为什么腾讯监控的大数据平台选择了这款数据库?
Posted 华章计算机
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么腾讯监控的大数据平台选择了这款数据库?相关的知识,希望对你有一定的参考价值。
导读:本文带你了解一个开源的、高性能的时序型数据库——InfluxDB。
从2016年起,笔者在腾讯公司负责QQ后台的海量服务分布式组件的架构设计和研发工作,如微服务开发框架、名字路由、名字服务、配置中心等,做了大量分布式架构、高性能架构、海量服务、过载保护、柔性可用、负载均衡、容灾、水平扩展等方面的工作,以公共组件的形式支撑来自QQ后台和其他BG海量服务的海量流量。
2018年年底,笔者负责监控大数据平台的研发工作,致力于减少现有监控后台成本,以及支撑内部和外部海量监控数据的需求,打造千亿级监控大数据平台。
笔者发现,当前监控技术领域缺乏优秀的监控系统,尤其是在海量监控数据场景中,很多团队常用的做法是堆服务器和堆开源软件,比如大量采用高配置的服务器,单机近百CPU核数、TB内存、数十TB的SSD存储,安装了大量开源软件,如Elasticsearch、Druid、Storm、Kafka、Hbase、Flink、OpenTSDB、Atlas、MongoDB等,但实际效果并不理想。
众多开源软件的组合是在增加了系统的运营成本和数据的处理延迟的情况下解决接入计算,在海量标签和时间序列线情况下,常出现查询超时、数据拉不出来等问题,且成本高昂。
笔者认为,海量或千亿级是整体的量,是个笼统的概念,可以分而治之,通过分集群的方法来解决,海量监控数据的真正挑战在于以下几点:
-
能否做到实时。实时是种质变的能力,可将一个离线监控平台提升为一个实时决策系统。难点在于能否设计实现高性能的架构,以及能否实现水平扩展等。
-
分集群后,单个业务的流量大小、标签集多少是关键。流量大,相对容易解决,主要涉及系统性能和水平扩展等。标签集多,海量标签,海量时间序列线,如何做查询优化是挑战,如笔者遇到的一些业务上报的监控数据,有几十个维度的标签,并将QQ号和URL作为标签值,有非常海量的时间序列线。
-
针对监控数据多写少读、成本敏感的特点,如何设计高效的存储引擎?既能充分发挥硬件性能,又能在高效压缩存储的同时保障查询效率。
为了更好地打造有竞争力的监控系统,我们将技术理念定位为“技术降成本,坚决反对开源软件堆砌”。
-
首先,我们认为云计算是基建,决定它能否成功的关键在于能否在基础技术上突破,打造出相比开源软件更有成本优势的云原生软件;
-
其次,虽然现在开源软件非常繁荣,基于开源软件,我们很容易搭建一个基础系统,将功能跑起来,但绝大部分开源软件侧重的是功能,而不是针对海量监控数据的场景进行设计,或多或少都有其局限性,且成本也非常高昂。
因此我们要做的是借助强大的技术和工程能力,直面问题,在架构和源码层面解决它,而不是引入和堆砌更多的开源软件。
出于工程效率的考虑,我们选择基于开源软件进行二次开发,使用开源软件的部分代码,按照我们的想法进行架构设计和功能开发。在对众多的开源软件进行调研分析后,我们最终选择了以InfluxDB源码为基础进行二次开发。
之所以选择InfluxDB源码,主要是因为我们对InfluxDB源码背后的技术和工程实力比较认可。InfluxDB研发团队能真正解决海量监控数据场景的问题,也是在认真地打造一款优秀的监控产品(出于读写性能和可用性的考虑,InfluxDB研发团队曾2次重构存储引擎)。
在笔者着手以InfluxDB源码为基础开发集群等功能时,业界还没有团队实现了真正可用的InfluxDB集群能力。一些团队只是通过Proxy实现了负载均衡,却无法突破单机接入计算和存储的限制,缺乏一致性能力。
