微软提出深度学习框架的通用语言
Posted 人工智能and深度学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微软提出深度学习框架的通用语言相关的知识,希望对你有一定的参考价值。
在著名的罗塞塔石碑上,相同的古埃及国王登基诏书被几种不同的文字记录着,这让近代的考古学家们能够通过对照各语言,解读出失传千年的埃及象形文字的意义。其实,深度学习框架也像语言一样,每一种都有自己的独特性,如果我们能够为深度学习框架也创建一个“罗塞塔石碑”,那么说着各种不同“语言”的人交流起来会不会更加容易呢?
我们的想法是创建一个深度学习框架的罗塞塔石碑(Rosetta Stone):假设你很了解某个深度学习框架,你就可以帮助别人使用任何框架。你可能会遇到论文中代码是另一个框架或整个流程都使用另一种语言的情况。相比在自己喜欢的框架中从头开始编写模型,使用「外来」语言会更容易。
感谢 CNTK、Pytorch、Chainer、Caffe2 和 Knet 团队,以及来自开源社区的所有人在过去几个月为该 repo 所做的贡献。
我们的目标是:
1. 创建深度学习框架的罗塞塔石碑,使数据科学家能够在不同框架之间轻松运用专业知识。
2. 使用最新的高级 API 优化 GPU 代码。
3. 创建一个 GPU 对比的常用设置(可能是 CUDA 版本和精度)。
4. 创建一个跨语言对比的常用设置(Python、Julia、R)。
5. 验证自己搭建框架的预期性能。
6. 实现不同开源社区之间的合作。
基准深度学习框架的结果
下面我们来看一种 CNN 模型的训练时间和结果(预训练的 ResNet50 模型执行特征提取),以及一种 RNN 模型的训练时间。
训练时间(s):CNN(VGG-style,32bit)在 CIFAR-10 上执行图像识别任务
该模型的输入是标准 CIFAR-10 数据集(包含 5 万张训练图像和 1 万张测试图像),均匀地分成 10 个类别。将每张 32×32 图像处理为形状 (3, 32, 32) 的张量,像素强度从 0-255 重新调整至 0-1。
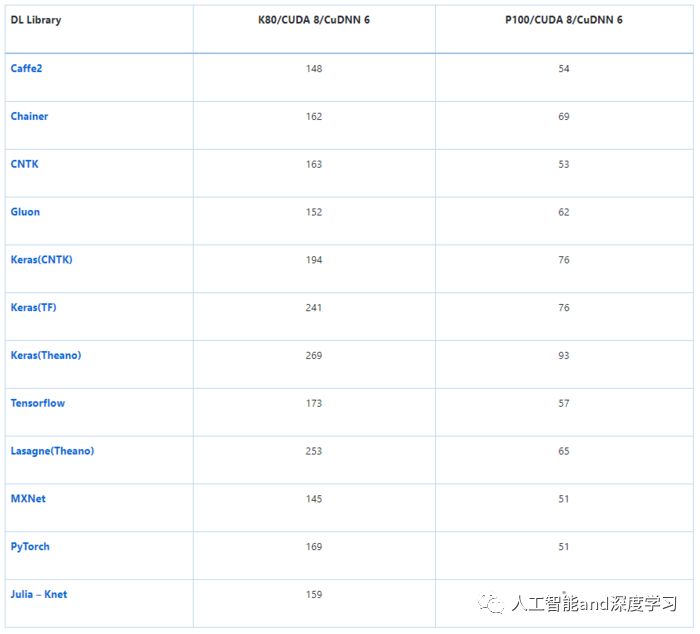
处理 1000 张图像的平均时间(s):ResNet-50——特征提取
加载预训练 ResNet-50 模型在末端 (7, 7) 平均池化之后裁断,输出 2048D 向量。其可插入 softmax 层或另一个分类器(如 boosted tree)来执行迁移学习。考虑到热启动,这种仅前向传播至 avg_pool 层的操作有时间限制。注意:批量大小保持常量,但是增加 GPU 内存可带来更好的性能提升(GPU 内存越多越好)。
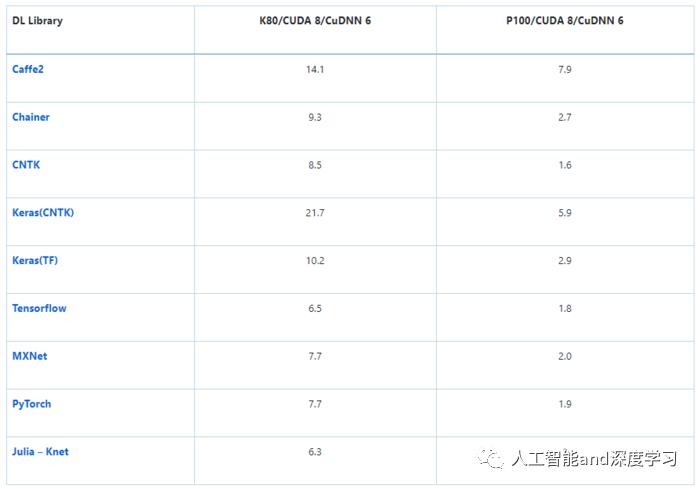
训练时间(s):RNN (GRU) 在 IMDB 数据集上执行情感分析任务
模型输入为标准 IMDB 电影评论数据集(包含 25k 训练评论和 25k 测试评论),均匀地分为两类(积极/消极)。使用 https://github.com/keras-team/keras/blob/master/keras/datasets/imdb.py 中的方法进行处理,起始字符设置为 1,集外词(OOV,本次训练使用的词汇表包括 3 万单词)设置为 2,这样单词索引从 3. Zero 开始,通过填充或截断使每条评论固定为 150 词。
经验教训
1. 使用自动调参模式:大部分框架使用 cuDNN 的 cudnnFindConvolutionForwardAlgorithm() 来运行穷举搜索,优化在固定大小图像上前向卷积所使用的算法。这通常是默认的设置,但是一些框架可能需要一个 flag,例如 torch.backends.cudnn.benchmark=True。
