DT大数据梦工厂第三十五课 Spark系统运行循环流程
Posted sinat_25306771
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DT大数据梦工厂第三十五课 Spark系统运行循环流程相关的知识,希望对你有一定的参考价值。
本节课内容:
1. TaskScheduler工作原理
2. TaskScheduler源码
一、TaskScheduler工作原理
总体调度图:
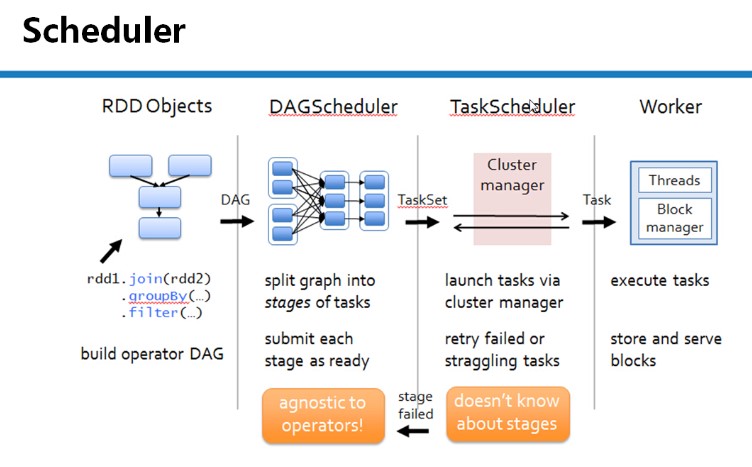
通过前几节课的讲解,RDD和DAGScheduler以及Worker都已有深入的讲解,这节课我们主要讲解TaskScheduler的运行原理。
回顾:
DAGScheduler面向整个Job划分多个Stage,划分是从后往前的回溯过程;运行时从前往后运行的。每个Stage中有很多任务Task,Task是可以并行执行的。它们的执行逻辑完全相同的,只不过是处理的数据不同而已,DAGScheduler通过TaskSet的方式,把其构造的所有Task提交给底层调度器TaskScheduler。
& TaskScheduler是一个trait,与具体的资源调度解耦合,这符合面向对象中依赖抽象不依赖具体的原则,带来底层资源调度器的可插拔性,导致Spark可以运行的众多的资源调度模式上,例如:StandAlone、Yarn、Mesos、Local、EC2或者其他自定义的资源调度器。
以上是关于DT大数据梦工厂第三十五课 Spark系统运行循环流程的主要内容,如果未能解决你的问题,请参考以下文章