系统重构数据同步利器之Canal实战篇
Posted 浅谈架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统重构数据同步利器之Canal实战篇相关的知识,希望对你有一定的参考价值。
二话不说,先上图

上图来自于官网(https://github.com/alibaba/canal),基本上涵盖了目前生产环境使用场景了,众所周知,Canal做数据同步已经是行业内标杆了。我们生产环境也用Canal监听binlog数据变更,然后解析成对应数据发送到MQ(RocketMQ)。一些非主流程业务,异步场景消费MQ处理即可。
但是我这篇文章,主要想聊一聊在做系统重构时,新老系统数据双向同步时Canal的使用场景。
注:关于系统重构的介绍我这里就不叙述了,大家可以看我之前写的系列文章:浅谈系统重构
二、关于双向同步什么是双向同步?
所谓双向同步,就是老系统数据库数据往新系统数据库同步,新系统数据库同时也往老系统数据库同步。从而保证新系统,老系统数据库数据完全一致。系统重构时如果上线出现问题,随时能切回原来老系统,这也为灰度方案提供了底层保障。
一般同步如何做?各自优缺点是什么?
方案一: Dao层拦截方案
方案说明: 在Dao层打洞拦截所有写请求(insert,update,delete), 然后写入MQ队列,再通过消费MQ队列写入对应数据库。
优点: 这种方案实现比较简单。
缺点: 对于老系统数据库,可能有很多个服务在写入,如果从Dao层拦截,可能要修改很多地方,改动较大。
方案二: 利用Canal订阅解析Binlog
方案说明: 利用Canal订阅Binlog,解析成数据,再写入到对应数据库(这里可以直接写入,也可以先写入MQ,再消费MQ写入,推荐后者)。
优点:能够解决系统多处写入问题。
缺点:引入新的组件Canal,复杂度增加。
下面,我们就来实战操作一下方案二。
三、环境准备(Centos系统为例)1. 安装mysqlwget https://dev.mysql.com/get/mysql80-community-release-el8-1.noarch.rpm
yum install mysql80-community-release-el8-1.noarch.rpm
#禁用centos自带的mysql
yum module disable mysql -y
#安装
yum install mysql-community-server -y
#启动
systemctl start mysqld
#查看启动状态 提升 Active: active (running) 表示成功
systemctl status mysqld
#查看初始密码
grep \'temporary password\' /var/log/mysqld.log
#初始密码登录
mysql -uroot -p\'AXXXXX\' -hlocalhost -P3306
#修改ROOT密码
ALTER USER \'root\'@\'localhost\' IDENTIFIED BY \'BXXXXX\';
1)、查看当前mysql是否开启了binlog模式, 如果log_bin的值为OFF是未开启,为ON是已开启 。
SHOW VARIABLES LIKE \'%log_bin%\'
2)、若未开启需要修改/ect/my.cnf 开启binlog模式
[mysqld]
log-bin=mysql-bin
binlog-format=ROW
server_id=1
修改完之后重启mysql服务
3)、创建用户并且授权
create user canal@\'%\' IDENTIFIED by \'XXXX\';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO \'canal\'@\'%\';
FLUSH PRIVILEGES;
1)、canal下载地址
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
2)、解压到指定目录
mkdir canal-server-1.1.4
tar -zxf canal.deployer-1.1.4.tar.gz -C canal-server-1.1.4/
3)、修改配置文件 查看主库 binlog position
mysql> show master status;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000002 | 4526 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
修改配置文件 conf/example/instance.properties
# position info
canal.instance.master.address=IP:3306
# 这里对应上面的File
canal.instance.master.journal.name=binlog.000002
# 这里对应上面的Position
canal.instance.master.position=4526
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=XXXX
4)、启动 canal-server
./bin/startup.sh
# 查看日志
tail -f logs/example/example.log
以上就完成了Canal-Server的单实例版本实现,生成环境集群环境一般是运维搭建,我们测试就用单实例版本。
关于Canal的HA机制设计下面简单介绍下,生产环境推荐使用。
canal的HA分为两部分,canal server和canal client分别有对应的HA实现
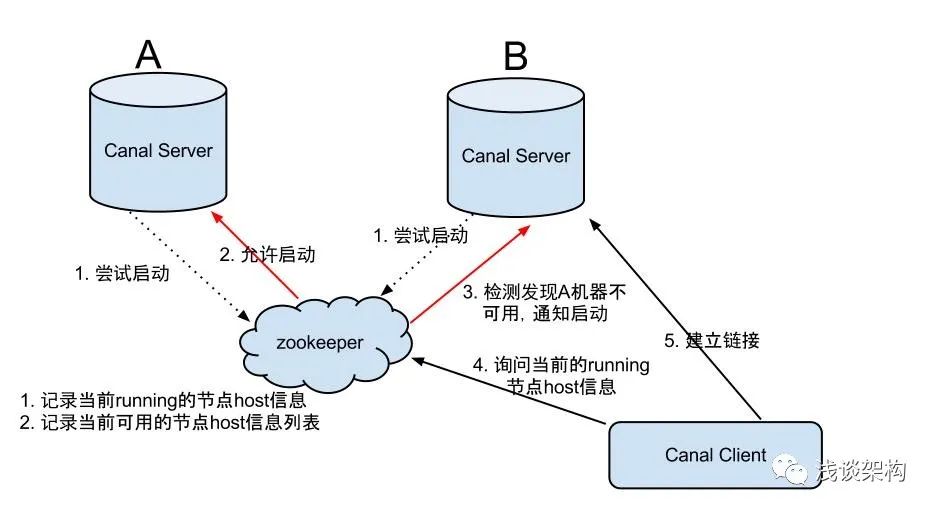
canal server:
为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态.
