实战 | canal 实现Mysql到Elasticsearch实时增量同步
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战 | canal 实现Mysql到Elasticsearch实时增量同步相关的知识,希望对你有一定的参考价值。
题记
关系型数据库mysql/Oracle增量同步Elasticsearch是持续关注的问题,也是社区、QQ群等讨论最多的问题之一。 问题包含但不限于: 1、Mysql如何同步到Elasticsearch? 2、Logstash、kafka_connector、canal选型有什么不同,如何取舍? 3、能实现同步增删改查吗? ..... 本文给出答案。
1、Canal同步
1.1 canal官方已支持Mysql同步ES6.X
同步原理,参见之前: 干货 | Debezium实现Mysql到Elasticsearch高效实时同步。
canal 1.1.1版本之后, 增加客户端数据落地的适配及启动功能。canal adapter 的 Elastic Search 版本支持6.x.x以上。 需要借助adapter实现。
1.2 同步效果
1)已验证:仅支持增量同步,不支持全量已有数据同步。这点,canal的初衷订位就是“阿里巴巴mysql数据库binlog的增量订阅&消费组件”。
2)已验证:由于采用了binlog机制,Mysql中的新增、更新、删除操作,对应的Elasticsearch都能实时新增、更新、删除。
3)推荐使用场景 canal适用于对于Mysql和Elasticsearch数据实时增、删、改要求高的业务场景。 实时场景要求不高的业务场景,logstashinputjdbc也能满足。
建议,做好选型甄别。
2、同步版本:
- ES:6.6.1
- Mysql: 5.7.25
- canal:v1.1.3-alpha-2
- canal-adapter:v1.1.3-alpha-2
- canal下载地址:https://github.com/alibaba/canal/releases
3、同步步骤解读
3.1 启动canal,可作为常驻进程后台运行。
官网已有详细描述https://github.com/alibaba/canal/wiki/QuickStart, 以下仅列举关键注意事项。
对应下载文件:canal.deployer-1.1.3-SNAPSHOT.tar.gz, 可以实时关注最新版本。
3.1.1 启用binlog
canal的原理是基于mysql binlog技术,所以这里一定需要开启mysql的binlog写入功能,建议配置binlog模式为row.
[mysqld]
log-bin=mysql-bin #添加这一行就ok
binlog-format=ROW #选择row模式
server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复3.1.2 修改配置文件
vi conf/example/instance.properties配置数据库基本信息。
3.1.3 启动canal
bin/startup.sh可通过日志排查错误。
3.2 配置ElasticSearch适配器,并实现同步。
官网已有详细描述:https://github.com/alibaba/canal/wiki/Sync-ES。 以下仅针对部署遇到的坑做描述。
3.2.1 部署版本
anal.adapter-1.1.3-SNAPSHOT.tar.gz,如有更新,建议使用最新版本。
3.2.2 核心配置
[root@localhost es]# cat mytest_user.yml
dataSourceKey: defaultDS
destination: example
esMapping:
_index: baidu_index
_type: _doc
_id: _id
pk: id
sql: "select a.id as _id, a.title, a.url, a.publish_time, a.content,
from baidu_info as a"
# objFields:
# _labels: array:;
etlCondition: "where a.id >= 1"
commitBatch: 3000实现目的:库表id字段作为Elasticsearch的_id,以期实现自增。
4、多表关联实现
建议参考官网:https://github.com/alibaba/canal/wiki/Sync-ES 支持:
- 一对一
- 一对多
- 多对多
5、坑
坑1:canal.adapter-1.1.2 启动失败
启动失败:https://github.com/alibaba/canal/issues/1513 该问题在1.1.3版本已经修复。
坑2:不支持全量同步
全量同步建议使用logstash或者其他工具:
坑3:必须先在ES创建好对应索引的Mapping
否则,会没有识别索引,会报写入错误。
坑4:多张表的同步如何实现?
在canal.adapter-1.1.3/conf/es的新增*.yml配置即可。 也就是说,可以一张Mysql表一个配置文件。
坑5:空指针异常错误
解决方案:sql语句部分,指定对应库表id为ES中的_id,否则会报错。 举例:
select sx_sid as _id, name from baidu_info坑6:基于 row 模式的 binlog 会不会记录变更前、变更后的值呢?
- INSERT:只有变更后的值。
- UPDATE:包含了变更前、变更后的值。
- DELETE:变更前的值
关于全量同步:https://github.com/alibaba/canal/issues/376
6 同步选型小结
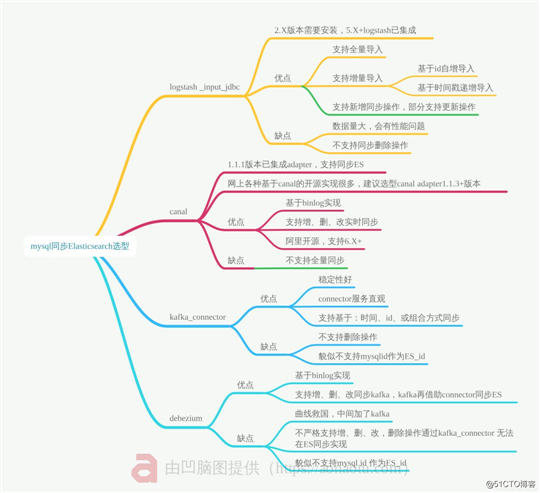
以上不同选型各有利弊,建议 结合实际业务斟酌选择。 欢迎留下你的同步实践方案和思考。

加入星球,和大佬一起沉淀技术!
以上是关于实战 | canal 实现Mysql到Elasticsearch实时增量同步的主要内容,如果未能解决你的问题,请参考以下文章
ElasticSearch实战(四十七)-Canal 实现 MySQL 数据实时同步方案
ElasticSearch实战(四十七)-Canal 实现 MySQL 数据实时同步方案
实战 | MySQL Binlog通过Canal同步HDFS