分布式深度学习框架PK:Caffe-MPI, CNTK, MXNet ,TensorFlow性能大比拼
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式深度学习框架PK:Caffe-MPI, CNTK, MXNet ,TensorFlow性能大比拼相关的知识,希望对你有一定的参考价值。
新智元AI World 2017世界人工智能大会开场视频
中国人工智能资讯智库社交主平台新智元主办的11月8日在北京国家会议中心举行,大会以“AI 新万象,中国智能+”为主题,上百位AI领袖作了覆盖技术、学术和产业最前沿的报告和讨论,2000多名业内人士参会。新智元创始人兼CEO杨静在会上发布全球首个AI专家互动资讯平台“新智元V享圈”。
全程回顾新智元AI World 2017世界人工智能大会盛况:
新华网图文回顾
http://www.xinhuanet.com/money/jrzb20171108/index.htm
爱奇艺
上午:http://www.iqiyi.com/v_19rrdp002w.html
下午:http://www.iqiyi.com/v_19rrdozo4c.html
阿里云云栖社区
https://yq.aliyun.com/webinar/play/316?spm=5176.8067841.wnnow.14.ZrBcrm
新智元编译
编译:弗格森 马文
【新智元导读】这篇论文评估了四个state-of-the-art 的分布式深度学习框架,即Caffe-MPI, CNTK, MXNet 和 TensorFlow分别在单个GPU、多GPU和多节点的环境中的表现。
在学术和产业界,深度学习框架都已经被广泛地部署在面向深度学习应用的GPU服务器中。在深度神经网络的训练过程中,有许多标准的进程或者算法,比如卷积或者随机梯度下降(SGD),但是,不同的框架的运行性能是不一样的,即使是在相同的GPU硬件下运行相同深度的模型。
在这篇论文中,我们评估了四个state-of-the-art 的分布式深度学习框架,即Caffe-MPI, CNTK, MXNet 和 TensorFlow分别在单个GPU、多GPU和多节点的环境中的表现。我们首先以SGD为基础构建DNN训练标准流程的性能模型,然后用三种流行的卷积神经网络(AlexNet,GoogleNet和ResNet-50)对这些框架的运行性能进行基准测试,进而分析哪些因素造成了这四个框架之间的表现差距。 通过分析和实验解析,我们找出可以进一步优化的瓶颈和开销(overheads)。 研究的主要贡献是双重的。首先,测试结果为最终用户为自己的场景选择合适的框架提供了参考。 其次,所提出的性能模型和详细分析为算法设计和系统配置提供了进一步的优化方向。
