大数据进阶之Spark计算运行流程
Posted 加米谷学院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据进阶之Spark计算运行流程相关的知识,希望对你有一定的参考价值。
在大数据的诸多技术框架当中,Spark发展至今,已经得到了广泛的认可。Hadoop与Spark可以说是企业级数据平台的主流选择,基于不同的应用场景,来搭建符合需求的大数据系统平台。今天我们就来讲讲其中的Spark,Spark核心运行流程。
Spark计算模式
Spark是既Hadoop之后提出的又一代计算框架,同样主打离线批处理,但是在Hadoop原生计算引擎MapReduce的基础之上,做到了性能提升10-100倍,从而在Hadoop生态当中,超过了原生的MapReduce,逐步得到重用。
Spark继承了Hadoop MapReduce的特性,是典型的Master/worker架构。这种架构就是把计算任务进行划分,然后进行分配给多个Slave,也就是进行Map,等Slave完成了分配给自己的任务后,然后再Master上进行汇总,也就是Redudce,这就是MapReduce的思想。
Spark运行流程
Spark在Master上创建Spark context,创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等。
Driver是驱动的意思,也就是整个系统启动之后,整个系统的运转时靠Driver来驱动的,用户自己的作业也是通过Driver来分解和调度运行的。
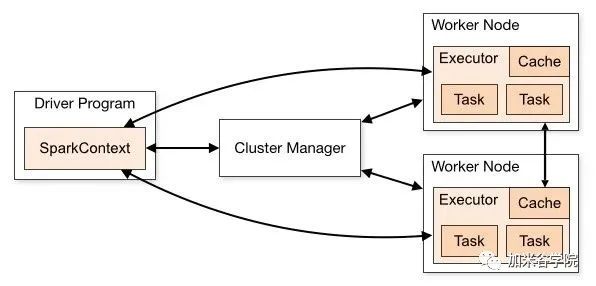
Executor向Driver注册自己之后,大家就相互认识了,就可以互相通信,根据协议进行交互,整个分布式系统也就运行起来了。
Driver和Executor直接通过RPC协议相互联系,Spark历史上内部使用过两种RPC实现,基于Akka Actor的RPC和基于Netty自己封装的RPC。
Executor是具体的执行者,Executor拿到属于自己的Task后,运行出结果,然后把结果汇报给Driver。
Driver和Executors都运行自己的Java进程,可以在同一台机器上,也可以在不同的机器上。
Spark资源管理
而关于资源管理器,有多种选择。可以是Spark自己实现的资源管理器,standalone模式,也可以采用一些比较通用的资源管理器,比如Yarn和Mesos,这也是为什么有说法,Spark可以自己独立运行,也可以与Hadoop集成协同。
关于大数据进阶之Spark运行流程,相信看完今天的分享内容,大家也都能够有比较清楚的认识了。Spark是大数据当中必须掌握的核心技术框架,对于运行原理、架构设计等,都需要牢牢掌握,熟练运用才行。
成都加米谷学院
个人技能提升 丨 企业内训提升
成都高新区吉泰一街国际科技节能大厦B座23层
以上是关于大数据进阶之Spark计算运行流程的主要内容,如果未能解决你的问题,请参考以下文章
Spark大数据之深度理解RDD的内在逻辑(5000字案例干货!)