有些团队在对InfluxDB进行了多年的学习和研究后,最终考虑到基于时序分片的复杂度而放弃了基于InfluxDB开发集群能力,转而选择基于RocksDB、Zookeeper等开源软件进行自建。
笔者在3个月内快速开发出了CP和AP架构分离、时序分片、水平扩展等基本集群能力,另外,根据业务的特点,在索引引擎、冷热分离、查询实现、第三方协议、高可用性、可运营性等方面也做了大量的工作。
最终的效果也是符合预期的,如从替换现有监控系统后台的实施对比来看,我们用了不到10%的机器成本就支撑起原监控后台所支撑的海量监控数据,成本优势突出。
InfluxDB是一款非常优秀的软件,直接推动监控技术进入了实时、纳秒级的新时代,除了类SQL查询语言、RESTful API等现代特性外,还具有读写性能高、存储压缩率高、生态丰富、功能强大等特性。
InfluxDB是一个开源的、高性能的时序型数据库,在时序型数据库DB-Engines Ranking上排名第一。
在介绍InfluxDB之前,先来介绍下时序数据。按照时间顺序记录系统、设备状态变化的数据被称为时序数据(Time Series Data),如CPU利用率、某一时间的环境温度等。
时序数据以时间作为主要的查询纬度,通常会将连续的多个时序数据绘制成线,制作基于时间的多纬度报表,用于揭示数据背后的趋势、规律、异常,进行实时在线预测和预警,时序数据普遍存在于IT基础设施、运维监控系统和物联网中。
时序型数据库是存放时序数据的专用型数据库,并且支持时序数据的快速写入、持久化、多纬度的实时聚合运算等功能。
传统数据库通常记录数据的当前值,时序型数据库则记录所有的历史数据,在处理当前时序数据时又要不断接收新的时序数据,同时时序数据的查询也总是以时间为基础查询条件,并专注于解决以下海量数据场景的问题:
-
-
时序数据的读取:如何支持千万级/秒数据的聚合和查询。
-
成本敏感:海量数据存储带来的是成本问题,如何更低成本地存储这些数据,是时序型数据库需要解决的关键问题。
InfluxDB是一个由InfluxData公司开发的开源时序型数据库,专注于海量时序数据的高性能读、高性能写、高效存储与实时分析,在DB-Engines Ranking时序型数据库排行榜上位列榜首,广泛应用于DevOps监控、IoT监控、实时分析等场景。
具体的DB-Engines Ranking时序型数据库的排行榜(源自2019年5月的DB-Engines Ranking数据)如图1-1所示。
-
InfluxDB部署简单、使用方便,在技术实现上充分利用了Go语言的特性,无须任何外部依赖即可独立部署;
-
提供类似于SQL的查询语言,接口友好,使用方便;拥有丰富的聚合运算和采样能力;
-
提供灵活的数据保留策略(Retention Policy)来设置数据的保留时间和副本数;
-
在保障数据可靠性的同时,及时删除过期数据,释放存储空间;
-
提供灵活的连续查询(Continuous Query)来实现对海量数据的采样。
-
支持多种通信协议,除了HTTP、UDP等原生协议,还兼容CollectD、Graphite、OpenTSDB、Prometheus等组件的通信协议。
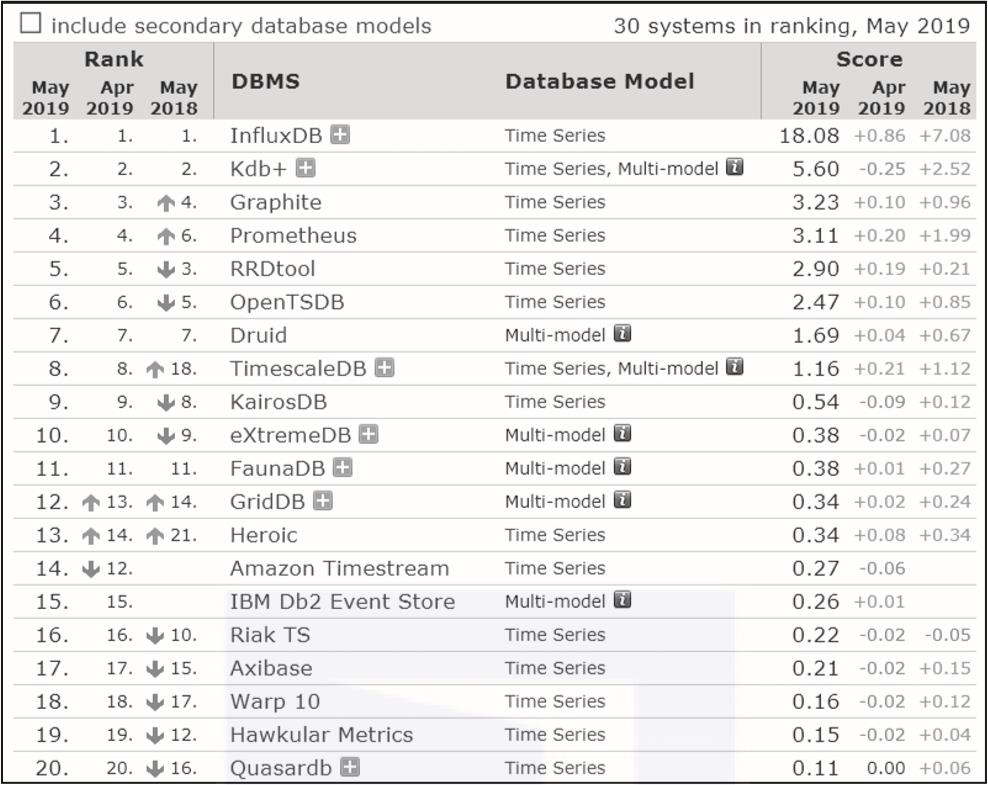
▲图1-1 时序型数据库DB-Engines Ranking排名
讲到InfluxDB,就不能不提InfluxData的开源高性能时序中台TICK(Telegraf + InfluxDB + Chronograf + Kapacitor),InfluxDB是作为TICK的存储系统进行设计和开发的。