canal client:
为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。整个HA机制的控制主要是依赖了zookeeper的几个特性,watcher和EPHEMERAL节点(和session生命周期绑定),这里就不展开介绍了,有兴趣的同学可以看下官方wiki。
四、演示环节由于canal组件封装的代码太多,我花了几个晚上业余时间写的(请点个赞吧),代码已经开源至gitee,有需要的同学可以clone下来看。
gitee地址: https://gitee.com/bytearch/fast-cloud
目前已支持simple直连模式和zookeeper集群模式
下面演示canal-client-demo
新建库order_center ,并且创建表order_info
CREATE TABLE `order_info` (
`order_id` bigint(20) unsigned NOT NULL,
`user_id` int(11) DEFAULT \'0\' COMMENT \'用户id\',
`status` int(11) DEFAULT \'0\' COMMENT \'订单状态\',
`booking_date` datetime DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`order_id`),
KEY `idx_user_id` (`user_id`),
KEY `idx_bdate` (`booking_date`),
KEY `idx_ctime` (`create_time`),
KEY `idx_utime` (`update_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;添加处理器handler
@CanalHandler(value = "orderInfoHandler", destination = "example", schema = "order_center", table = "order_info", eventType = CanalEntry.EventType.UPDATE, CanalEntry.EventType.INSERT,CanalEntry.EventType.DELETE)
public class OrderHandler implements Handler<CanalEntryBO>
@Override
public boolean beforeHandle(CanalEntryBO canalEntryBO)
if (canalEntryBO == null)
return false;
return true;
@Override
public void handle(CanalEntryBO canalEntryBO)
//1. 更新后数据解析
OrderInfoDTO orderInfoDTO = CanalAnalysisUti.analysis(OrderInfoDTO.class, canalEntryBO.getRowData().getAfterColumnsList());
System.out.println("event:" + canalEntryBO.getEventType());
System.out.println(orderInfoDTO);
//2. 后续操作 TODO
添加配置
canal:
clients:
simpleInstance:
enable: true
mode: simple
servers: XXXXX:11111
batchSize: 1000
destination: example
getMessageTimeOutMS: 500
#zkInstance:
# enable: true
# mode: zookeeper
# servers: 172.30.1.6:2181,172.30.1.7:2181,172.30.1.8:2181
# batchSize: 1000
# #filter: order_center.order_info
# destination: example
# getMessageTimeOutMS: 500配置说明:
public class CanalProperties
/**
* 是否开启 默认不开启
*/
private boolean enable = false;
/**
* 模式
* zookeeper: zk集群模式
* simple: 简单直连模式
*/
private String mode = "simple";
/**
* canal-server地址 多个地址逗号隔开
*/
private String servers;
/**
* canal-server 的destination
*/
private String destination;
private String username = "";
private String password = "";
private int batchSize = 5 * 1024;
private String filter = StringUtils.EMPTY;
/**
* getMessage & handleMessage 的重试次数, 最后一次重试会ack, 之前的重试会rollback
*/
private int retries = 3;
/**
* getMessage & handleMessage 的重试间隔ms
* canal-client内部代码 的重试间隔ms
*/
private int retryInterval = 3000;
private long getMessageTimeOutMS = 1000;
测试insert和update操作
mysql> insert into order_info(order_id,user_id,status,booking_date,create_time,update_time) values(6666666,6,10,"2022-02-19 00:00:00","2022-02-19 00:00:00", "2022-02-19 00:00:00");
Query OK, 1 row affected (0.00 sec)
mysql> update order_info set status=20 where order_id=66666;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 0 Changed: 0 Warnings: 0
mysql>测试结果
2022-02-18 19:29:52.399 INFO 47706 --- [ lc-work-thread] c.b.s.canal.cycle.SimpleCanalLifeCycle :
****************************************************
* Batch Id: [11] ,count : [3] , memsize : [189] , Time : 2022-02-18 19:29:52.399
* Start : [binlog.000003:18893:1645183792000(2022-02-18 19:29:52.000)]
* End : [binlog.000003:19123:1645183792000(2022-02-18 19:29:52.000)]
****************************************************
2022-02-18 19:29:52.405 INFO 47706 --- [ lc-work-thread] c.b.s.canal.cycle.SimpleCanalLifeCycle :
----------------> binlog[binlog.000003:19056] , name[order_center,order_info] , eventType : INSERT ,tableName : order_info, executeTime : 1645183792000 , delay : 400ms
event:INSERT
OrderInfoDTOorderId=6666666, userId=6, status=10, bookingDate=2022-02-19 00:00:00, createTime=2022-02-19 00:00:00, updateTime=2022-02-19 00:00:00大功告成,到这一步就顺利完成了Canal订阅解析binlog步骤。
抛下两个问题大家可以思考下
数据双向同步时,如何解决数据回环问题?