近年来,深度学习技在许多AI应用上获得了巨大的成功。拥有大量的数据之后,深度神经网络可以很好地学习特征表示。但是,非常深的神经网络以及大规模的数据,对计算资源的需求也是极大的。幸运的是,一些硬件加速器,包括GPU、FPGA和英特尔至强处理器都能用于减少模型的训练时间。
另一方面,最近,有研究证明,拥有非常大的mini-batch的DNN可以得到很好的聚敛,进而达到局部最小化,这对于高效地利用多处理器或者集群来说非常有意义。要处理大规模的设计网络,一个单一的加速器的计算资源是有限的(比如,计算单元和存储),所以,有人提出了并行训练算法以解决这一问题,相应的例子包括模型并行和数据并行。这也刺激科技巨头在云服务上部署可扩展的深度学习工具。亚马逊采纳了MXNet作为亚马逊云服务(AWS)主要的深度学习框架,谷歌在谷歌云上使用TensorFlow,微软在Amazon Azure上部署CNTK。此外,浪潮也开发了Caffe-MPI,来支持HPC上的分布式部署。
英伟达推出的cuDNN是一个高性能DNN数据库,有了cuDNN,CNTK, MXNet 和TensorFlow 不仅在单GPU上实现了高的吞吐量,而且在多GPU和多机器上,也可以拥有很好的可扩展性。
这些框架提供了一个简便的方法,让用户可以开发DNN,并尝试优化相关的算法,通过使用硬件平台,比如多核CPU、多核GPU和多GPU以及多机器,来实现较高的吞吐量。
然而,由于不同厂商会有不同的实现方法,即使是在相同的硬件平台上训练相同的DNN,这些工具也展示了不同的性能。此前,有研究者用各种DNN评估了不同的工具在不同的硬件平台上的表现,但是,框架和GPU的更新速度如此之快,导致很多基准并不能反映更新的GPU以及软件的最新性能。此外,多GPU和多机器的可扩展性一直也没有得到很好的研究,而这是集群中最重要影响因素之一。这篇论文扩展了此前的工作——用DNN 评估了四个分布式深度学习工具(即,Caffe-MPI, CNTK, MXNet 和 TensorFlow)在GPU集群上的表现。我们使用了四台机器,由52Gb的InfiniBand 网络连接,每一台都配备了四块英伟达Tesla P40,以测试每一个框架在训练CNN时的表现,覆盖单一GPU、多GPU和多机器环境。我们首先测试了SGD优化的运行表现,随后,我们聚焦于多GPU和多机器环境下的 同步 SGD (S-SGD)表现,以分析性能的细节。我们的主要发现有以下四点:
