不甘落后Tensorflow, 微软另辟蹊径发布新型深度学习框架
Posted AICamp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不甘落后Tensorflow, 微软另辟蹊径发布新型深度学习框架相关的知识,希望对你有一定的参考价值。
在深度学习框架领域,Google Tensorflow 在使用广泛度上一骑绝尘把微软,亚马逊,Facebook和其它深度学习框架远远甩在后面。为了和Google Tensorflow 抗衡,微软先后联合AWS, Facebook 设立ONNX, 使得同一模型可以在不同框架运行,最近又另辟蹊径发布新型深度学习框架。
我们相信深度学习框架就像语言一样:很多人会说英语,但每种语言都有自己的独特作用。我们为许多不同的网络结构编程了公共代码,并让这些代码在许多不同的框架中运行。我们的目的是创建一个深度学习框架的罗塞塔石碑,假设你会一个框架,就可以帮助别人利用任何框架。通常会出现这种情况:一篇论文中的代码是另一种框架或整个pipeline脚本使用在另一种语言。与其从最喜欢的框架中从头编写一个模型,不如使用“外来”语言更容易。

我们今天发布一个全新的1.0版本,开放源代码在GitHub上,https://github.com/ilkarman/deeplearningframeworks。非常感谢CNTK, Pytorch, Chainer, Caffe2 and Knet teams,以及在过去几个月里面开放源代码社区里对REPO做出过贡献值的每一个人。
新版本的目标:
创建深度学习框架的罗塞塔石碑,使数据科学家能够在不同框架之间轻松运用专业知识。
使用最新的最高级API优化GPU代码
建立跨GPUS比较的通用设置(潜在的CUDA版本和精度)
建立跨语言比较的通用设置(Python,Julia,R)
自主安装的预期可能性
不同的开放源代码社区之间的合作
深度学习框架基准检测结果

下面我们将回顾一种CNN模型的训练时间和结果,预训练的ResNet50模型的特征提取以及一种RNN模型的训练时间。
训练时间(秒):CNN CIFAR-10(VGG式,32位) - 图像识别
CIFAR-10的标准数据图包含50k训练图像和10k测试图像,均匀的分为十个等级。每张 32×32 图像处理为形状 (3, 32, 32) 的张量,像素强度从 0-255 重新调整至 0-1
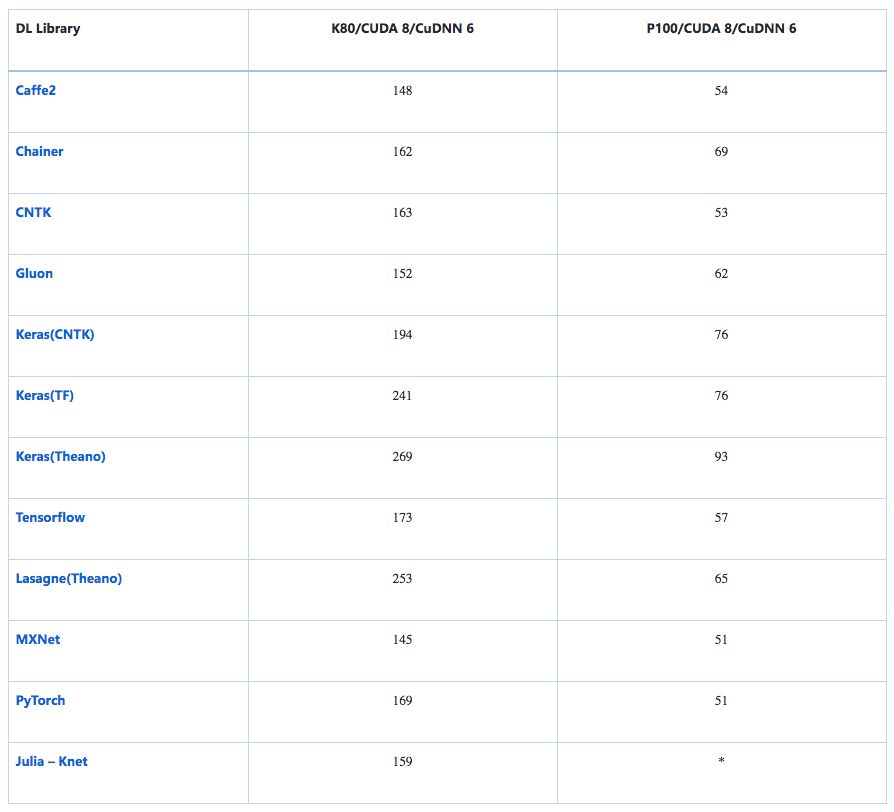
平均时间(秒)处理1000张图片:ResNet-50 - 特征提取
