canal同步MQ配置
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了canal同步MQ配置相关的知识,希望对你有一定的参考价值。
参考技术A 第一步:canal原理是把自己伪装成一个mysql的从节点来读取mysql主库的binlog日志。
所以需要mysql主库先开启binlog日志功能。可以参考其他帖子打开binlog功能。
ps!!!!! 这里有一个非常值得注意的问题就是canal采集到MQ数据中使用的是binlog的的row模式
一定要是row模式。并且canal中配置canal.instance.filter.regex 如果配制指定采集某几个表一定要在mysql中配置binlog_rows_query_log_events是OFF模式的。否则canal中的canal.instance.filter.regex过滤器不生效。
第二步:
canal服务解压之后
其中canal_local.properties是canal控制台配置文件
canal.properties 是canal基础服务配置文件
ht_order_sync文件夹 是canal的服务实例
ht_product_sync文件夹 是canal的服务实例
上面这些是比较关键的文件
其中ht_order_sync 和 ht_product_sync 是我自己创建的文件名字可以随便叫什么都可以
如果是全新的canal解压之后 有一个example文件那个就是样例文件。
我创建了 ht_order_sync 和 ht_product_sync 是因为我有两个业务需求是 同步订单业务 和 商品业务 所以创建了两个实例,canal启动之后会加载自己创建的文件夹。
cd 进入 ht_order_sync文件夹后 如下图
我们一般需要改的只有 instance.properties 这个文件。其他文件是记录binlog的同步位置的文件。删除之后就重置binlog的采集位置,所以不要轻易删除。
下面打开instance.properties 如下图
图中
1 是要采集的mysql的账号和密码
2 是要采集的哪张表可以配置全部也可以配置部分我是配置了部分表可以直接写库和表名,我库名用了变量后面讲怎么传进来的
3 是黑明单结合上面那个白名单用的 我固定了采集某几张表所以不要配置
4 是采集的每一行的变动会发送到配置的mq的topic中作为mysql的一条改动数据(增删改)
mq数据如下图会包含改动前和改动后的数据表名库名等等。
上图是我做的一个insert的样例数据,type类型就是insert,还有update和delete 有字段类型描述
old 是改动前的数据 因为insert 操作所以是null 如果是update操作此处会有值 可以做变更监听逻辑
data是当前改动后的数据。
上面说的都是具体实例配置
下面贴出canal的实例上层配置文件也就是canal服务配置文件 canal.properties
如下图. 一张图截图放不下放了三张图
图上编号
1 是代表canal采集到信息推送到哪里。tcp是代表可以推送到程序采集模式
如果是mq配置成对应的mq比如 kafka活着rocketmq等等
2 是canal.destinations 扫描上面说的自己创建的实例 配置几个文件夹扫描几个
canal.auto.scan = true 的意思是自动扫描自己创建的实例。
所以应该可以把canal.auto.scan 配置成false然后配置canal.destinations自己创建的文件夹
即可
3 canal.mq.flatMessage = true
关注一下
采集的消息的消息方式之前好像不设置成true没采集到,已经忘了 也需要配置 mq读取 也使用这个方式。 可以参考一下官网等等。
4 配置成了rocketMQ那么就配置 相关的主题等等
结束
用canal同步binlog到kafka,spark streaming消费kafka topic乱码问题