对于相对较浅的CNN(比如AlexNet),在拥有大的mini-batch和快速的GPU条件下,加载大量的训练数据可能会成为一个潜在的瓶颈。可以采用有效的数据预处理,来减少相应的影响。
为了更好地使用cuDNN,可以考虑自动调参(autotune)和输入数据层(例如,NCWH, NWHC)。CNTK 和 MXNet都展示了cuDNN的autotune configuration,在前向或者反向传播中,这都能带来更好的性能。
在多GPU条件下的 S-SGD中,CNTK没有隐藏梯度信息传递中的重叠,但是MXNet 和TensorFlow 用与前面层神经网络的梯度信息传递,对循环层中的梯度聚合进行并行化。通过隐藏梯度信息传递中的重叠,可扩展性能够做到更好。
在四个高吞吐量的多GPU服务器,所有框架的扩展性都不是特别理想。通过56Gbps网络接口的intra-node梯度通信比通过PCIe的intra-node慢得多。
这篇论文接下来介绍了这一研究的相关工作,不同方法实施的SGD和S-SGD的初步研究,并为S-SDG的不同实现提供了一些性能模型。在论文的第五部分,作者介绍了他们的实验方法和实验结果,以及在第六部分进行了分析。限于篇幅,本文接下来介绍这一研究的实验方法和结果,具体内容请查阅原始论文。
我们首先指定了实验所采用的硬件环境。我们使用4个节点的GPU集群,其中每个节点都有4个NVIDIA Tesla P40卡,而节点之间的网络连接是一个56 Gbps的InfiniBand和一个Gbps以太网。表2是实验的硬件设置。

表2:用于数据并行化的实验硬件设置。
图1展示了这个集群的拓扑结构,图2展示了不同组件间的数据传输带宽的内部节点拓扑。每块Tesla P40 GPU 都以1.3 GHz的基本核心频率运行,自动提升功能被禁用,以确保我们实验结果的复现性。
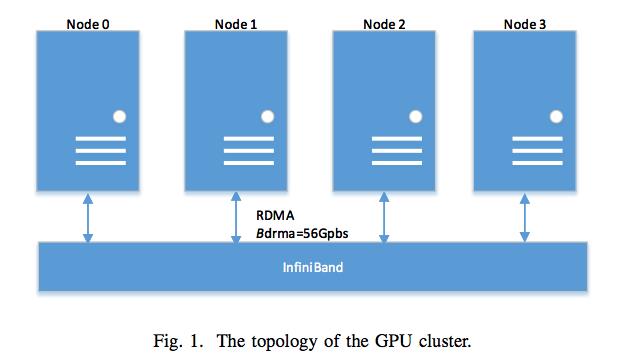
图1:GPU集群的拓扑结构
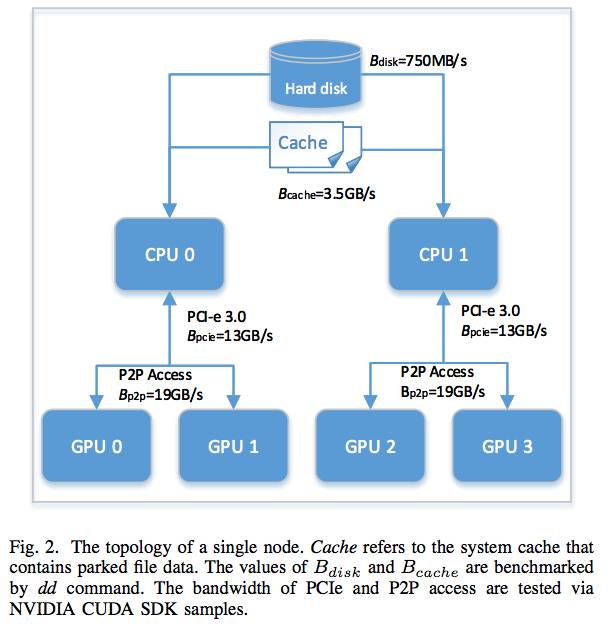
图2:单个节点的拓扑结构
在每个节点中安装的测试框架的版本如表3所示。
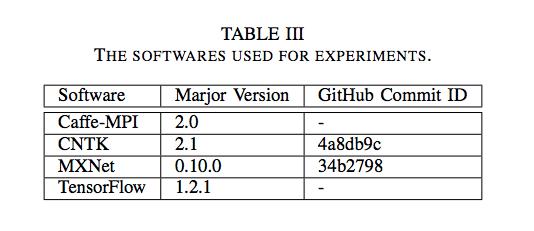
表3:实验使用的软件
评估运行性能的一种流行且有效的方法是测量处理一个mini-batch的输入数据的一个迭代的持续时间或每秒处理的样本数量。我们在这些工具上使用适当的mini-batch大小(尽量充分利用GPU资源)来对CNN进行基准测试。
我们选择了三个流行的CNN(即:在ILSVRC-2012 ImageNet数据集运行的AlexNet,GoogleNet和ResNet-50)。集群中的每台机器都有一个数据集的副本。不同框架的数据格式是不同的,我们列出了测试框架下的数据格式。