TICK专注于DevOps监控、IoT监控、实时分析等应用场景,是一个集成了采集、存储、分析、可视化等能力的开源时序中台,由Telegraf、 InfluxDB、Chronograf、Kapacitor 4个组件以一种灵活松散但紧密配合、互为补充的方式构成,各个模块相互配合、互为补充,整体系统架构如图1-2所示。
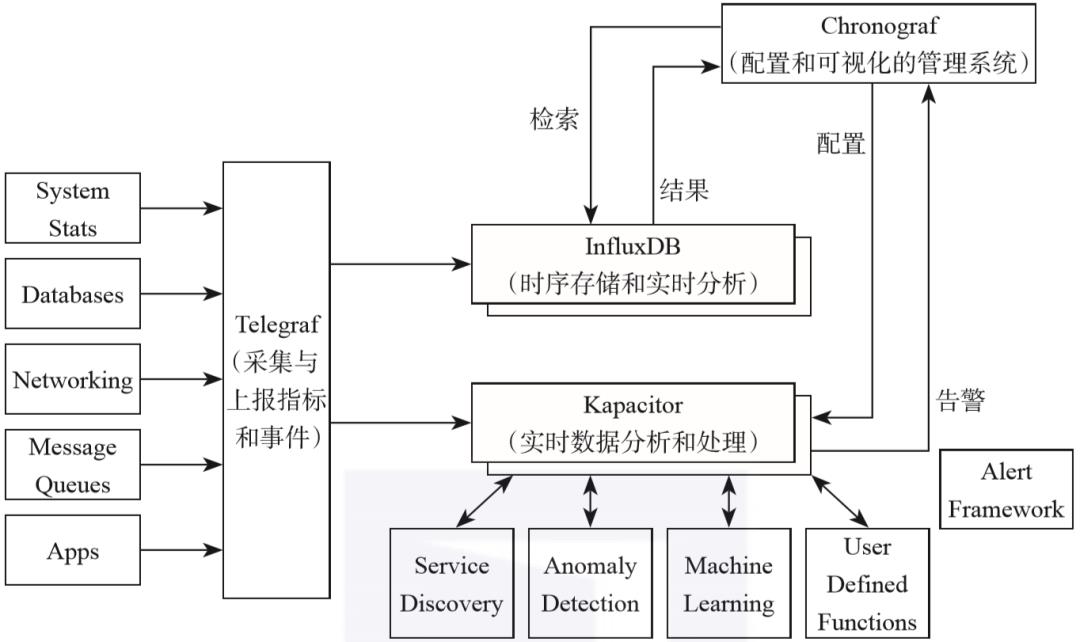
Telegraf是用于采集和上报指标的数据采集程序,采用灵活的、可配置的插件实现。
Telegraf可以通过配置文件的配置,采集当前运行主机的指定指标,如CPU负载、内存使用等,也可以从第三方消费者服务(如StatsD、Kafka等)拉取数据,上报到已支持的多种存储系统、服务或消息队列,如InfluxDB、Graphite、OpenTSDB、Datadog、Librato、Kafka、MQTT、NSQ等。
InfluxDB是专注于时序数据场景(如DevOps监控、IoT监控、实时分析等)的高性能时序型数据库,支持灵活的自定义保留策略和类SQL的操作接口。
Chronograf是可视化的、BS架构的管理系统,可用于配置和管理接收到的监控数据、告警,并支持通过灵活强大的模块和库,快速配置数据可视化仪表盘、告警规则、可视化规则。
Kapacitor是从零构建的原生数据处理引擎,支持流式处理和批量处理,支持灵活强大的自定义功能,如定义新的告警阈值、告警指标特征、告警统计异常特征等,以及后续的告警处理行为。
除了灵活,Kapacitor也很开放,能灵活地集成对接第三系统,如HipChat、OpsGenie、Alerta、Sensu、PagerDuty、Slack等。

存储和分析时序数据的时序型系统并不鲜见,自计算机问世以来,我们一直在数据库中存储时序数据。
最初,使用通用存储系统存储时序数据,如mysql。第一代时序平台,如KDB +、RRDtool、Graphite等,在20年前就推出了,主要用于存储和分析数据中心的时序数据,以及高频金融数据、股票波动率等。
根据DB-Engines等数据库趋势跟踪和行业分析网站发布的信息,时序型数据库是数据库市场中份额增长最快的部分。原因很明显,计算机虚拟世界,如数据库、网络、容器、系统、应用程序等,和物理世界,如家用设备、城市基础设施、工厂机器、电力设施等,正在创建海量的时序数据。
现在更多的企业会通过时序存储和数据分析来获得预测能力和实时决策能力,从而为客户提供更好的使用体验。这意味着底层数据平台需要发展以应对新的工作负载的挑战,以及更多的数据点、数据源、监控维度、控制策略和精度更高的实时响应,对下一代时序中台提出了更高的要求,具体如下所示。
-
专为时序存储和高性能读写而设计:计算机虚拟世界的各种系统和应用,以及物理世界的IoT设备等都在创建海量的时序数据,每秒千万级的数据吞吐量是很常见的,而且这些数据还需要可以以非阻塞方式接收并且可压缩以节省有限的存储资源。
-
专为实时操作而设计:预测能力和实时决策能力,需要收到数据后,就能实时输出最新的数据分析结果,执行预定义的操作。
-
专为高可用性而设计:现代软件系统需要全天候可用,除了基本的集群能力,还需要根据需求自动扩容和缩容,支持柔性可用等。
InfluxData选择从头开始构建InfluxDB以支持下一代时序中台的需求,InfluxDB通过实现高度可扩展的数据接收和存储引擎,可以高效地实时收集、存储、查询、可视化显示和执行预定义操作。它通过连续查询提升查询效率和缩短延迟,通过数据保留策略,及时高效地删除过期冷数据,提升存储效率。