预训练ResNet50模型在结束时(7,7)的avg_pooling之后加载并切断,输出2048D维向量。 这可以插入softmax层或其他分类器(如增强树)以执行传输学习。 考虑到温暖的开始,这个仅向前传递给avg_pool层的时间是定时的。 注意:批量大小保持不变,但是在GPU上填充RAM会产生进一步的性能提升(具有更多RAM的GPU更大)。
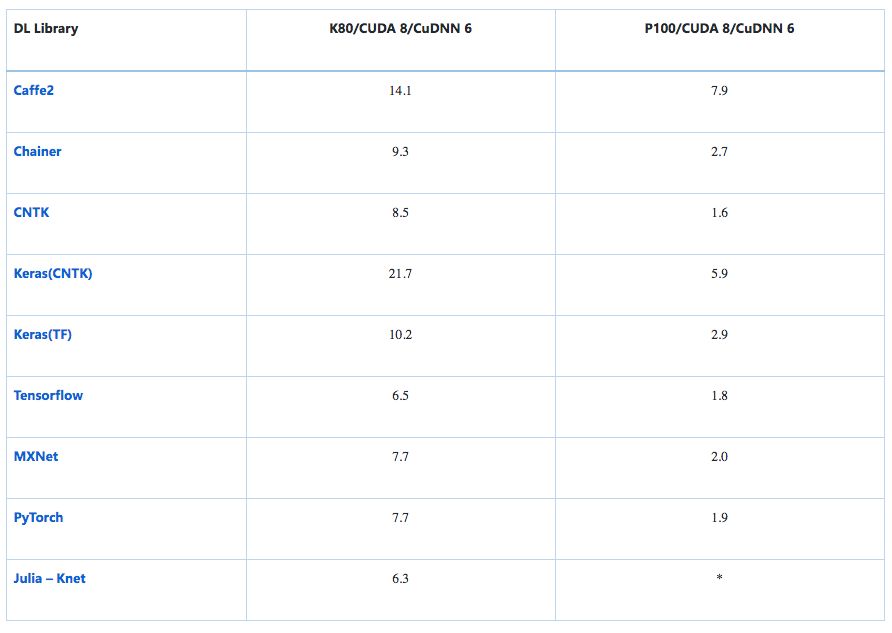
训练时间(秒): RNN (GRU) 在 IMDB --情感分析
该模型的输入是标准的IMDB电影评论数据集,其中包含25k个培训评论和25k个测试评论,统一分为2个类别(正面/负面)。 处理遵循Keras方法,其中起始字符被设置为1,词汇外(词表大小为30k被使用)被表示为2,因此词索引从3开始。零填充/截断到固定轴,每个词150字 评论。
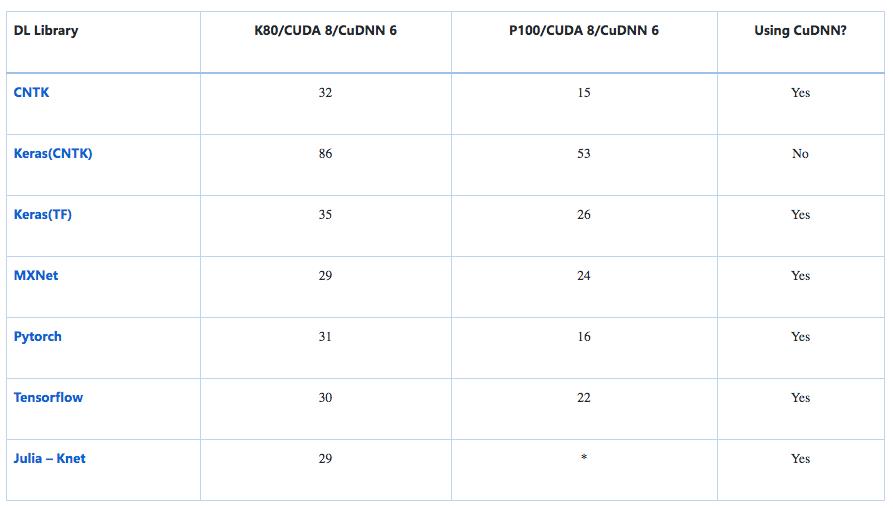
* 这个数据尚未被完全实现,我们欢迎来自社区的补充结果。
经验教训
使用自动调整:大多数框架使用cuDNN的cudnnFindConvolutionForwardAlgorithm()运行穷举搜索并优化用于固定尺寸图像上卷积正向传递的算法。 通常这是默认开启的,但是一些框架可能需要一个flag,例如“torch.backends.cudnn.benchmark=ture”。
尽可能使用cuDNN:对于vanillaRNN(例如GRUs/LSTMs)通常可以调用cuDNN wrapper来提高速度,例如,cudnn_rnn.CudnnGRU()而不是rnn.GRUCell()。 缺点是后期对CPU进行验证时难度可能会增加。
匹配形状:在 cuDNN 上运行时,为 CNN 匹配 NCHW 的原始 channel-ordering、为 RNN 匹配 TNC 可以削减浪费在重塑(reshape)操作上的时间,直接进行矩阵乘法。
原始生成器:使用框架的原始生成器,增强和预处理(例如 shuffling)通过多线程进行异步处理,实现加速。
为了推断,请确保在可能的情况下指定flag以保存正在计算的不必要的梯度,并确保正确应用batch-norm 和 drop-out 。
当我们最初创建repo时,我们使用了许多小技巧和窍门来确保我们以最佳的方式在不同框架之间使用相同的模型运行。过去几个月内框架的发展速度非常快 —框架的更新太快使得2017年末的优化方法已经过时了。
