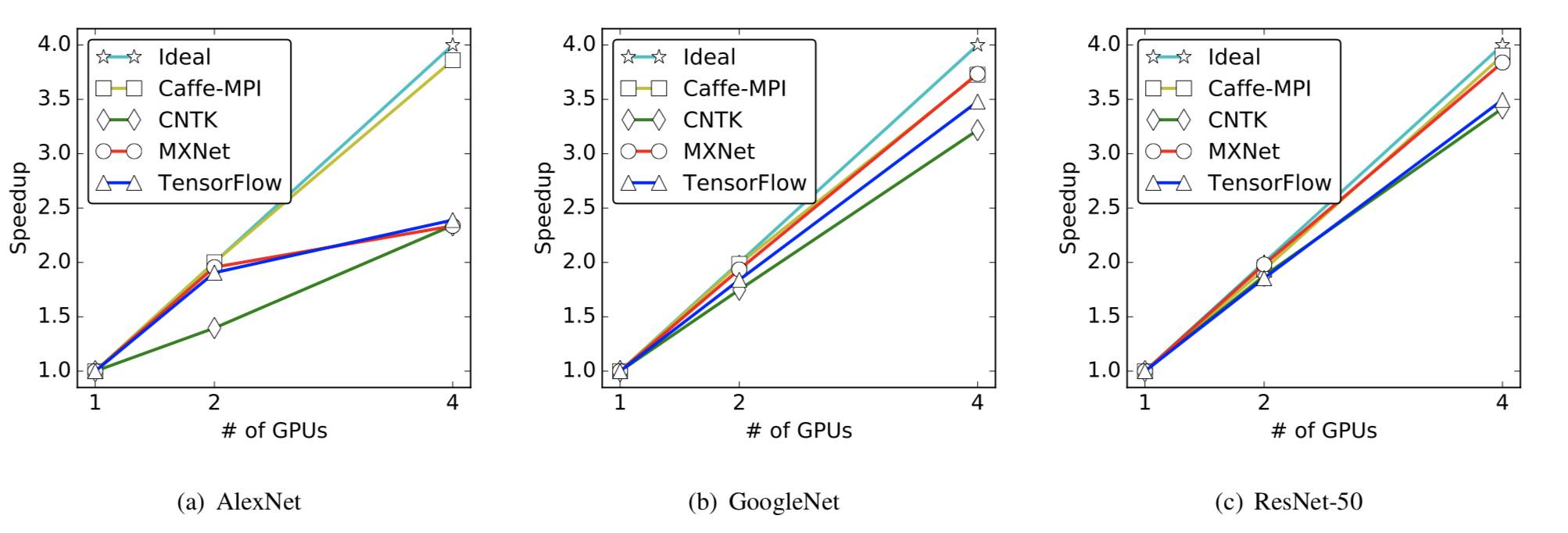
图 4 三种神经网络在单节点多 GPU 上的扩展性能
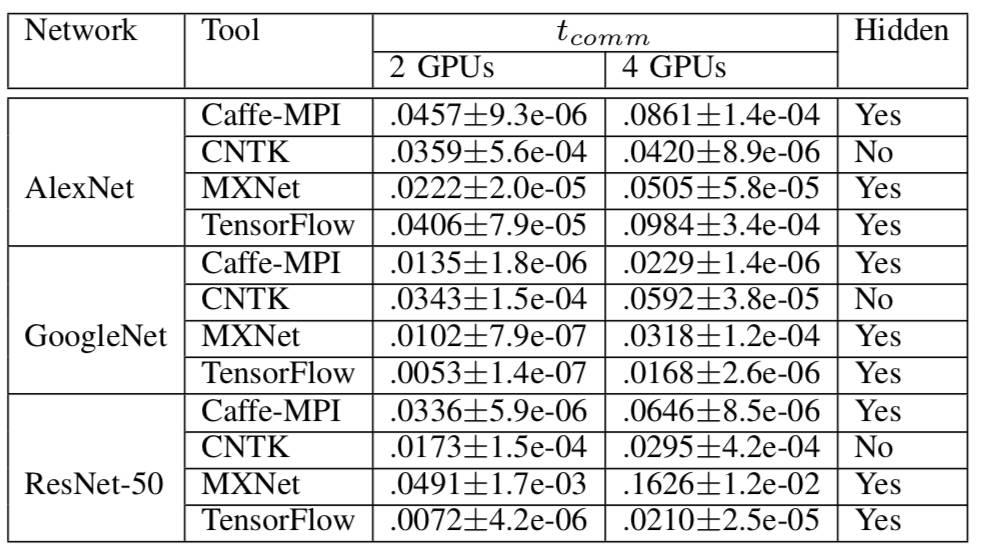
表 6 多 GPU 前端节点梯度聚合的数据通信开销
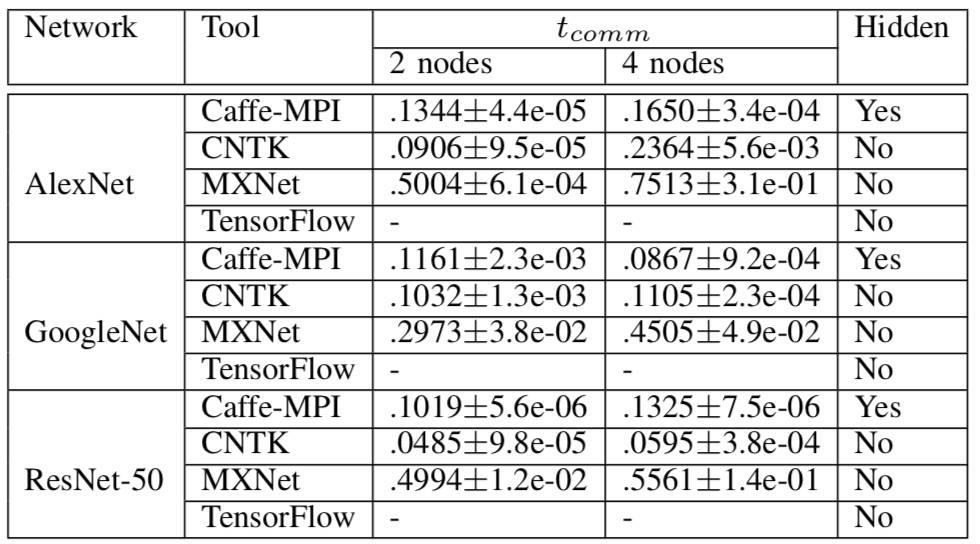
表 7 多机梯度聚合的数据通信开销
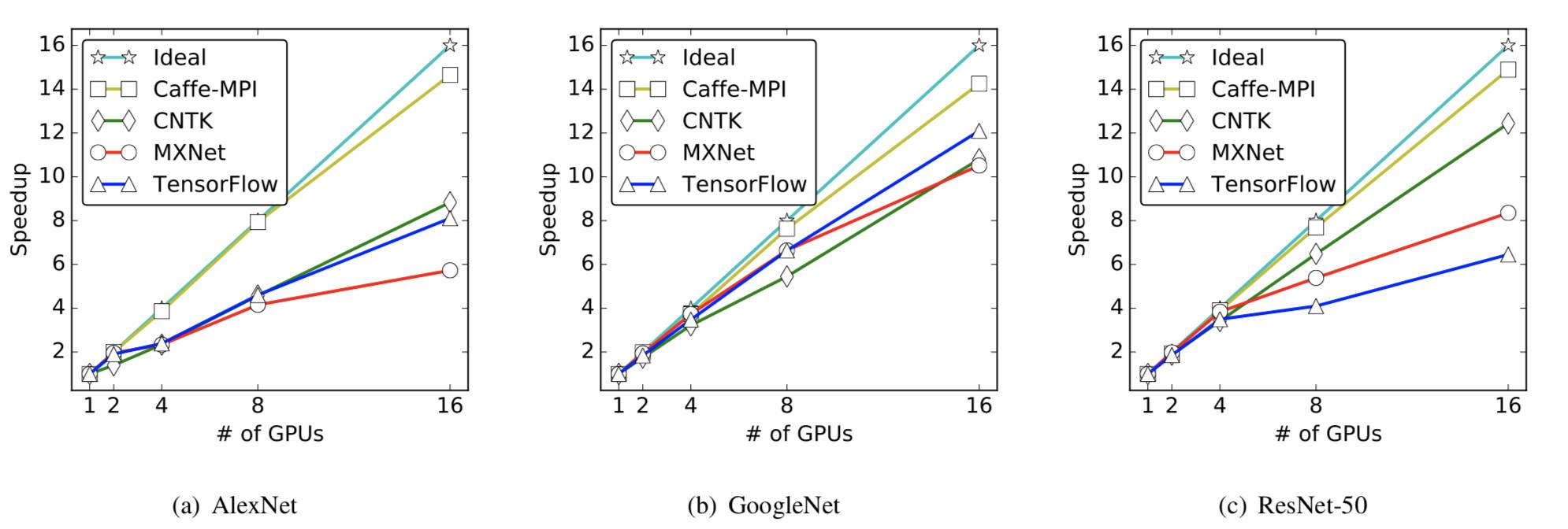
图 5 多机环境下三种神经网络的扩展性能。请注意,每台机器 4 块 GPU,8 块 GPU 和 16 块 GPU 的情况是分别跨 2 个与 4 个机器的。
表 8 所有测试案例的速度
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论。
以上是关于学界 | 香港浸会大学:四大分布式深度学习框架在GPU上的性能评测的主要内容,如果未能解决你的问题,请参考以下文章
学界 | 腾讯提出并行贝叶斯在线深度学习框架PBODL:预测广告系统的点击率
李飞飞:我更像物理学界的科学家,而不是工程师|深度学习崛起十年