为什么通用数据库在时序场景上不是最优的选择呢?许多通用数据库正在为时序数据添加一些支持,虽然可能很容易使用,但它们基本上都不是针对海量时序数据的吞吐量和实时操作而设计的。
与InfluxDB相比,通用数据库,如Cassandra、MongoDB、HBase等,需要开发人员投入大量的时间进行代码编写,以开发与InfluxDB类似的功能。具体来说,开发人员需要做如下工作:
-
编写代码实现跨集群数据分片功能、聚合运算和采样功能、数据生命周期管理功能等。
-
-
-
-
为了让读者对InfluxDB的优势有个直观的认识,接下来,会把InfluxDB和其他被用作时序存储的系统(如ElasticSearch、MongoDB、OpenTSDB)做简要的对比:
1. InfluxDB vs ElasticSearch
ElasticSearch是专为搜索而设计的系统,是实现搜索功能的绝佳选择。
然而,对于时序数据,却并非如此。在处理时序数据时,InfluxDB的性能远远超过ElasticSearch系统,对于写入吞吐量,InfluxDB通常优于ElasticSearch 5~10倍,具体差值取决于架构。对于特定时序的查询速度,使用ElasticSearch比使用InfluxDB要慢5~100倍,具体差值取决于查询的时间范围。
最后,如果需要存储原始数据以便稍后查询,则ElasticSearch上的硬盘占用比InfluxDB大10~15倍。如果先汇总数据再存储,ElasticSearch的硬盘占用比InfluxDB大3~4倍。综合来看,ElasticSearch非常适合进行搜索,但不适用于时序存储和实时分析。
MongoDB是一个开源的、面向文档的数据库,俗称NoSQL数据库,用C和C ++语言编写。虽然它通常不被认为是真正的时序型数据库(TSDB),但它经常被用作时序存储系统。它以时间戳和分组的形式提供建模原语,使用户能够存储和查询时序数据。
MongoDB旨在存储“无模式”数据,其中每个对象可能具有不同的结构。实际上,MongoDB通常用于存储内容大小可变的JSON或BSON对象。由于其采用通用性和无模式数据存储区设计,MongoDB无法利用时序数据的高度结构化特性。
需要特别指出的是,时序数据由标签(键/值串对)和时间戳组成,这时必须对MongoDB做专门配置以支持时序数据,但这样做效率很低。
相比MongoDB,InfluxDB的性能和成本优势明显,InfluxDB的写性能大约是MongoDB的2.4倍,存储效率大约是MongoDB的20倍,查询效率大约是MongoDB的5.7倍。综合来看,MongoDB非常适合文档和自定义对象,但不适用于大规模的时序数据和实时分析。
OpenTSDB是一个可扩展的分布式时序型数据库,用Java语言编写,构建在HBase之上。它最初是由Benoît Sigoure于2010年开始编写的,并在LGPL下开源。
OpenTSDB不是一个独立的时序型数据库,相反,它依赖HBase作为其数据存储层,因此OpenTSDB时序守护进程(OpenTSDB中的TSD用语)在实例之间没有共享状态可以高效地提供查询引擎的功能。
OpenTSDB允许通过其API进行简单的聚合和数学运算,但没有完整的查询语言。OpenTSDB支持毫秒的分辨率,但随着亚毫秒级操作的普及,OpenTSDB有时会出现精度不足的问题。
相比OpenTSDB,InfluxDB的性能和成本优势明显,InfluxDB的写性能大约是OpenTSDB的5倍,存储效率大约是OpenTSDB的16.5倍,查询效率大约是OpenTSDB的3.65倍。