例如新系统产生的数据,同步到老系统,不能又回流到新系统,如何解决?
数据顺序问题,如果写入到MQ,是否要保证顺序消费?如何实现?
当同步并发比较大,如何提高同步速度。
温馨提示: 此专题未完,以上问题我将在下一篇文章《系统重构数据同步利器之Canal实战篇-续》实现,大家可以提前思考一下。
六、 号外欢迎大家关注”浅谈架构“ 公众号,不定期分享原创文章
有任何问题,欢迎私信我交流。
Canal增量数据同步利器介绍与安装
文章目录
Canal增量数据同步利器
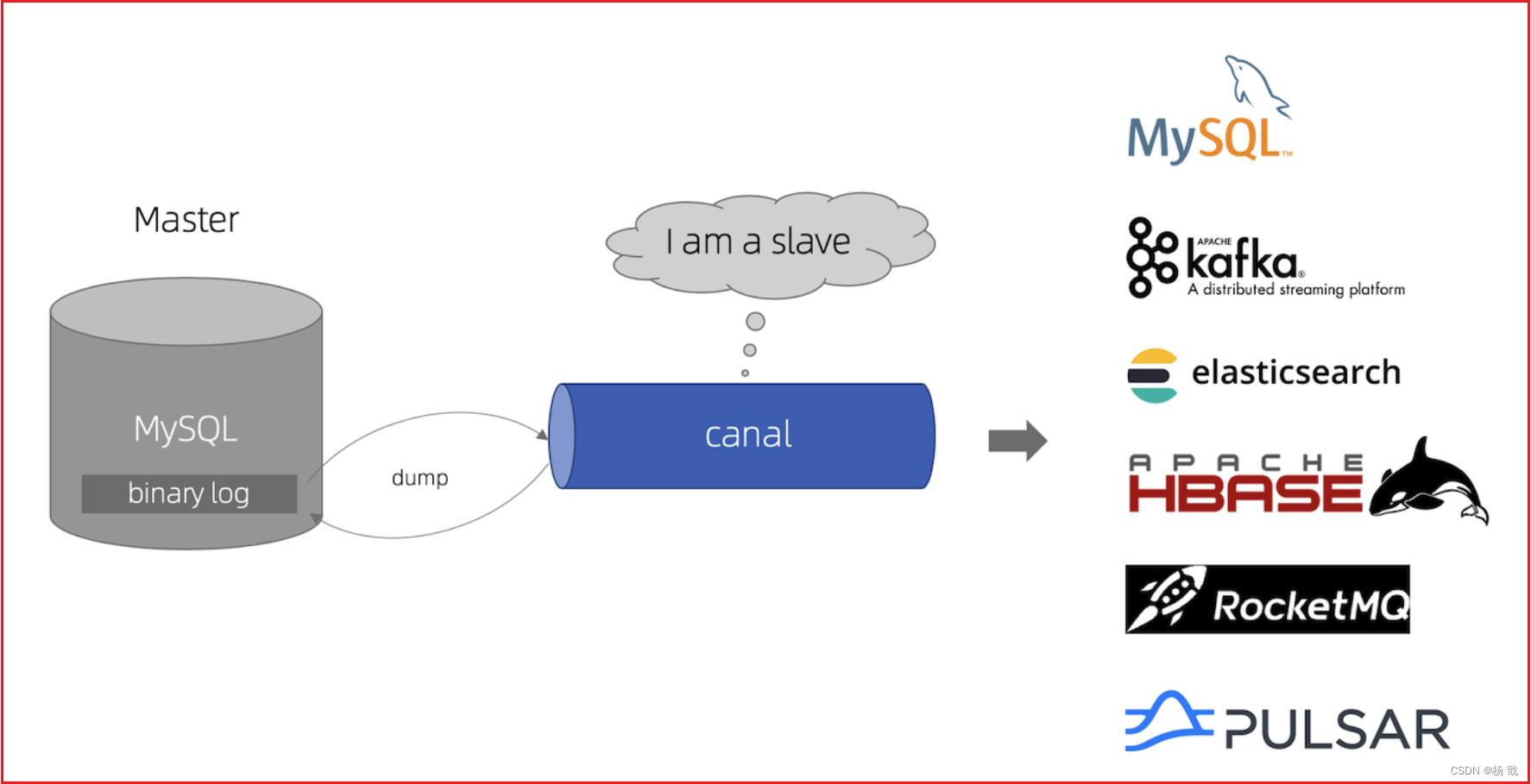
Canal介绍
canal主要用途是基于 MySQL 数据库增量日志解析,并能提供增量数据订阅和消费,应用场景十分丰富。
参考官方文档:
Canal应用场景
- 电商场景下商品、用户实时更新同步到至Elasticsearch、solr等搜索引擎;
- 价格、库存发生变更实时同步到redis;
- 数据库异地备份、数据同步;
- 代替使用轮询数据库方式来监控数据库变更,有效改善轮询耗费数据库资源。
Canal原理
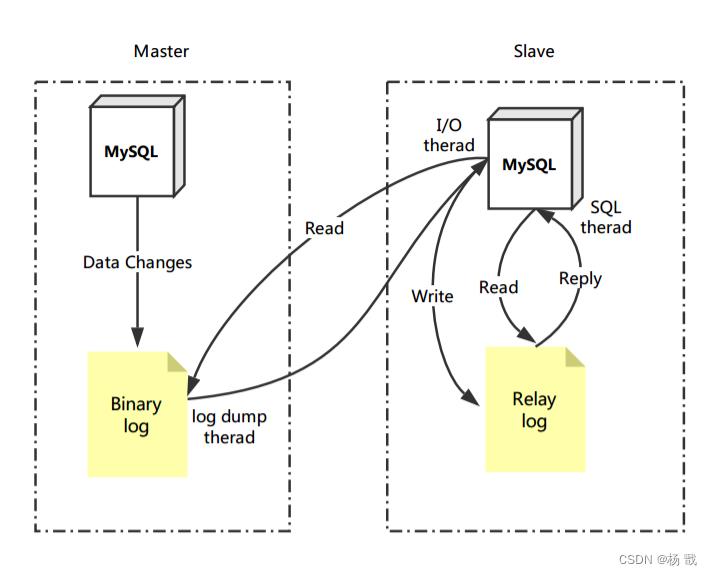
Canal的工作原理与MySQL主从复制原理类似,首先我们来回顾下MySQL主从复制的原理:
MySQL主从复制原理
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
Canal工作原理
Canal则是把自己伪装成 slave 节点与master进行交互
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)

Canal安装
参考文档:https://github.com/alibaba/canal/wiki/QuickStart
步骤1:MySQL Bin-log开启
1)MySQL开启bin-log
a.进入mysql容器
docker exec -it -u root mysql /bin/bash
b.开启mysql的binlog
cd /etc/mysql/mysql.conf.d
在mysqld.cnf最下面添加如下配置
# 开启 binlog
log-bin=/var/lib/mysql/mysql-bin
# 选择 ROW 模式
binlog-format=ROW
# 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
server-id=12345