以 TF 为后端的 Keras 拥有 channel-ordering 硬编码作为 channels-last(对于 cuDNN 不是最优的),因此指定channels-first意味着它将重塑后每批(硬编码的值)和极大减缓训练速度。现在TF为后端的Keras支持本地channels-first ordering。Tensorflow之前可以加速通过指定一个flag使用Winograd通过卷积的算法,但是现在这不再是有用的。如果有兴趣,你可以在repo的早期版本中查看一下最初的学习部分。
通过在不同的框架中完成一个端到端解决方案,可以用多种方式对比框架。由于每个框架都使用相同的模型体系结构和数据,因此整个框架的准确性非常相似(实际上,这是我们测试代码的一种方式,以确保不同的框架使用于相同的模型!)另外,notebook的开发是为了框架之间的对比更加容易,而速度并不是必要的。
当然,虽然很容易用速度和推理时间等指标比较不同的框架,但它们并不意味着对框架的整体性能进行评估,因为它们省略了重要的对比,例如:帮助和支持,可用性 预先训练的模型,自定义图层和架构,数据加载器,调试,支持的不同平台,分布式培训等等! 它们仅仅是为了展示如何在不同的框架中创建相同的网络以及这些特定示例的性能。
深度学习框架的“旅行者伴侣”
在社区中有很多流行的深度学习框架,这是帮助AI开发人员和数据科学家在适用的情况下利用不同的深度学习框架。其中一个就是ONNX,它是用于在框架之间传递深度学习模型的开源互操作性标准。例如,ONNX是在想要将其转换为另一个框架中的模型的时候很有用。同样,MMdnn是一组工具,它可帮助用户直接在不同框架之间进行转换,并是模型体系结构可视化。
像ONNX和MMdnn这样的深度学习框架的“旅行者伴侣”就像一台自动机器翻译机。相比之下,我们今天发布的完整版本repo1.0就像是深度学习框架的罗塞塔石碑,它展示了在不同框架中的端到端模型构建过程。所有这些类型的结合起来,可以使旅行者在多种语言的环境中生活。
-— 完 —-
AICAMP(全球AI技术训练营)是专注于AI领域的全球化社区。总部在西雅图硅谷和纽约,社区覆盖美国、加拿大、中国、欧洲、澳大利亚等多地区。社区有超过500多名来自于微软,亚马逊,Google , Facebook, Uber, Twitter, Airbnb, Intel, LinkedIn, Yahoo, Nvidia等团队的顶级技术大咖讲师,全球社区成员超过5万人(美国2万)。和全世界技术人员一起学习和练习AI技术,累计举办超过100多场线下技术沙龙,黑客马拉松, 在线技术讲座和培训,同时向全世界直播。
全球技术学习群
诚挚招聘
以上是关于不甘落后Tensorflow, 微软另辟蹊径发布新型深度学习框架的主要内容,如果未能解决你的问题,请参考以下文章