另外,OpenTSDB的设计初衷主要是用于生成仪表板图,不是为了满足任意查询,也不是为了存储数据。这些限制会影响它的使用方式。

作为一个开源系统,InfluxDB究竟有什么魅力吸引了如此多的用户,从而在时序型数据库DB-Engines Ranking上排名第一呢?
InfluxDB是支持时序数据高效读写、压缩存储、实时计算能力的数据库服务,除了具有成本优势的高性能读、高性能写、高存储率,InfluxDB还具有如下特点:
-
-
无模式(schema-less)的数据模型,灵活强大。
-
-
-
-
丰富的时效管理功能:自动删除过期数据,自定义删除指标数据。
-
-
丰富的聚合函数,支持AVG、SUM、MAX、MIN等聚合函数。
InfluxDB实现了类SQL的接口,尽管与传统关系型数据库(如MySQL)语法相似,但InfluxDB在语义体系上有些差别,接下来将以一条CPU利用率的时序数据为例介绍相关的核心概念,如代码清单1-3所示。
> insert cpu_usage,host=server01,location=cn-sz user=23.0,system=57.0
> select * from cpu_usage
name: cpu_usage
time host location system user
---- ---- -------- ------ ----
1557834774258860710 server01 cn-sz 55 25
>
-
时间(Time):如代码清单1-3中的“1557834774258860710”,表示数据生成时的时间戳,与MySQL不同的是,在InfluxDB中,时间几乎可以看作主键的代名词。
-
表(Measurement):如代码清单1-3中的“cpu_usage”,表示一组有关联的时序数据,类似于MySQL中表(Table)的概念。
-
标签(Tag):如代码清单1-3中的“host=server01”和“location=cn-sz”,用于创建索引,提升查询性能,一般存放的是标示数据点来源的属性信息,在代码清单1-3中,host和location分别是表中的两个标签键,对应的标签值分别为server01和cn-sz。
-
指标(Field):如代码清单1-3中的“user=23.0”和“system=57.0”,一般存放的是具体的时序数据,即随着时间戳的变化而变化的数据,与标签不同的是,未对指标数据创建索引,在代码清单1-3中,user和system分别是表中的两个指标键,对应的指标值分别为23.0和57.0。
-
时序数据记录(Point):如代码清单1-3中的“1557834774258860710 server01 cn-sz 55 25”,表示一条具体的时序数据记录,由时序(Series)和时间戳(Timestamp)唯一标识,类似于MySQL中的一行记录。
-
保留策略(Retention Policy):定义InfluxDB的数据保留时长和数据存储的副本数,通过设置合理的保存时间(Duration) 和副本数(Replication),在提升数据存储可用性的同时,避免数据爆炸。
-
时间序列线(Series):表示表名、保留策略、标签集都相同的一组数据。
关于作者:
韩健,资深架构师,现就职于腾讯,担任监控大数据平台技术负责人,曾先后担任创业公司CTO、Intel资深工程师。既对分布式系统、InfluxDB的架构设计和开发有深刻的理解,又在海量服务分布式组件架构设计、高性能架构设计、高质量代码编写等方面有深厚的积累,经验丰富。
本文摘编自《InfluxDB原理与实战》,经出版方授权发布。