这三种深层模型对于测试框架的性能都有各自的特性。它们有不同的配置,详细信息如表4所示。
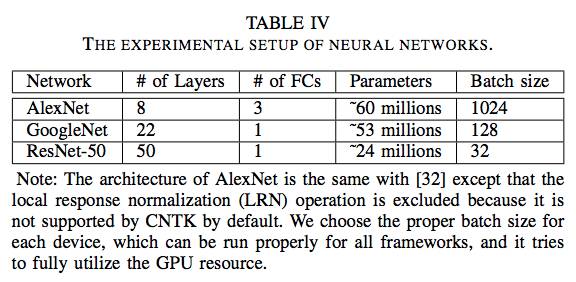
表4:神经网络的实验设置
下面是CNTK、MXNet和TensorFlow分别在单个 P40 卡、多个P40卡,以及跨4个节点的GPU集群训练AlexNet、GoogleNet和ResNet-50的运行性能。
A. 单GPU
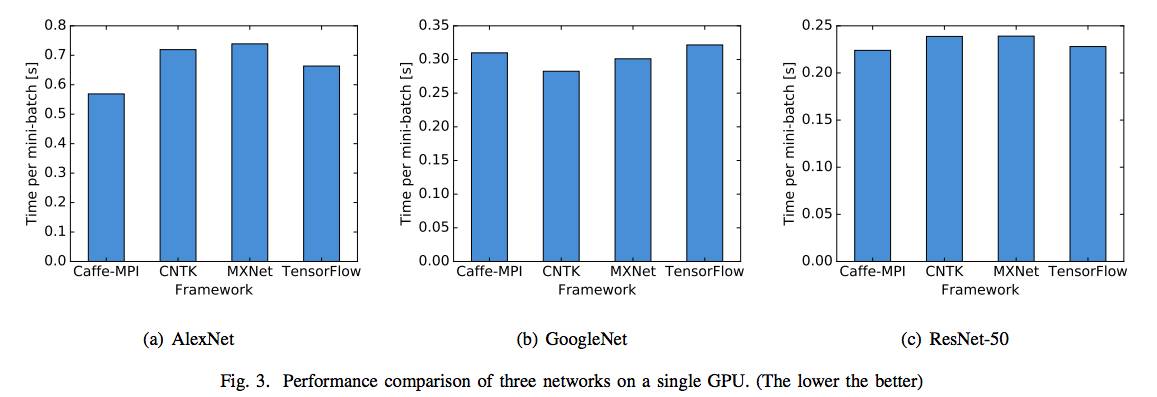
图3:在单个GPU上3个网络的性能比较。(越低越好)
B. 多GPU
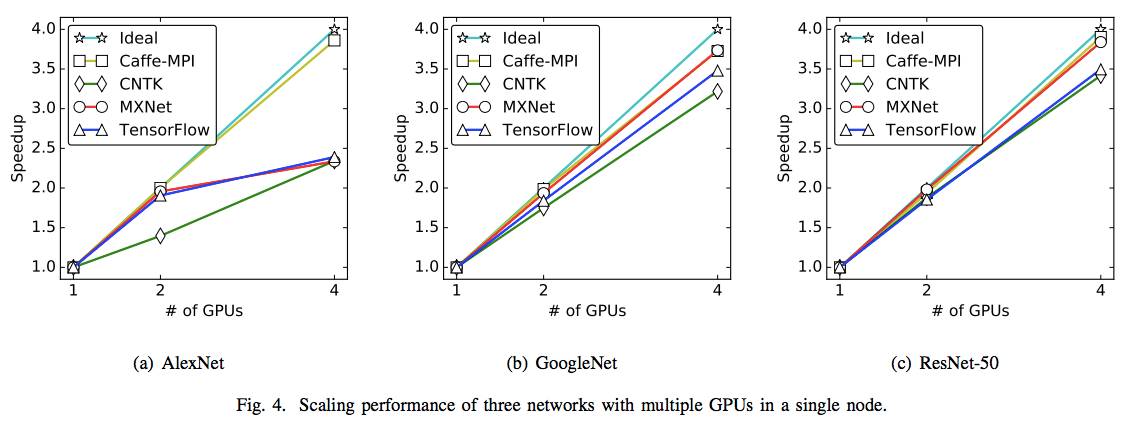
图4:在单个节点上使用多个GPU时3个网络的性能
C. 多机器
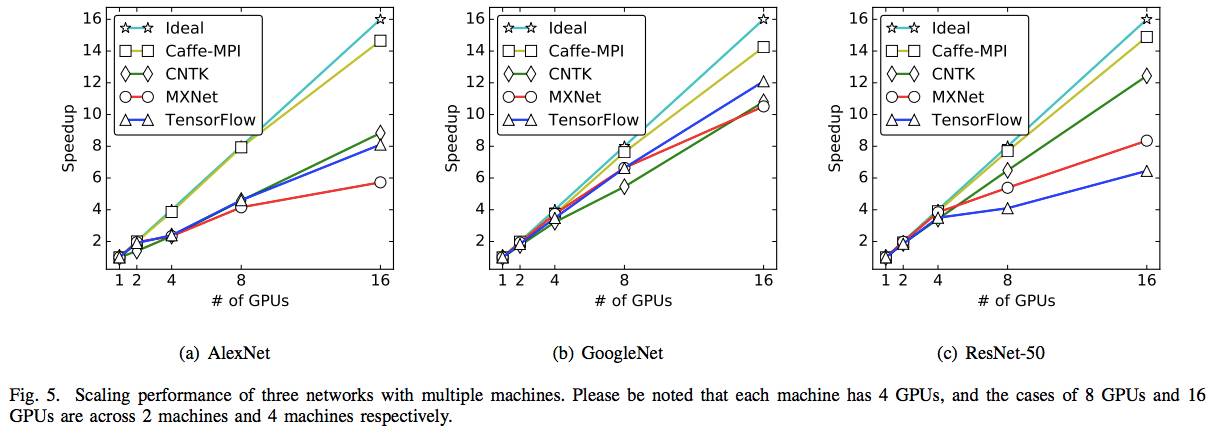
图5:用多台机器来扩展3个网络的性能。请注意,每台机器有4个GPU,8个GPU和16个GPU的情况分别是在2台机器和4台机器上。
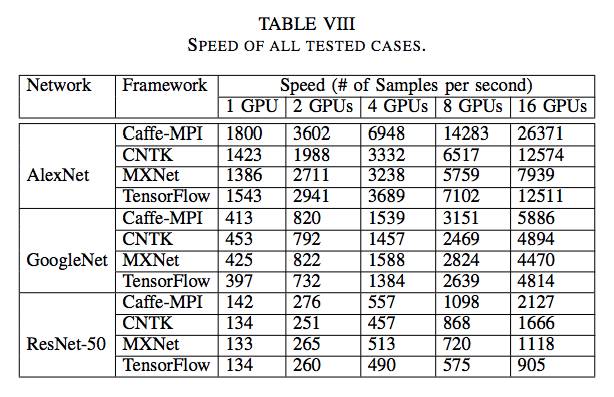
表8:所有测试用例的速度。
在这项工作中,我们评估了4个流行的分布式深度学习框架(Caffe-MPI, CNTK, MXNet 和 TensorFlow)的性能,通过在与56 Gbps InfiniBand连接的4个节点的密集GPU集群上(每个节点4个Tesla P40 GPU)训练3个CNN(AlexNet、GoogleNet和ResNet-50)。我们首先构建了性能模型来测量同步SGD的加速,包括Caffe-MPI, CNTK, MXNet 和 TensorFlow的不同实现。然后,我们对这四种框架的性能进行基准测试,包括单GPU、多GPU和多机器环境。根据实验结果和分析,显示了四种不同实现之间的性能差异,并且存在一些次优化方法,可以进一步优化以提高评估框架的性能,包括I/O、cuDNN调用,以及跨节点GPU之间的数据通信。
对于未来的工作,我们计划在低带宽或高延迟网络(例如,1 Gbps的以太网)中评估DL框架的可扩展性。分布式SGD可能包括异步SGD和模型并行。
以上是关于分布式深度学习框架PK:Caffe-MPI, CNTK, MXNet ,TensorFlow性能大比拼的主要内容,如果未能解决你的问题,请参考以下文章
浪潮发布新版Caffe-MPI,较谷歌TensorFlow性能翻倍
人工智能爆点浪潮发布新版Caffe-MPI,较谷歌TensorFlow 性能翻倍!
学界 | 香港浸会大学:四大分布式深度学习框架在GPU上的性能评测