c.创建账号并授权
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant:
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
d.重启mysql
docker restart mysql
开启bin-log后,我们可以用sql语句查看下:
show variables like '%log_bin%'
效果如下:

步骤2:Canal安装
1)拉取镜像
docker pull canal/canal-server:v1.1.1
2)安装容器
a.安装canal-server容器
docker run -p 11111:11111 --name canal -d docker.io/canal/canal-server
b.配置canal-server
修改/home/admin/canal-server/conf/canal.properties,将它的id属性修改成和mysql数据库中server-id不同的值,如下图:

c.修改/home/admin/canal-server/conf/example/instance.properties,配置要监听的数据库服务地址和监听数据变化的数据库以及表,修改如下:


指定监听数据库表的配置如下canal.instance.filter.regex:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\\\..*
2. canal schema下所有表: canal\\\\..*
3. canal下的以canal打头的表:canal\\\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用:canal\\\\..*,mysql.test1,mysql.test2 (逗号分隔)
注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
3)重启canal:
docker restart canal
以上是关于系统重构数据同步利器之Canal实战篇的主要内容,如果未能解决你的问题,请参考以下文章
实战 | MySQL Binlog通过Canal同步HDFS
ElasticSearch实战(四十七)-Canal 实现 MySQL 数据实时同步方案
实战 | canal 实现Mysql到Elasticsearch实时增量同步