canal 1.1.1版本之后, 默认支持将canal server接收到的binlog数据直接投递到MQ, 目前默认支持的MQ系统有kafka和RocketMQ。
在投递的时候我们使用的是非压平的消息模式(canal.mq.flatMessage =false //是否为flat json格式对象),然后消费topic的时候就一直无法正常显示和序列化,通过kafka-console-consumer.sh命令收到的消息如下图
在github上也能找到相关问题
canal-kafka 数据同步到kafka之后,kafka topic乱码:https://github.com/alibaba/canal/issues/898
canal.kafka 用bin/kafka-console-consumer.sh命令收到乱码:https://github.com/alibaba/canal/issues/1013
在非flatmessage模式下向kafka数据投递传输的是数据包,收到数据后还要解包成对应的message,可参考canal client中的kafka实现, github地址为 https://github.com/alibaba/canal/tree/master/client/src/main/java/com/alibaba/otter/canal/client/kafka
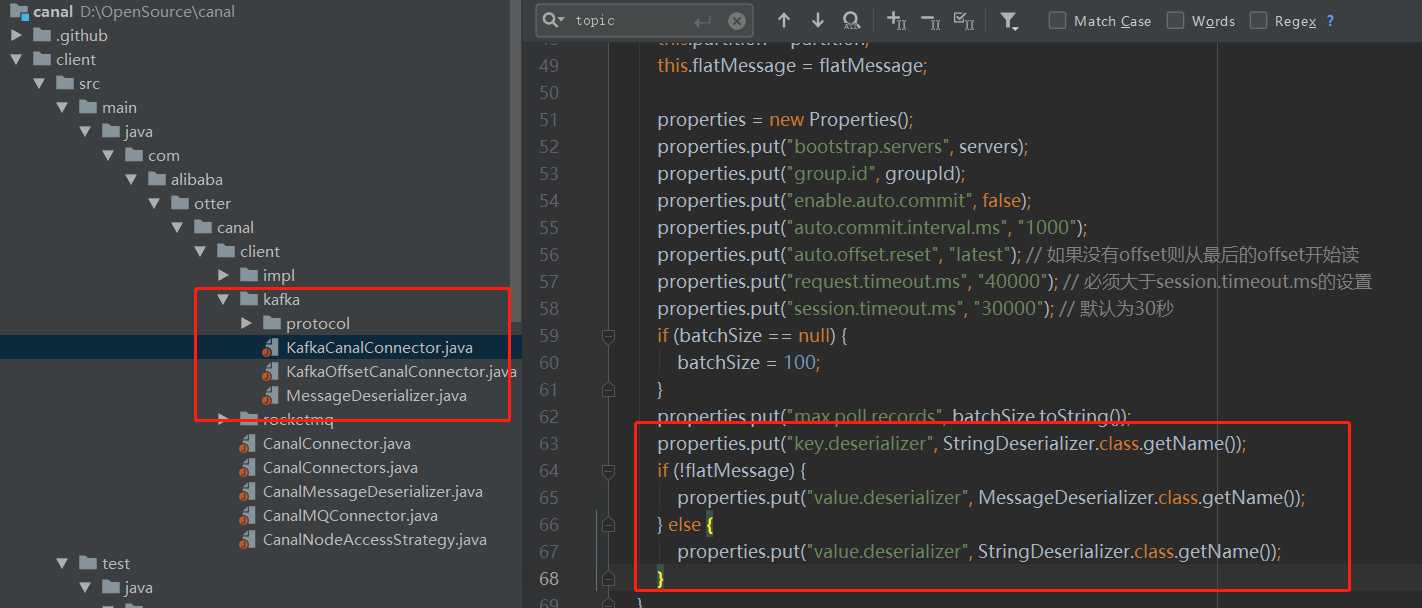
打开连接后 kafkaConsumer = new KafkaConsumer<String, Message>(properties);
参考这种操作只是简单的kafka能够收消息,结合spark streaming收消息也差不多。
在kafkaparam中设置key和value的反序列化方式
"key.deserializer" -> classOf[StringDeserializer].getName
"value.deserializer" -> classOf[MessageDeserializer].getName
在拉取消息的时候设置接受格式为Array[Byte]
val messages = KafkaUtils.createDirectStream[String, Array[Byte], StringDecoder, DefaultDecoder](ssc, kafkaParams, topics)
在处理每个RDD的时候再对内容进行反序列化:
val parData = rdd.mapPartitions(t => {
val mesDesc = new MessageDeserializer
var list = List[consumerUser]()
while (t.hasNext) {
try {
val value = t.next()._2
val message = mesDesc.deserialize("", value)
//val listMaps = CanalParse.parseData(message)
//逻辑
} catch {
case e: Exception => log.error(e)
}
}
list.iterator
})
这样就拿到了message对象。
依赖jar包
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.3</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.8.2.1</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.kafka.client</artifactId>
<version>1.1.0</version>
</dependency>
以上是关于canal同步MQ配置的主要内容,如果未能解决你的问题,请参考以下文章