2. 尽可能多地使用 cuDNN:常用的 RNN(如基础 GRU/LSTM)通常可以调用 cuDNN 封装器来加速,即用 cudnn_rnn.CudnnGRU() 代替 rnn.GRUCell()。缺点是稍后在 CPU 上运行推断时难度可能会增加。
3. 匹配形状:在 cuDNN 上运行时,为 CNN 匹配 NCHW 的原始 channel-ordering、为 RNN 匹配 TNC 可以削减浪费在重塑(reshape)操作上的时间,直接进行矩阵乘法。
4. 原始生成器:使用框架的原始生成器,增强和预处理(例如 shuffling)通过多线程进行异步处理,实现加速。
5. 对于推断,确保指定的 flag 可以保存被计算的非必要梯度,以及 batch-norm 和 drop-out 等层得到合理使用。
当我们从头开始创建该 repo 的时候,为了确保在不同框架之间使用的是相同的模型,并以最优化的方式运行,我们使用了很多技巧。过去几个月里,这些框架的改版之快令人惊讶,框架的更新导致很多在 2017 年末学会的优化方法如今已然过时。
例如,以 TF 为后端的 Keras 拥有 channel-ordering 硬编码作为 channels-last(对于 cuDNN 不是最优的),因此指定 channels-first 意味着它将在每个批次(batch)之后重塑到硬编码值,从而极大降低训练速度。现在以 TF 为后端的 keras 支持原始 channels-first ordering。之前,TensorFlow 可以通过指定一个 flag 来使用 Winograd 算法用于卷积运算,然而现在这种方法不再有用。你可以在repo的早期版本(https://github.com/ilkarman/DeepLearningFrameworks/tree/cb6792043a330a16f36a5310d3856f23f7a45662)中查看其中的最初学习阶段部分。
通过在不同的框架中完成端到端解决方案,我们可以用多种方式对比框架。由于相同的模型架构和数据被用于每一个框架,因此得到的模型准确率在各个框架之间是非常相似的(实际上,这正是我们测试代码以确保相同的模型在不同框架上运行的一种方法)。此外,该 notebook 的开发目的是为了使框架之间的对比更加容易,而模型加速则不是必要的。
当然,该项目的目的是使用速度和推断时间等指标来对比不同的框架,而不是为了评估某个框架的整体性能,因为它忽略了一些重要的对比,例如:帮助和支持、提供预训练模型、自定义层和架构、数据加载器、调试、支持的不同平台、分布式训练等。该 repo 只是为了展示如何在不同的框架上构建相同的网络,并对这些特定的网络评估性能。
深度学习框架的「旅行伴侣」
深度学习社区流行着很多种深度学习框架,该项目可以帮助 AI 开发者和数据科学家应用不同的深度学习框架。一个相关的工作是 Open Neural Network Exchange(ONNX),这是一个在框架间迁移深度学习模型的开源互通标准。当在一个框架中进行开发工作,但希望转换到另一个框架中评估模型的时候,ONNX 很有用。类似地,MMdnn 是一组帮助用户直接在不同框架之间转换的工具(以及对模型架构进行可视化)。
深度学习框架的「旅行伴侣」工具如 ONNX 和 MMdnn 就像是自动化的机器翻译系统。相比之下,我们今天发布的 repo 1.0 完整版更像是深度学习框架的罗塞塔石碑,在不同的框架上端到端地展示模型构建过程。
以上是关于微软提出深度学习框架的通用语言的主要内容,如果未能解决你的问题,请参考以下文章